
【昇腾CANN训练营·算法篇】寻找消失的除法器:Newton Iteration 与高精度数学计算的艺术
摘要:2025年昇腾CANN训练营第二季提供0基础入门、开发者案例等专题课程,助力开发者提升算子开发技能,完成认证可获证书及奖品。在AI计算中,除法运算通过查表结合牛顿迭代法实现,将A/B转化为A×(1/B),相比直接硬件除法更高效。文章详解了达芬奇架构中SFU单元的工作原理,包括查表初值获取和牛顿迭代过程,并给出AscendC中的优化实践,如使用RSqrt指令加速LayerNorm运算。同时指出
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在通用 CPU 上,除法(Div)和开方(Sqrt)只是一条汇编指令的事。但在以 MAC(乘加运算)为核心的 AI Core Vector 单元中,硬件除法器是昂贵且低效的奢侈品。你调用的
Div接口,底层可能是一场复杂的数学接力。本文将揭示达芬奇架构下的 SFU (Special Function Unit) 工作机制,深度解析如何利用 Lookup Table (LUT) 配合 Newton-Raphson 迭代,在性能与精度之间跳出完美的平衡舞步。
前言:为什么除法比乘法慢 10 倍?
在算子性能分析中,新手常会发现一个现象:同样的形状,Mul 算子耗时 10us,而 Div 算子却要 50us 甚至更久。
难道是 NPU 的设计有缺陷? 并不是。在芯片设计领域,乘法器(Multiplier)容易做并行,但除法器(Divider)极其复杂且难以流水线化。 对于追求极致吞吐量的 AI Core 来说,浪费宝贵的晶体管去造一个全精度的硬件除法器是不划算的。
那么,Ascend C 里的 Div(dst, src1, src2) 到底发生了什么? 答案是:它把 $A / B$ 转换成了 $A \times (1/B)$。而计算 $1/B$(求倒数),靠的是**“猜”和“逼近”**。
一、 核心图解:从查表到迭代的精细加工
达芬奇架构处理非线性运算(Reciprocal, Sqrt, Exp, Log)通常遵循 “种子 + 迭代” 的模式。
-
Seed Generation (查表):硬件内部有一个极小的 ROM,存了一个查找表。对于输入 $x$,它能瞬间给出一个粗糙的初值 $y_0 \approx 1/x$。这个初值精度很低(比如只有 8 bit)。
-
Newton Iteration (迭代):利用牛顿-拉夫逊法(Newton-Raphson),通过几次乘加运算,让 $y_0$ 迅速逼近真实值。每一次迭代,有效精度位数大约翻倍。
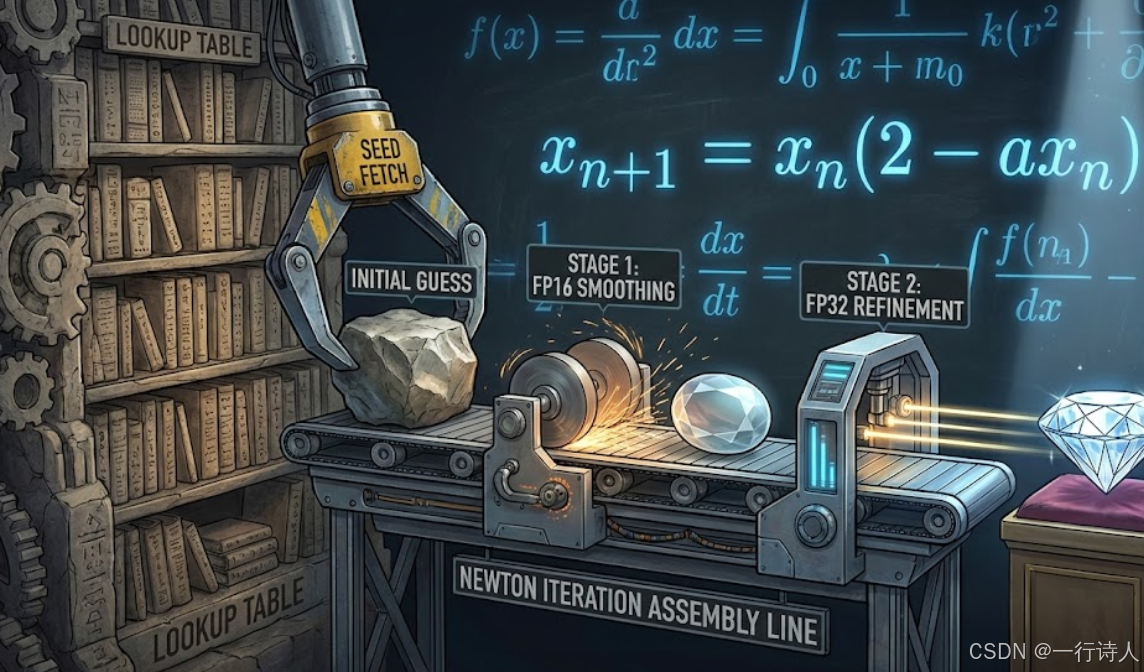
二、 算法原理:牛顿迭代法的魔法
对于求倒数 $y = 1/a$,我们构造函数 $f(y) = 1/y - a = 0$。 根据牛顿迭代公式 $y_{n+1} = y_n - \frac{f(y_n)}{f'(y_n)}$,代入后得到:
$$y_{n+1} = y_n \times (2 - a \times y_n)$$
这意味着,我们只需要用 乘法 (Mul) 和 减法 (Sub),就能算除法!
-
FP16 需求:通常查表后迭代 1 次,精度就能满足 fp16 (10 bit mantissa)。
-
FP32 需求:通常需要迭代 2-3 次,才能填满 23 bit 的尾数精度。
这就是为什么高精度除法慢的原因——它是用多条指令“凑”出来的。
三、 实战:Ascend C 中的指令级优化
Ascend C 为了支持这种模式,不仅仅提供了封装好的 Div,还暴露了底层的迭代指令,允许开发者根据业务场景牺牲精度换速度。
3.1 极速版:Reciprocal (1 Cycle)
如果你做训练时的梯度裁剪(Gradient Clipping),或者某些对精度不敏感的归一化,可以直接取近似倒数。
// 仅执行查表,精度约 8-bit,速度极快
Reciprocal(dst, src);
// 也就是 dst = 1 / src (approx)
Mul(final_result, A, dst); // A / B
3.2 标准版:NewtonIter (硬件加速)
Ascend C 甚至提供了一条专门的指令 NewtonIter 来加速迭代公式中的 $2 - a \times y_n$ 部分或者整个更新步。
// 假设 src = B
// 1. 获取初值 y0 = approx(1/B)
Reciprocal(y0, src);
// 2. 执行一次牛顿迭代
// 很多 Ascend 芯片提供了类似 NewtonIter 的指令
// 或者手动实现 y1 = y0 * (2 - src * y0)
// Ascend C 封装的 Div 内部会自动根据 dtype 决定迭代次数
Div(dst, A, B);
3.3 性能调优案例:LayerNorm 中的 RSqrt
LayerNorm 核心公式是 $\frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}$。这里涉及“求倒数平方根”(Reciprocal Sqrt)。 这是一个极其高频的操作。
-
低效写法:
Sqrt(tmp, var); // 开方 Div(res, x, tmp); // 除法 (包含求倒数迭代) -
高效写法: 利用
RSqrt指令(硬件直接支持 $1/\sqrt{x}$ 的查表和迭代)。// 直接算出 1/sqrt(var) RSqrt(tmp, var); Mul(res, x, tmp); // 乘法代替除法少了一次完整的迭代过程,性能提升显著。
四、 进阶:Exp 与 Log 的泰勒展开
除了除法,Exp(指数)和 Log(对数)也是 Vector 单元的硬骨头。 硬件通常无法直接计算 $e^x$。 Ascend C 底层通常采用 Remez 算法 或 泰勒级数展开(Taylor Series),将 $e^x$ 转化为多项式计算: $$ e^x \approx c_0 + c_1 x + c_2 x^2 + ... + c_n x^n $$ 这本质上是一堆 FMA (Fused Multiply-Add) 指令的堆叠。
优化启示: 如果你只需要计算 $e^x$ 的低精度版本(比如某些激活函数),或者 $x$ 的范围很小,你可以手写低阶泰勒展开来替代标准的 Exp 接口,从而获得几倍的性能提升。
五、 总结
在 Ascend C 开发中,不要把数学运算符看作理所当然。
-
除法是昂贵的:能用乘法(乘以倒数)就别用除法。
-
精度是可调的:了解
Reciprocal、RSqrt等近似指令的存在,在非关键路径上大胆使用近似值。 -
底层是迭代的:理解牛顿迭代原理,通过控制迭代次数,你可以自定义出特定精度要求的超高性能数学算子。
当你开始关心 Div 到底消耗了几个 Cycle,并尝试用 Mul + RSqrt 去替换它时,你就真正懂得了算力的代价。
本文基于昇腾 CANN 8.0 架构特性编写。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 6
6 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)