
从零开始学昇腾Ascend C算子开发-实战项目-第十一篇:极简算子开发
AddCustom是完整的算子工程,功能全面但结构复杂。AddCustomTiny是极简版本,只保留核心功能,代码更简洁,更适合学习和快速开发。
11.1 为什么需要极简版本

11.1.1 AddCustom vs AddCustomTiny
AddCustom是完整的算子工程,功能全面但结构复杂。AddCustomTiny是极简版本,只保留核心功能,代码更简洁,更适合学习和快速开发。
AddCustom的特点:
- 完整的目录结构(op_kernel、op_host、framework)
- 使用msOpGen工具生成工程框架
- 需要JSON描述文件
- 包含框架集成代码
- 有InferShape和InferDataType函数
- 使用宏定义Tiling数据结构
AddCustomTiny的特点:
- 极简的文件结构(只有3个源文件)
- 直接编写代码,不需要生成工具
- 不需要JSON描述文件
- 没有框架集成代码
- 使用默认的形状和类型推导
- 使用简单的struct定义Tiling数据
11.1.2 适用场景
AddCustomTiny适合这些场景:
快速学习:想快速理解算子开发的核心流程,不需要复杂的工程结构。
快速原型:需要快速验证算子功能,不想花时间配置复杂的工程。
简单算子:开发简单的element-wise算子,不需要复杂的框架集成。
新版本特性:CANN 8.3+提供了新的编译方式,AddCustomTiny展示了如何使用。
11.2 AddCustomTiny代码结构
11.2.1 文件结构
AddCustomTiny只有3个源文件,非常简洁:
AddCustomTiny/
├── add_custom_kernel.cpp // Kernel实现
├── add_custom_host.cpp // Host端实现(Tiling、算子注册)
├── add_custom_tiling.h // Tiling数据结构
└── CMakeLists.txt // 编译配置
相比AddCustom的复杂目录结构,AddCustomTiny把所有代码都放在根目录,一目了然。
11.2.2 Tiling数据结构
add_custom_tiling.h使用简单的struct定义:
#ifndef ADD_CUSTOM_TILING_H
#define ADD_CUSTOM_TILING_H
#include <cstdint>
struct AddCustomTilingData {
uint32_t totalLength; // 总数据长度
uint32_t tileNum; // Tile数量
};
#endif // ADD_CUSTOM_TILING_H
相比AddCustom使用的宏定义方式:
BEGIN_TILING_DATA_DEF(TilingData)
TILING_DATA_FIELD_DEF(uint32_t, totalLength);
TILING_DATA_FIELD_DEF(uint32_t, tileNum);
END_TILING_DATA_DEF;
AddCustomTiny的方式更直观,就是普通的C++ struct,不需要记住复杂的宏。
11.2.3 Host端实现
add_custom_host.cpp实现了Tiling函数和算子注册:
#include "add_custom_tiling.h"
#include "register/op_def_registry.h"
#include "tiling/tiling_api.h"
namespace optiling {
const uint32_t BLOCK_DIM = 8;
const uint32_t TILE_NUM = 8;
static ge::graphStatus TilingFunc(gert::TilingContext *context)
{
// 直接获取TilingData指针
AddCustomTilingData *tiling = context->GetTilingData<AddCustomTilingData>();
// 获取输入形状的总元素数
uint32_t totalLength = context->GetInputShape(0)
->GetOriginShape()
.GetShapeSize();
// 设置Block维度
context->SetBlockDim(BLOCK_DIM);
// 设置Tiling参数
tiling->totalLength = totalLength;
tiling->tileNum = TILE_NUM;
return ge::GRAPH_SUCCESS;
}
} // namespace optiling
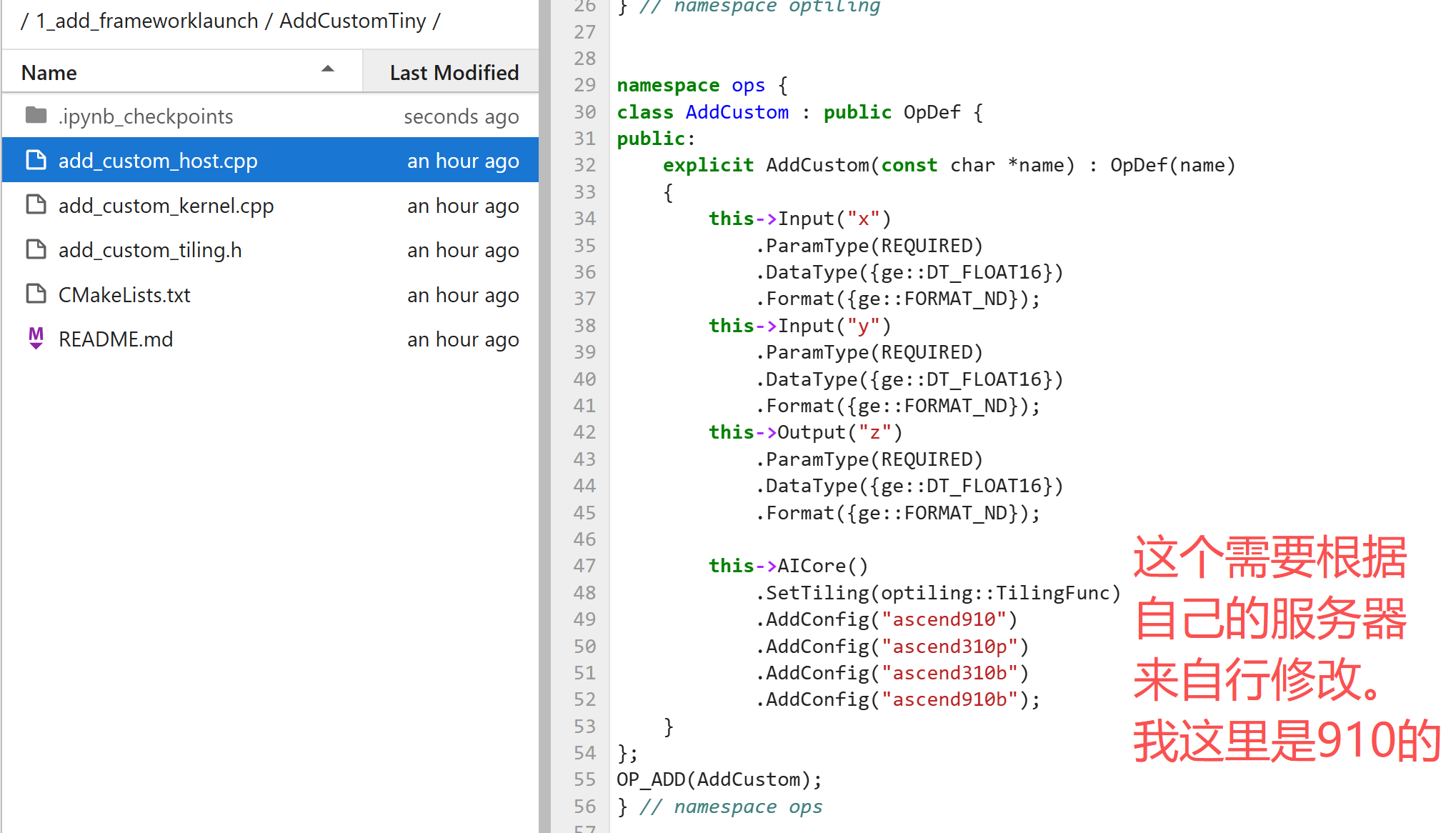
namespace ops {
class AddCustom : public OpDef {
public:
explicit AddCustom(const char *name) : OpDef(name)
{
// 定义输入输出
this->Input("x")
.ParamType(REQUIRED)
.DataType({ge::DT_FLOAT16})
.Format({ge::FORMAT_ND});
this->Input("y")
.ParamType(REQUIRED)
.DataType({ge::DT_FLOAT16})
.Format({ge::FORMAT_ND});
this->Output("z")
.ParamType(REQUIRED)
.DataType({ge::DT_FLOAT16})
.Format({ge::FORMAT_ND});
// 配置AI Core(注意:没有设置InferShape和InferDataType)
this->AICore()
.SetTiling(optiling::TilingFunc)
.AddConfig("ascend910")
.AddConfig("ascend310p")
.AddConfig("ascend310b")
.AddConfig("ascend910b");
}
};
OP_ADD(AddCustom);
} // namespace ops
关键差异:
-
Tiling函数更简单:直接使用
GetTilingData<AddCustomTilingData>()获取指针,不需要SaveToBuffer等操作。 -
没有InferShape和InferDataType:框架会自动推导,对于Add这种简单算子,输入输出形状和类型相同,不需要手动实现。
-
代码更少:去掉了不必要的函数,只保留核心功能。
11.2.4 Kernel实现
add_custom_kernel.cpp的Kernel实现和AddCustom基本相同,但有一个关键差异:
extern "C" __global__ __aicore__ void add_custom(
GM_ADDR x, GM_ADDR y, GM_ADDR z,
GM_ADDR workspace, GM_ADDR tiling)
{
// 注册Tiling数据类型
REGISTER_TILING_DEFAULT(AddCustomTilingData);
// 获取Tiling数据
GET_TILING_DATA(tilingData, tiling);
// 创建KernelAdd对象并执行
KernelAdd op;
op.Init(x, y, z, tilingData.totalLength, tilingData.tileNum);
op.Process();
}
REGISTER_TILING_DEFAULT宏:这是新版本提供的宏,用于注册Tiling数据类型。在AddCustom中,这个注册是在Tiling数据结构定义时通过REGISTER_TILING_DATA_CLASS完成的,AddCustomTiny把它移到了Kernel函数中。
11.3 新的编译方式
11.3.1 CMakeLists.txt对比
AddCustomTiny使用新的编译方式,CMakeLists.txt更简洁:
cmake_minimum_required(VERSION 3.16.0)
project(opp)
# 设置计算单元
set(ASCEND_COMPUTE_UNIT ascend910b)
# 查找ASC包
find_package(ASC REQUIRED)
# 创建算子包
npu_op_package(${vendor_name}
TYPE RUN
)
# 代码生成(自动生成aclnn API)
file(GLOB host_ops_srcs ${CMAKE_CURRENT_SOURCE_DIR}/add_custom_host.cpp)
npu_op_code_gen(
SRC ${host_ops_srcs}
PACKAGE ${vendor_name}
OUT_DIR ${ASCEND_AUTOGEN_PATH}
OPTIONS
OPS_PRODUCT_NAME ${ASCEND_COMPUTE_UNIT}
)
# 编译aclnn库
file(GLOB autogen_aclnn_srcs ${ASCEND_AUTOGEN_PATH}/aclnn_*.cpp)
set_source_files_properties(${autogen_aclnn_srcs} PROPERTIES GENERATED TRUE)
npu_op_library(cust_opapi ACLNN
${autogen_aclnn_srcs}
)
# 编译Tiling库
npu_op_library(cust_optiling TILING
${host_ops_srcs}
)
# 编译Kernel库
npu_op_kernel_library(ascendc_kernels
SRC_BASE ${CMAKE_SOURCE_DIR}/
TILING_LIBRARY cust_optiling
)
# 添加Kernel源文件
npu_op_kernel_sources(ascendc_kernels
OP_TYPE AddCustom
KERNEL_FILE add_custom_kernel.cpp
)
# 打包所有库
npu_op_package_add(${vendor_name}
LIBRARY
cust_opapi
cust_optiling
ascendc_kernels
)
11.3.2 新编译方式的特点
npu_op_code_gen:自动从Host端代码生成aclnn API。你只需要写算子注册代码,框架会自动生成aclnnAddCustom等API。
npu_op_library:分别编译不同类型的库:
cust_opapi:aclnn API库(ACLNN类型)cust_optiling:Tiling库(TILING类型)ascendc_kernels:Kernel库
npu_op_kernel_library:专门用于编译Kernel库,会自动处理Kernel编译的复杂配置。
npu_op_package_add:将所有库打包到算子包中。
11.3.3 编译流程
# 配置环境变量
export ASCEND_INSTALL_PATH=/usr/local/Ascend/ascend-toolkit/latest
source ${ASCEND_INSTALL_PATH}/bin/setenv.bash
export CMAKE_PREFIX_PATH=${ASCEND_INSTALL_PATH}/compiler/tikcpp/ascendc_kernel_cmake:$CMAKE_PREFIX_PATH
# 编译
rm -rf build && mkdir build && cd build
cmake .. && make -j binary package
编译完成后会生成:
custom_opp_*.run:算子安装包- 自动生成的
aclnn_add_custom.h等头文件
11.4 与AddCustom的详细对比
11.4.1 代码量对比
AddCustom:
- 多个文件,多个目录
- 包含框架集成代码
- 有InferShape和InferDataType函数
- 使用宏定义Tiling数据
AddCustomTiny:
- 只有3个源文件
- 没有框架集成代码
- 使用默认推导
- 使用简单struct
代码量减少约50%,更容易理解和维护。
11.4.2 功能对比
| 功能 | AddCustom | AddCustomTiny |
|---|---|---|
| Kernel实现 | ✓ | ✓ |
| Tiling函数 | ✓ | ✓ |
| 算子注册 | ✓ | ✓ |
| 形状推导 | 手动实现 | 自动推导 |
| 类型推导 | 手动实现 | 自动推导 |
| 框架集成 | TensorFlow插件 | 无 |
| 编译方式 | msOpGen + 传统CMake | 新CMake函数 |
| API生成 | 手动 | 自动 |
11.4.3 适用场景对比
使用AddCustom:
- 生产环境
- 需要框架集成(TensorFlow、PyTorch等)
- 需要自定义形状/类型推导
- 需要支持多种芯片的复杂配置
使用AddCustomTiny:
- 学习理解
- 快速原型
- 简单算子
- 只需要aclnn API调用
11.5 关键差异详解
11.5.1 Tiling数据结构定义
AddCustom方式(使用宏):
BEGIN_TILING_DATA_DEF(TilingData)
TILING_DATA_FIELD_DEF(uint32_t, totalLength);
TILING_DATA_FIELD_DEF(uint32_t, tileNum);
END_TILING_DATA_DEF;
REGISTER_TILING_DATA_CLASS(AddCustom, TilingData)
这种方式的好处是框架会自动处理序列化、对齐等细节,但需要记住宏的用法。
AddCustomTiny方式(使用struct):
struct AddCustomTilingData {
uint32_t totalLength;
uint32_t tileNum;
};
这种方式更直观,就是普通的C++ struct。在Kernel中使用REGISTER_TILING_DEFAULT宏注册。
11.5.2 Tiling函数实现
AddCustom方式:
static ge::graphStatus TilingFunc(gert::TilingContext *context)
{
TilingData tiling;
uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
context->SetBlockDim(BLOCK_DIM);
tiling.set_totalLength(totalLength);
tiling.set_tileNum(TILE_NUM);
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(),
context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
size_t *currentWorkspace = context->GetWorkspaceSizes(1);
currentWorkspace[0] = 0;
return ge::GRAPH_SUCCESS;
}
需要手动创建对象、设置值、保存到缓冲区。
AddCustomTiny方式:
static ge::graphStatus TilingFunc(gert::TilingContext *context)
{
AddCustomTilingData *tiling = context->GetTilingData<AddCustomTilingData>();
uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
context->SetBlockDim(BLOCK_DIM);
tiling->totalLength = totalLength;
tiling->tileNum = TILE_NUM;
return ge::GRAPH_SUCCESS;
}
直接获取指针,设置值即可,框架会自动处理序列化。
11.5.3 形状和类型推导
AddCustom方式:需要手动实现InferShape和InferDataType函数。
AddCustomTiny方式:框架自动推导。对于Add这种简单算子,输入输出形状和类型相同,框架可以自动推导。
如果算子的形状推导比较复杂,还是需要手动实现。
11.5.4 Kernel函数注册
AddCustom方式:Tiling数据在定义时通过REGISTER_TILING_DATA_CLASS注册。
AddCustomTiny方式:在Kernel函数中使用REGISTER_TILING_DEFAULT宏注册。
两种方式都可以,AddCustomTiny的方式更灵活,可以在Kernel函数中注册。
11.6 如何选择
11.6.1 选择AddCustom的情况
需要框架集成:如果你的算子需要在TensorFlow、PyTorch等框架中使用,需要框架插件代码。
复杂的形状推导:如果算子的输出形状不能简单推导,需要手动实现InferShape。
多种数据类型:如果需要支持多种数据类型,可能需要自定义InferDataType。
生产环境:生产环境通常需要完整的工程结构和错误处理。
11.6.2 选择AddCustomTiny的情况
快速学习:想快速理解算子开发的核心流程。
简单算子:开发element-wise、reduction等简单算子,形状推导简单。
快速原型:需要快速验证算子功能,不想配置复杂工程。
只需要aclnn API:如果只需要通过aclnn API调用,不需要框架集成。
11.6.3 从AddCustomTiny迁移到AddCustom
如果开始用AddCustomTiny开发,后来需要框架集成,可以:
- 添加framework目录和框架插件代码
- 添加InferShape和InferDataType函数(如果需要)
- 修改CMakeLists.txt使用msOpGen方式
- 添加JSON描述文件
Kernel代码基本不需要修改。
11.7 实践建议
11.7.1 学习路径
建议的学习路径:
- 先学AddCustomTiny:理解核心概念(Kernel、Tiling、算子注册)
- 再学AddCustom:理解完整的工程结构和框架集成
- 实际开发:根据需求选择合适的版本
11.7.2 开发建议
从简单开始:先用AddCustomTiny实现简单算子,验证流程。
逐步完善:如果需要框架集成或复杂功能,再迁移到AddCustom。
保持代码简洁:即使是AddCustom,也要保持代码简洁,避免过度设计。
充分利用自动推导:如果形状和类型推导简单,让框架自动处理。
11.7.3 常见问题
Q: AddCustomTiny支持哪些芯片?
A: 主要支持ascend910b(Atlas A2系列)。如果需要支持其他芯片,可以在AddConfig中添加。
Q: 能否在AddCustomTiny中添加框架集成?
A: 可以,但需要修改CMakeLists.txt和添加framework目录,不如直接用AddCustom。
Q: 自动生成的API在哪里?
A: 编译后会在${ASCEND_AUTOGEN_PATH}目录下生成aclnn_*.cpp和aclnn_*.h文件。
Q: 如何调试AddCustomTiny?
A: 调试方式和AddCustom相同,可以使用printf、DumpTensor等工具。
学习检查点
学完这一篇,你应该能做到这些:
理解AddCustomTiny的极简设计理念,知道什么时候用极简版本。掌握新的编译方式,能够使用npu_op_*函数编译算子。理解Tiling数据结构的两种定义方式,知道各自的优缺点。掌握自动推导机制,知道什么时候需要手动实现推导函数。能够根据需求选择合适的开发方式(AddCustom vs AddCustomTiny)。理解从AddCustomTiny迁移到AddCustom的方法。
实践练习
运行AddCustomTiny示例:在ModelArts Notebook中编译运行AddCustomTiny,理解极简版本的流程。
对比两个版本:仔细对比AddCustom和AddCustomTiny的代码,理解差异。
修改Tiling策略:修改TILE_NUM和BLOCK_DIM,观察对性能的影响。
实现其他算子:参考AddCustomTiny,实现Mul、Sub等简单算子。
添加数据类型支持:修改算子注册,支持float32类型。
理解自动生成:查看编译后自动生成的aclnn API代码,理解生成机制。
下一步:掌握了极简算子开发后,你已经能够快速开发简单算子了。可以继续学习更复杂的算子实现,或者学习性能优化技巧,提升算子的执行效率。也可以学习框架集成,将算子集成到TensorFlow、PyTorch等框架中。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
社区地址:https://www.hiascend.com/developer

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 7
7 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)