
【昇腾CANN训练营·优化篇】刀尖上的舞蹈:深入理解 Atomic Add 原子操作与性能代价
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在并行计算的世界里,正确性永远是第一位的,其次才是性能。当 32 个 AI Core 同时向 Global Memory 的同一个地址写入梯度时,Race Condition(竞态条件)是必须跨越的鸿沟。Ascend C 提供了硬件级的 Atomic Add 支持,但它并非免费午餐。本文将从达芬奇架构的 L2 Cache 机制出发,解析原子操作的硬件实现原理,揭示其性能瓶颈,并提供“UB 聚合 + 延迟原子写”的优化范式。
前言:当并行遇到“独木桥”
在算子开发中,我们大部分时间都在追求“并行”——让每个 Core 互不干扰地算自己的数据。但在某些场景下,比如:
-
反向传播(Backward):多个样本的梯度需要累加到同一个权重梯度上。
-
Scatter/IndexAdd:根据索引将数据散列累加到目标 Tensor。
这时候,原本宽阔的并行高速公路变成了一座独木桥。如果 Core A 和 Core B 同时读取了地址 0x100 的值(假设为 0),各自加 1 后写回,最终结果是 1 而不是 2。这就是经典的 Write Conflict。
为了解决这个问题,Ascend 提供了 Atomic Add(原子累加) 机制。很多开发者认为只要开启了 SetAtomicAdd 就万事大吉,殊不知这往往是算子性能暴跌的开始。
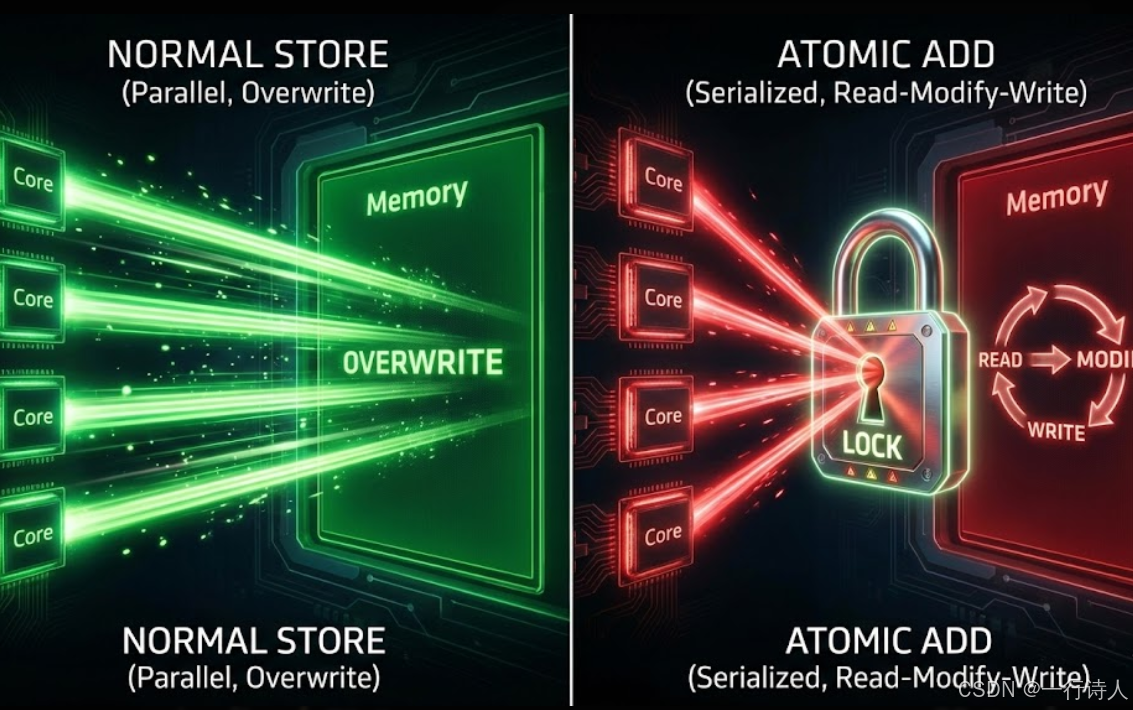
一、 核心图解:原子操作的“硬件代价”
在 Ascend 910B 上,原子操作并不是由 AI Core 内部的 Vector/Cube 单元完成的,而是下沉到了 L2 Cache 或者 DDR 控制器 附近的原子运算单元(Atomic ALU)。
普通写(Store):
-
Core 扔出数据 -> MTE3 搬运 -> 写入 L2/DDR(覆盖旧值)。
-
吞吐量:极高,流水线满载。
原子写(Atomic Add):
-
Core 发出原子指令 -> MTE3 搬运增量 -> L2 锁定地址行 -> 读取旧值 -> ALU 加法 -> 写入新值 -> 解锁。
-
吞吐量:受限于内存控制器的原子处理能力,且会因为**锁竞争(Lock Contention)**导致严重的流水线停顿。
二、 实战:Ascend C 中的原子开关
在 Ascend C 中,原子操作是作用于 Global Memory 的。我们无法在 UB(Unified Buffer)上做原子操作(因为 UB 是 Core 私有的),只能在写回 GM 时触发。
2.1 开启原子能力
在 Kernel 入口处或 Host Tiling 中,我们需要显式配置 GlobalTensor 的原子属性。
// Kernel 侧写法
__aicore__ inline void Process() {
// 1. 初始化 GlobalTensor
GlobalTensor<float> gm_grad;
gm_grad.SetGlobalBuffer(reinterpret_cast<__gm__ float*>(grad_addr));
// 2. 关键:开启原子加模式
// 之后的 DataCopyPad 或 CopyOut 操作,如果目标是 gm_grad,
// 底层 MTE3 会自动将 Store 指令替换为 Atomic Add 指令
gm_grad.SetAtomicAdd<float>();
// 3. 计算并写回
// 注意:这里搬运的不是"最终结果",而是"增量(Delta)"
DataCopy(gm_grad, ub_delta, dataSize);
}
2.2 常见误区
很多新手会写出这样的逻辑:
-
从 GM 读旧值
old_val到 UB。 -
在 UB 算
new_val = old_val + delta。 -
开启原子,把
new_val写回 GM。
错! 原子写回的是 增量(Delta),不是结果。如果你写回 new_val,硬件会执行 Memory = Memory + new_val,结果就飞了。 正确做法是:不要读旧值,直接算出增量,原子写回增量。
三、 性能陷阱:原子冲突风暴
假设有 32 个 Core,每个 Core 都要向 GM 的同一个地址 Addr_0 执行原子加。
-
理想并行:耗时
T。 -
原子串行:由于锁机制,这 32 个操作被迫在 L2 处排队串行执行。耗时变成
32 * T_atomic。
如果你的算子设计导致了高频热点冲突(Hotspot Contention),性能可能下降 10 倍以上。
诊断方法: 使用 msprof 查看 Timeline,如果发现 AI Core 利用率很低,而 MTE3 耗时极长且伴有大量的 Cache Miss 或 Memory Stall,大概率是原子冲突导致的。
四、 极致优化:UB 聚合 + 延迟原子写
解决原子性能问题的核心心法是:能私有解决的,绝不麻烦公家。 尽量在 UB 内部完成聚合,减少向 GM 发射原子指令的次数。
4.1 优化策略:Private Accumulation
假设我们要计算 Histogram(直方图),大量数据落入少量的 Bin 中。
低效做法: 每算出一个数据的 Bin Index,就立即向 GM 发射一次原子加。
高效做法 (Local Reduction):
-
在 UB 中申请一块 buffer 作为 Local Histogram。
-
遍历数据,先在 UB 的 Local Histogram 中进行累加(Vector 向量加法或 Scalar 循环加,速度极快且无锁)。
-
处理完一个 Batch 后,将 Local Histogram 的结果,一次性通过原子加写回 GM。
// 伪代码:优化后的直方图统计
void ComputeHistogram() {
// 1. 在 UB 初始化私有桶,清零
PipeBarrier<PIPE_VECTOR>();
Duplicate(ub_local_bins, 0.0f, bin_num);
// 2. 循环处理数据,先在 UB 累加
for (int i = 0; i < n; i++) {
int idx = indices[i];
// 这一步是 UB 内操作,极快,无竞争
ub_local_bins.SetValue(idx, ub_local_bins.GetValue(idx) + 1);
}
// 3. 最后一次性原子更新到 GM
gm_global_bins.SetAtomicAdd<float>();
DataCopy(gm_global_bins, ub_local_bins, bin_num);
}
通过这种方式,我们将 N 次原子写冲突,降低到了 CoreNum 次原子写冲突。
五、 深度思考:浮点数的“非结合律”
在使用原子加时,还有一个极易被忽略的精度陷阱。 浮点数加法不满足结合律:(A + B) + C != A + (B + C)。
在多核并行环境下,哪个 Core 先抢到锁写入 GM 是不确定的(由硬件仲裁决定)。 这意味着:即使输入数据完全一样,多次运行算子,原子累加的结果可能会有微小的 Bit 级差异。
-
对于训练场景,这种随机性通常是可以接受的(视为噪声)。
-
对于对齐验证场景(如与 PyTorch CPU 结果比对),这会导致
atol校验失败。
Ascend C 建议: 如果算法对确定性要求极高(Deterministic),请避免使用 Atomic Add,改用更复杂的 Sort + Reduce 算法或 多阶段 Tree Reduction,但这会牺牲大量性能。
六、 总结
原子操作是并行编程中“必要之恶”。
-
硬件观:Atomic Add 是昂贵的 L2/DDR 操作,不是廉价的寄存器操作。
-
设计观:Local Reduction First。在 UB 里把能加的都加完,最后再去冲撞 GM。
-
正确观:原子写的是 Delta,且浮点累加顺序不可控。
在 Ascend C 的世界里,克制地使用原子操作,才是算子性能起飞的关键。
本文基于昇腾 CANN 8.0 编写,硬件行为基于 Ascend 910B 架构分析。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 27
27 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)