
【昇腾CANN训练营·同步篇】驾驭无序之马:深入解析 PipeBarrier 与指令流水的同步哲学
摘要:昇腾NPU的DaVinci架构采用全异步设计,Scalar单元快速发射指令,而Vector/Cube单元执行较慢,易引发RAW/WAR数据冒险。文章解析PipeBarrier机制,指出其仅暂停Scalar向指定管道发射新指令,而非阻塞所有单元。通过TQue队列管理大部分依赖,仅在跨管道交互、Scalar读写UB等场景需手动同步。强调过度同步会严重降低性能,建议信任TQue、延迟等待和批量同步
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在达芬奇架构中,Scalar 单元发射指令的速度远快于 Vector/Cube 单元执行指令的速度。这种全异步(Fully Asynchronous) 的设计带来了极致的吞吐量,但也引入了致命的 RAW (Read-After-Write) 和 WAR (Write-After-Read) 数据冒险。很多“玄学”Bug 的根源,就在于没有在关键时刻按下“暂停键”。本文将从硬件的 Scoreboard 机制切入,解析 PipeBarrier 的底层原理,教你如何在不扼杀性能的前提下,保证指令执行的时序正确性。
前言:你看到的顺序,不是硬件执行的顺序
在 CPU 编程中,我们习惯了“顺序一致性”:
a = 1;
b = a + 1; // 执行这行时,a 必然已经是 1 了
但在昇腾 NPU 上,Scalar 单元(指挥官)是负责发号施令的。
// Scalar 发射 MTE2 指令:搬运 A 到 UB
DataCopy(ub_a, gm_a, ...);
// Scalar 发射 Vector 指令:计算 B = A + 1
Add(ub_b, ub_a, ...);
Scalar 发射完 DataCopy 后,不会等待数据搬完,会立刻发射 Add 指令。 如果此时 DataCopy 还在路上(MTE2 比较慢),Vector 单元就会读取 ub_a 里的旧数据(垃圾数据)进行计算。 这就是经典的 RAW(写后读)冒险。
虽然 Ascend C 的 TQue 队列机制帮我们处理了绝大多数 MTE 与 Vector 之间的依赖,但在更复杂的 Scalar-Vector 交互 或 手动流水线控制 中,我们必须手动插入屏障。
一、 核心图解:五条并行的赛道
Da Vinci 架构内部有多个独立的执行管道(Pipe),它们并行工作,互不干扰:
-
PIPE_MTE2:GM -> UB/L1(搬入)
-
PIPE_MTE3:UB/L1 -> GM(搬出)
-
PIPE_V:Vector 计算
-
PIPE_C:Cube 计算
-
PIPE_S:Scalar 计算
没有任何同步措施时,这五条赛道上的赛车是各跑各的。Scalar 就像发令枪,瞬间响了 5 声,5 辆车同时冲出去。如果 Vector 赛车依赖 MTE2 赛车运来的燃料,它必须在路口等待。

二、 核心武器:PipeBarrier 的语义
Ascend C 提供了 PipeBarrier<DstPipe> 接口。很多文档只写了 API,没讲清楚它到底锁住了谁。
语义:PipeBarrier<PIPE_V>() 人话解释:阻挡 Scalar 继续向 PIPE_V 发射后续指令,直到 PIPE_V 之前所有的指令都执行完毕。
2.1 常见误区
误区:PipeBarrier 会暂停所有单元? 真相:不会。它只暂停 Scalar 向指定管道发射新指令。其他管道照常运行。
2.2 什么时候需要它?
通常 TQue 的 EnQue/DeQue 已经隐含了同步语义。但在以下场景必须手动处理:
-
Scalar 读取 UB 数据(Debug 场景)
DataCopy(ub_x, gm_x, ...); // MTE2 // 错误!此时 MTE2 还没搬完,Scalar 读到的是 0 // float val = ub_x.GetValue(0); // 正确: PipeBarrier<PIPE_MTE2>(); // 等 MTE2 搬完 float val = ub_x.GetValue(0); -
同一个 buffer 被多种用途复用 如果你先用 Vector 算了一个结果存入
ub_tmp,紧接着又用 MTE3 把ub_tmp搬走,虽然逻辑上看似串行,但为了保险起见(特别是绕过 TQue 直接操作 Tensor 时),显式的 Barrier 是安全带。
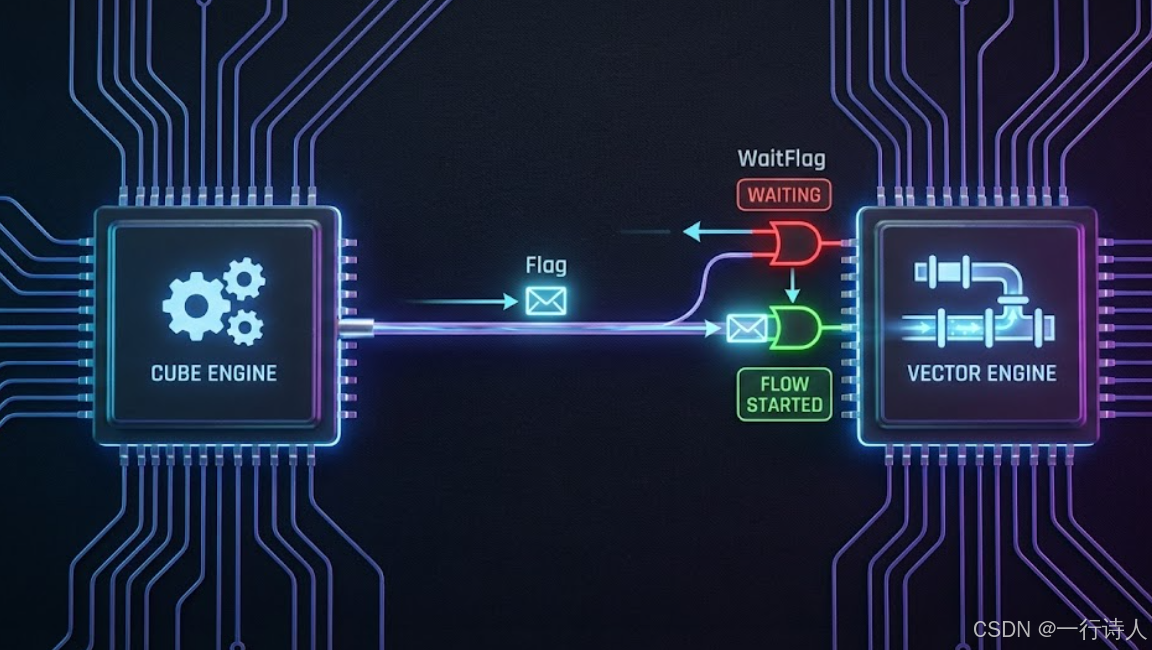
三、 进阶:SetFlag 与 WaitFlag 的“红绿灯”
PipeBarrier 是一种粗粒度的同步(Flush Pipeline),它要求前面的活全部干完。 如果我们想要更细粒度的控制,比如“任务 A 完成后通知任务 B”,就需要 Event Synchronization(事件同步)。
Ascend C 提供了 SetFlag 和 WaitFlag。
3.1 场景:Cube 与 Vector 的接力
假设 Cube 算完 MatMul 放在 L0C,需要 Vector 进行 ReLU。
// 1. Cube 管道:算完发出信号
MatMul(...);
SetFlag<PIPE_C, PIPE_V, EVENT_ID0>();
// 2. Vector 管道:等待信号
WaitFlag<PIPE_C, PIPE_V, EVENT_ID0>();
Relu(...);
这比 PipeBarrier 更高效,因为它只阻塞依赖链,不阻塞流水线上的其他无关指令。
深度思考:为什么 MatMul 高阶 API 不需要我们写这个? 因为 API 内部已经封装了这些 Flag 逻辑。但如果你在写底层算子(Level 0 API),必须手动管理这些红绿灯,否则数据就会发生踩踏。
四、 性能杀手:滥用同步
同步是性能的天敌。 每一次 PipeBarrier 或 WaitFlag,都意味着硬件流水线会出现 Stall(气泡)。
4.1 错误的“保姆式”编程
有些开发者为了求稳,在每一步操作后都加 Barrier:
CopyIn(...);
PipeBarrier<PIPE_MTE2>(); // 没必要!TQue 会处理
Compute(...);
PipeBarrier<PIPE_V>(); // 没必要!TQue 会处理
CopyOut(...);
这种代码会把 NPU 变成一个“串行单核 CPU”,性能只有理论值的 1/10。
4.2 优化原则
-
信任 TQue:只要是通过 Queue 管理的依赖,坚决不加 Barrier。
-
延迟等待:如果必须等待,尽量晚一点 Wait。让子弹多飞一会儿。
-
Batch Barrier:如果有一批无关的计算,等这一批都发完了,再加一个 Barrier。
五、 总结
指令同步是 Ascend C 开发中从“逻辑正确”走向“时序正确”的关键一步。
-
异步是常态:时刻记住 Scalar 发完指令不代表指令执行完了。
-
Queue 是主力:90% 的同步工作交给 TQue 完成。
-
Barrier 是特种兵:只在跨管道交互、Scalar 读写 Device 内存、或处理 Memory Consistency 时使用。
-
Flag 是微操:用于精细编排 Cube/Vector 并行流水。
当你能闭着眼睛画出指令在五条管道上的时序图,并精准地在冒险点插入唯一的那个 Barrier 时,你就真正驾驭了这匹“无序之马”。
本文基于昇腾 CANN 8.0 架构特性编写。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 20
20 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)