
从零开始学昇腾Ascend C算子开发-第十五篇:核函数直调动态输入
本文对比了核函数直调与框架调用在动态输入处理上的差异。在框架调用方式中,框架自动处理动态输入的打包和传递;而核函数直调需要手动构造ListTensorDesc数据结构,包括维度、索引、形状等信息,并管理内存分配和拷贝。文章详细介绍了ListTensorDesc的数据结构定义与内存布局,以及Host端如何构造该结构并拷贝到Device端。核函数直调虽然增加了代码复杂度,但提供了更大的灵活性。
15.1 核函数直调 vs 框架调用
AddN算子实现了两个数据相加,返回相加结果的功能,其中核函数的输入参数为动态输入,动态输入参数包含两个入参,x和y。
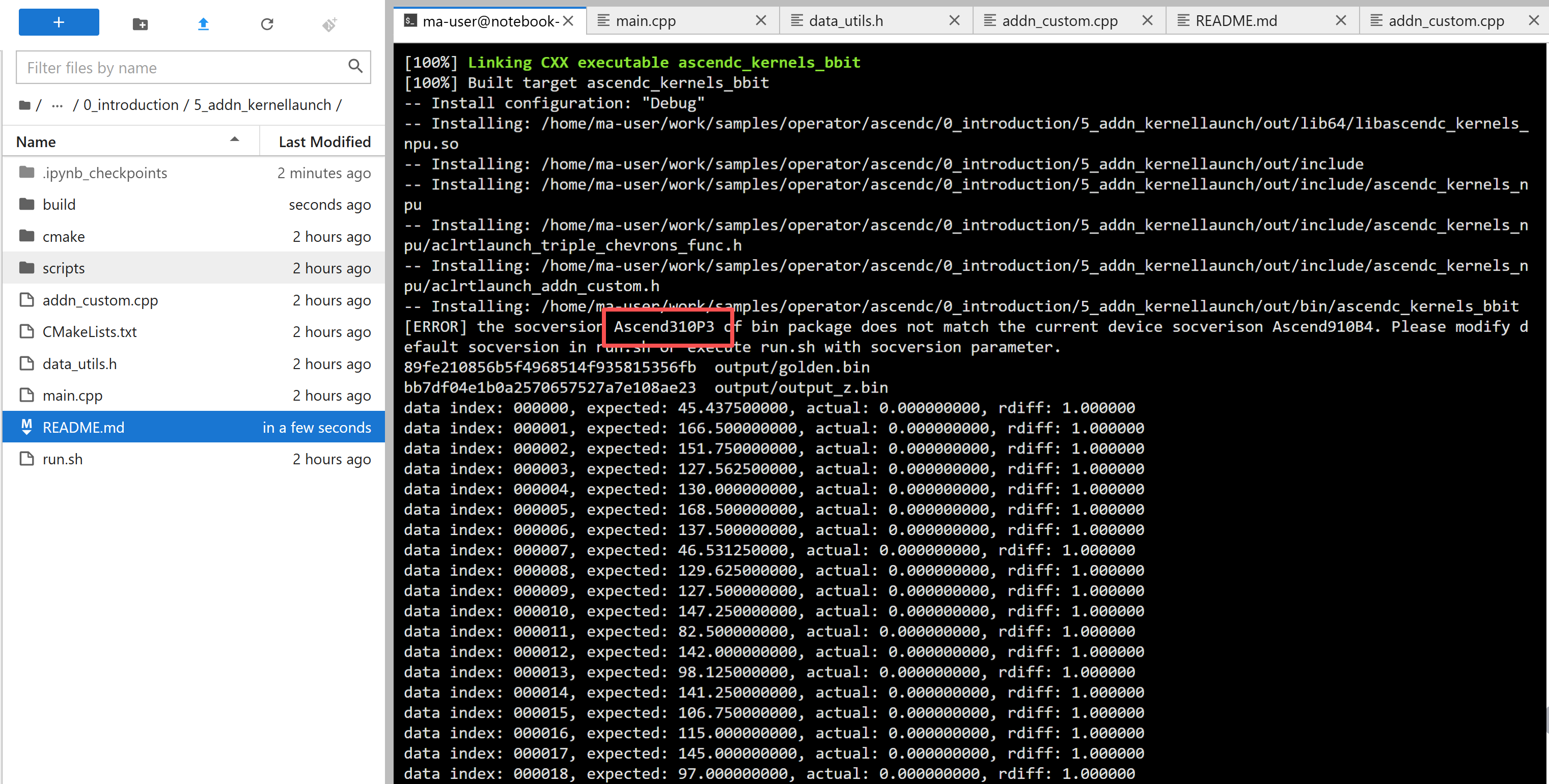
默认的是310P的,每次都得改啊。
不然后面就会报错。
运行语句,这里是区分大小写的,所以-v后面必须是Ascend910B:
bash run.sh -r npu -v Ascend910B
15.1.1 动态输入处理的差异
在框架调用方式(4_addn_frameworklaunch)中,框架会自动处理动态输入的打包和传递。但在核函数直调方式(5_addn_kernellaunch)中,需要手动构造和传递动态输入列表。
框架调用方式:
- 框架自动将多个输入打包成动态输入列表
- 框架自动处理ListTensorDesc的构造
- 开发者只需要调用API,不需要关心底层细节
核函数直调方式:
- 需要手动构造ListTensorDesc数据结构
- 需要手动将ListTensorDesc拷贝到Device端
- 需要手动管理内存和数据结构
15.1.2 为什么需要手动处理
核函数直调绕过了框架层,直接调用Kernel函数,所以框架提供的自动处理功能不可用。开发者需要自己实现这些功能,包括:
- 构造动态输入列表的数据结构
- 管理内存分配和拷贝
- 处理数据对齐和格式
虽然增加了代码复杂度,但也提供了更大的灵活性。
15.2 ListTensorDesc数据结构
15.2.1 数据结构定义
在核函数直调方式中,需要手动定义ListTensorDesc数据结构:
// Tensor描述结构
constexpr uint32_t SHAPE_DIM = 2; // 形状维度
struct TensorDesc {
uint32_t dim{SHAPE_DIM}; // 维度数
uint32_t index; // tensor在列表中的索引
uint64_t shape[SHAPE_DIM]; // 形状数组
};
// 列表Tensor描述结构
constexpr uint32_t TENSOR_DESC_NUM = 2; // tensor数量
struct ListTensorDesc {
uint64_t ptrOffset; // 指针偏移量
TensorDesc tensorDesc[TENSOR_DESC_NUM]; // tensor描述数组
uintptr_t dataPtr[TENSOR_DESC_NUM]; // tensor数据指针数组
};
TensorDesc:描述单个tensor的元信息,包括维度、索引、形状。
ListTensorDesc:描述整个动态输入列表,包括所有tensor的描述和数据指针。
15.2.2 数据结构的布局
ListTensorDesc在内存中的布局:
ListTensorDesc:
├── ptrOffset (uint64_t) // 偏移量
├── tensorDesc[0] (TensorDesc) // 第0个tensor的描述
│ ├── dim (uint32_t)
│ ├── index (uint32_t)
│ └── shape[SHAPE_DIM] (uint64_t[])
├── tensorDesc[1] (TensorDesc) // 第1个tensor的描述
│ ├── dim (uint32_t)
│ ├── index (uint32_t)
│ └── shape[SHAPE_DIM] (uint64_t[])
└── dataPtr[TENSOR_DESC_NUM] (uintptr_t[]) // 数据指针数组
ptrOffset的计算公式:
ptrOffset = (1 + (1 + SHAPE_DIM) * TENSOR_DESC_NUM) * sizeof(uint64_t)
这个偏移量用于Kernel端解析数据结构。
15.3 Host端实现
15.3.1 构造ListTensorDesc
在main.cpp中,需要手动构造ListTensorDesc:
// 1. 定义Tensor描述
constexpr uint32_t SHAPE_DIM = 2;
struct TensorDesc {
uint32_t dim{SHAPE_DIM};
uint32_t index;
uint64_t shape[SHAPE_DIM] = {8, 2048};
};
// 2. 创建每个tensor的描述
TensorDesc xDesc;
xDesc.index = 0; // 第0个tensor
TensorDesc yDesc;
yDesc.index = 1; // 第1个tensor
// 3. 定义ListTensorDesc结构
constexpr uint32_t TENSOR_DESC_NUM = 2;
struct ListTensorDesc {
uint64_t ptrOffset;
TensorDesc tensorDesc[TENSOR_DESC_NUM];
uintptr_t dataPtr[TENSOR_DESC_NUM];
} inputDesc;
// 4. 分配Device内存
uint8_t *xDevice, *yDevice, *zDevice;
aclrtMalloc((void **)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void **)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void **)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 5. 拷贝数据到Device
aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
// 6. 构造ListTensorDesc
inputDesc = {
(1 + (1 + SHAPE_DIM) * TENSOR_DESC_NUM) * sizeof(uint64_t), // ptrOffset
{xDesc, yDesc}, // tensorDesc数组
{(uintptr_t)xDevice, (uintptr_t)yDevice} // dataPtr数组
};
15.3.2 拷贝ListTensorDesc到Device
ListTensorDesc本身也需要拷贝到Device端:
// 1. 在Device端分配内存
void *inputDescInDevice = nullptr;
aclrtMalloc((void **)&inputDescInDevice, sizeof(ListTensorDesc),
ACL_MEM_MALLOC_HUGE_FIRST);
// 2. 拷贝ListTensorDesc到Device
aclrtMemcpy(inputDescInDevice, sizeof(ListTensorDesc), &inputDesc,
sizeof(ListTensorDesc), ACL_MEMCPY_HOST_TO_DEVICE);
// 3. 调用Kernel
ACLRT_LAUNCH_KERNEL(addn_custom)(blockDim, stream, inputDescInDevice, zDevice);
15.3.3 完整流程
int32_t main(int32_t argc, char *argv[])
{
// 1. 初始化ACL
aclInit(nullptr);
aclrtSetDevice(deviceId);
aclrtCreateStream(&stream);
// 2. 分配Host和Device内存
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
aclrtMallocHost((void **)(&xHost), inputByteSize);
aclrtMallocHost((void **)(&yHost), inputByteSize);
aclrtMallocHost((void **)(&zHost), outputByteSize);
aclrtMalloc((void **)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void **)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void **)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 3. 读取输入数据
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
// 4. 拷贝数据到Device
aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
// 5. 构造ListTensorDesc
TensorDesc xDesc;
xDesc.index = 0;
TensorDesc yDesc;
yDesc.index = 1;
ListTensorDesc inputDesc = {
(1 + (1 + SHAPE_DIM) * TENSOR_DESC_NUM) * sizeof(uint64_t),
{xDesc, yDesc},
{(uintptr_t)xDevice, (uintptr_t)yDevice}
};
// 6. 拷贝ListTensorDesc到Device
void *inputDescInDevice = nullptr;
aclrtMalloc((void **)&inputDescInDevice, sizeof(ListTensorDesc),
ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMemcpy(inputDescInDevice, sizeof(ListTensorDesc), &inputDesc,
sizeof(ListTensorDesc), ACL_MEMCPY_HOST_TO_DEVICE);
// 7. 调用Kernel
ACLRT_LAUNCH_KERNEL(addn_custom)(blockDim, stream, inputDescInDevice, zDevice);
aclrtSynchronizeStream(stream);
// 8. 拷贝结果回Host
aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST);
WriteFile("./output/output_z.bin", zHost, outputByteSize);
// 9. 清理资源
aclrtFree(xDevice);
aclrtFree(yDevice);
aclrtFree(zDevice);
aclrtFree(inputDescInDevice);
// ...
}
15.4 Kernel端实现
15.4.1 解析ListTensorDesc
在Kernel中,需要使用ListTensorDesc类解析动态输入:
extern "C" __global__ __aicore__ void addn_custom(
GM_ADDR srcList, // 动态输入列表
GM_ADDR dst) // 输出
{
// 1. 初始化ListTensorDesc
// 参数:数据指针、数据大小、tensor数量
AscendC::ListTensorDesc listTensorDesc(
(reinterpret_cast<__gm__ void *>(srcList)),
(1 + (1 + SHAPE_DIM + 1) * TENSOR_DESC_NUM) * sizeof(uint64_t),
TENSOR_DESC_NUM);
// 2. 获取tensor的形状信息
uint64_t buf[SHAPE_DIM] = {0};
AscendC::TensorDesc<int32_t> tensorDesc;
tensorDesc.SetShapeAddr(buf);
listTensorDesc.GetDesc(tensorDesc, 0); // 获取第0个tensor的描述
// 3. 计算总长度
uint64_t totalLength = tensorDesc.GetShape(0) * tensorDesc.GetShape(1);
// 4. 获取每个tensor的数据指针
__gm__ uint8_t *x = listTensorDesc.GetDataPtr<__gm__ uint8_t>(0);
__gm__ uint8_t *y = listTensorDesc.GetDataPtr<__gm__ uint8_t>(1);
// 5. 使用获取的指针初始化Kernel
KernelAdd op;
op.Init(x, y, dst, totalLength);
op.Process();
}
15.4.2 ListTensorDesc API
初始化:
AscendC::ListTensorDesc listDesc(
(__gm__ void*)srcList, // 数据指针
size, // 数据大小
tensorCount); // tensor数量
获取tensor描述:
AscendC::TensorDesc<int32_t> tensorDesc;
tensorDesc.SetShapeAddr(buf);
listDesc.GetDesc(tensorDesc, index); // 获取指定索引的tensor描述
获取tensor数据指针:
__gm__ uint8_t *ptr = listDesc.GetDataPtr<__gm__ uint8_t>(index);
15.4.3 Kernel实现
Kernel实现和固定输入基本相同,只是数据来源不同:
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint64_t totalLength)
{
this->blockLength = totalLength / AscendC::GetBlockNum();
this->tileLength = this->blockLength / TILE_NUM / BUFFER_NUM;
xGm.SetGlobalBuffer((__gm__ half *)x + blockLength * AscendC::GetBlockIdx(),
blockLength);
yGm.SetGlobalBuffer((__gm__ half *)y + blockLength * AscendC::GetBlockIdx(),
blockLength);
zGm.SetGlobalBuffer((__gm__ half *)z + blockLength * AscendC::GetBlockIdx(),
blockLength);
// ...
}
__aicore__ inline void Process()
{
// 处理逻辑和固定输入相同
// ...
}
};
15.5 与框架调用的对比
15.5.1 Host端对比
框架调用方式:
// 框架自动处理,只需要调用API
aclnnAddnCustomGetWorkspaceSize(inputX, inputY, outputZ, ...);
aclnnAddnCustom(workspaceAddr, workspaceSize, executor, stream);
核函数直调方式:
// 需要手动构造ListTensorDesc
ListTensorDesc inputDesc = {...};
void *inputDescInDevice = nullptr;
aclrtMalloc(...);
aclrtMemcpy(...);
ACLRT_LAUNCH_KERNEL(addn_custom)(blockDim, stream, inputDescInDevice, zDevice);
15.5.2 Kernel端对比
框架调用方式:
// 使用简化的API
AscendC::ListTensorDesc keyListTensorDescInit((__gm__ void*)srcList);
GM_ADDR x = keyListTensorDescInit.GetDataPtr<__gm__ uint8_t>(0);
GM_ADDR y = keyListTensorDescInit.GetDataPtr<__gm__ uint8_t>(1);
核函数直调方式:
// 需要指定大小和数量
AscendC::ListTensorDesc listTensorDesc(
(reinterpret_cast<__gm__ void *>(srcList)),
(1 + (1 + SHAPE_DIM + 1) * TENSOR_DESC_NUM) * sizeof(uint64_t),
TENSOR_DESC_NUM);
__gm__ uint8_t *x = listTensorDesc.GetDataPtr<__gm__ uint8_t>(0);
__gm__ uint8_t *y = listTensorDesc.GetDataPtr<__gm__ uint8_t>(1);
15.5.3 优缺点对比
框架调用方式:
- 优点:代码简单,框架自动处理
- 缺点:灵活性低,需要框架支持
核函数直调方式:
- 优点:灵活性高,可以精确控制
- 缺点:代码复杂,需要手动管理
15.6 关键注意事项
15.6.1 内存对齐
ListTensorDesc数据结构需要正确对齐,ptrOffset的计算必须准确:
ptrOffset = (1 + (1 + SHAPE_DIM) * TENSOR_DESC_NUM) * sizeof(uint64_t)
这个公式考虑了:
- 1个ptrOffset字段
- 每个TensorDesc包含:1个dim + 1个index + SHAPE_DIM个shape值
- 所有字段都是uint64_t对齐
15.6.2 数据指针
dataPtr数组存储的是Device端的内存地址(uintptr_t),不是Host端地址。必须确保:
- 数据已经拷贝到Device端
- 使用Device端地址构造ListTensorDesc
- ListTensorDesc本身也要拷贝到Device端
15.6.3 形状一致性
动态输入列表中的所有tensor必须有相同的形状。如果需要支持不同形状,需要更复杂的处理逻辑。
15.6.4 内存管理
需要管理多个内存块:
- 每个输入tensor的Device内存
- 输出tensor的Device内存
- ListTensorDesc的Device内存
- Host端的内存(如果需要)
确保所有内存都正确分配和释放。
15.7 扩展:支持更多输入
15.7.1 支持3个输入
如果要支持3个输入,只需要修改TENSOR_DESC_NUM:
constexpr uint32_t TENSOR_DESC_NUM = 3; // 改为3
struct ListTensorDesc {
uint64_t ptrOffset;
TensorDesc tensorDesc[TENSOR_DESC_NUM];
uintptr_t dataPtr[TENSOR_DESC_NUM];
};
// 构造时添加第3个tensor
TensorDesc wDesc;
wDesc.index = 2;
ListTensorDesc inputDesc = {
(1 + (1 + SHAPE_DIM) * TENSOR_DESC_NUM) * sizeof(uint64_t),
{xDesc, yDesc, wDesc},
{(uintptr_t)xDevice, (uintptr_t)yDevice, (uintptr_t)wDevice}
};
15.7.2 支持可变数量输入
如果要支持可变数量输入,需要动态分配内存:
// 动态分配ListTensorDesc
uint32_t tensorCount = 3; // 运行时确定
size_t descSize = sizeof(uint64_t) +
sizeof(TensorDesc) * tensorCount +
sizeof(uintptr_t) * tensorCount;
void *inputDescInDevice = nullptr;
aclrtMalloc((void **)&inputDescInDevice, descSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 构造ListTensorDesc(需要手动计算偏移)
// ...
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
社区地址:https://www.hiascend.com/developer

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 11
11 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)