
【昇腾CANN训练营·微架构篇】被忽视的指挥官:Scalar 单元如何决定算子流水线的生死
摘要:2025年昇腾CANN训练营第二季推出系列课程,助力开发者提升算子开发技能,完成认证可获证书及华为奖品。本文聚焦AscendC算子开发中常被忽视的Scalar单元性能优化问题,揭示了控制流与计算流的解耦机制。文章分析了Scalar单元成为性能瓶颈的原因,指出复杂的标量计算会导致NPU流水线停顿,并提出三大优化方案:减少Vector与Scalar交互、预计算复杂运算、简化循环内计算。通过代码实
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在算子优化中,我们往往盯着 Vector 和 Cube 的利用率看,却忽略了 Scalar Unit(标量单元) 的负载。在达芬奇架构中,Scalar 单元不仅负责逻辑控制,还负责为所有计算单元发射指令。如果 Scalar 单元陷入复杂的地址计算或分支跳转,整个 NPU 的流水线就会发生 Dispatch Stall(发射停顿)。本文将揭示控制流与计算流的解耦机制,教你如何让指挥官“少干活,快发令”。
前言:最昂贵的“加减乘除”
在 CPU 编程中,计算数组下标 idx = i * stride + offset 是几乎零成本的操作。 但在 Ascend C 算子开发中,如果你在 for 循环里写了太复杂的标量计算:
// 危险的写法
for (int i = 0; i < n; i++) {
// 复杂的标量计算,用于生成 Vector 指令的参数
int offset = (i * A + B) % C;
DataCopy(dst[offset], ...);
}
你会发现算子性能极差。为什么? 因为 AI Core 的 Scalar 单元是整个系统的瓶颈。它既要处理循环跳转,要做标量运算,还要负责给 MTE、Vector、Cube 发射指令。如果它算 offset 慢了 1 个 Cycle,后面的 DataCopy 就要晚 1 个 Cycle 发射,累积下来就是巨大的流水线气泡。
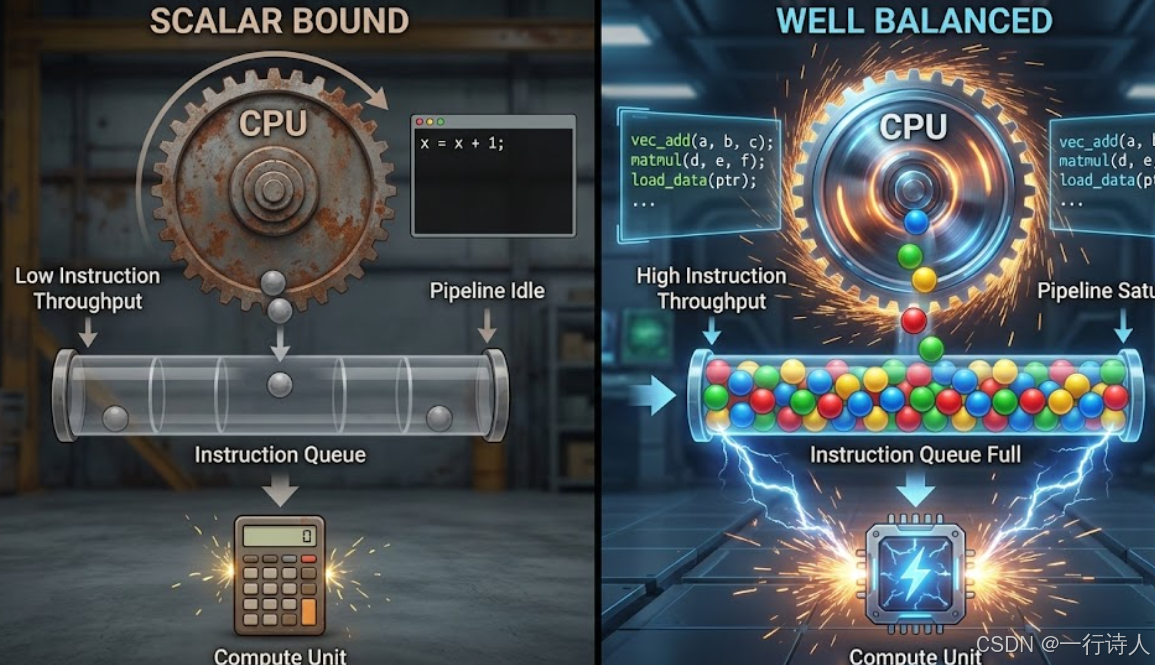
一、 核心图解:指挥官与三个兵团
Da Vinci 架构是一个典型的 异步指令流 架构。
-
Scalar Unit (SQ):大脑与指挥官。负责取指、译码、标量计算、发射指令。
-
Cube/Vector/MTE:三个兵团。它们有通过队列(Queue)接收来自 SQ 的指令。
理想状态:SQ 发令速度极快,指令队列塞满,三个兵团满负荷工作。 阻塞状态:SQ 被复杂的 if-else 或 int 运算卡住,指令队列空了,兵团停工等待。
这就是 Control-Bound(控制受限)。

二、 性能杀手一:Scalar 与 Vector 的频繁交互
这是新手最容易踩的坑:试图用 Scalar 读取 Vector 的计算结果来做判断。
// 极慢的交互
LocalTensor<half> vec = ...;
Add(vec, ...); // Vector 计算
half val = vec.GetValue(0); // 致命!Scalar 等待 Vector
if (val > 0) { ... }
原理解析
Vector 是异步执行的。当 Scalar 发出 Add 指令后,它以为 Add 已经做完了(其实还在排队)。 一旦调用 GetValue(),Scalar 被迫挂起(Stall),直到 Vector 流水线排空、数据写回、通过总线传输给 Scalar 寄存器。这不仅打断了并行,还引入了巨大的同步开销。
优化方案: 尽量避免数据从 Vector 流向 Scalar。如果必须要做条件判断,尝试使用 Vector 的 Select 指令或 Mask 机制在 Vector 内部闭环解决。
三、 性能杀手二:循环内的复杂下标计算
很多算子涉及复杂的 Tensor 寻址(如 Sliding Window, Dilated Conv)。 如果每次迭代都由 Scalar 实时计算偏移量,发射速度就会变慢。
3.1 预计算 (Pre-computation)
将复杂的标量计算移到 Host 侧 Tiling 阶段,或者在 Kernel 初始化阶段算好存入 UB。
3.2 标量转向量 (Scalar to Vector)
如果你需要生成一个 [0, 1, 2, ...] 的偏移量数组。
-
差评:Scalar 循环算,每次算一个填入。
-
好评:使用 Vector 的
ArithProgression(等差数列)指令,一次性生成 128 个偏移量,后续计算全部在 Vector 域内进行。
四、 代码实战:解耦控制流
场景:我们需要以 stride 为步长读取数据,但 stride 是动态变化的。
阻塞式写法 (Scalar Heavy)
// 每次循环,Scalar 都要做一次乘法和加法
// 导致 CopyIn 指令的发射间隔变大
for (int i = 0; i < loop; i++) {
uint64_t offset = i * stride_param + base_addr;
CopyIn(dst, src + offset, ...);
}
极速发射写法 (Loop Unrolling & Ptr Increment)
// 优化:将复杂的乘法转为简单的指针自增
// Scalar 只需要做简单的加法,指令发射极快
uint64_t current_addr = base_addr;
for (int i = 0; i < loop; i++) {
CopyIn(dst, current_addr, ...);
current_addr += stride_param; // 简单的 ALU 操作
}
甚至,如果 stride 是固定的,我们可以利用 Ascend C 的 DataCopy 自带的 Stride 参数(如上一篇所述),直接一条指令搞定,连 for 循环都省了。这样 Scalar 发射一条指令后就可以去休息了。
五、 总结
Scalar 单元是 AI Core 的节拍器。算子优化的最高境界,不仅是让 Vector 算得快,更是要让 Scalar “管得少”。
-
少交互:严控
GetValue,别让指挥官去搬砖。 -
降复杂度:循环里只做简单的自增自减,复杂的数学题留给 Host 做。
-
用指令替代循环:能用
Repeat和Stride解决的,绝不写for。
当你发现 Vector 利用率波动很大,且伴随着 Scalar 繁忙时,请检查一下:你的指挥官是不是在“微操”过度了?
本文基于昇腾 CANN 8.0 微架构原理编写。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 24
24 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)