
[嵌入式AI从0开始到入土]20_在Ascend上使用ComfyUI部署SD模型
本文介绍了在昇腾NPU上部署ComfyUI实现Stable Diffusion模型推理的完整教程。主要内容包括:1)ComfyUI的特点与优势,强调其节点式工作流和昇腾NPU原生支持;2)实测支持的模型列表(SDXL、SD3等),生图速度约20秒/张;3)详细的环境搭建指南,提供容器和源码两种安装方式;4)关键注意事项,如首次运行需图编译、不支持量化模型等。教程适合希望在昇腾平台实现AI图像生成的
[嵌入式AI从0开始到入土]嵌入式AI系列教程
注:等我摸完鱼再把链接补上
可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。
第1期 昇腾Altas 200 DK上手
第2期 下载昇腾案例并运行
第3期 官方模型适配工具使用
第4期 炼丹炉的搭建(基于Ubuntu23.04 Desktop)
第5期 炼丹炉的搭建(基于wsl2_Ubuntu22.04)
第6期 Ubuntu远程桌面配置
第7期 下载yolo源码及样例运行验证
第8期 在线Gpu环境训练(基于启智ai协作平台)
第9期 转化为昇腾支持的om离线模型
第10期 jupyter lab的使用
第11期 yolov5在昇腾上推理
第12期 yolov5在昇腾上应用
第13期_orangepi aipro开箱测评
第14期 orangepi_aipro小修补含yolov7多线程案例
第15期 orangepi_aipro欢迎界面、ATC bug修复、镜像导出备份
第16期 ffmpeg_ascend编译安装及性能测试
第17期 Ascend C算子开发
第18期 Ascend C算子开发环境(S5赛季)
第19期 vllm Ascend初体验
第20期 在Ascend上使用ComfyUI部署SD模型
未完待续…
文章目录
前言
昇腾(Ascend)是华为推出的一系列面向人工智能计算的专用处理器(NPU,Neural Processing Unit),旨在为深度学习训练和推理提供高性能、高能效的算力支持。昇腾系列芯片基于华为自研的达芬奇(DaVinci)架构,具备高并行、高吞吐、低功耗等优势,广泛应用于数据中心、边缘计算和终端设备等多种场景。
近年来,随着开源社区对国产 AI 硬件生态的关注提升,越来越多的第三方工具和框架(如 ComfyUI、Stable Diffusion WebUI 等)开始探索在昇腾 NPU 上的适配与优化。这不仅有助于降低对国外 GPU 的依赖,也为用户提供了更多元、更具性价比的 AI 推理部署选择。
ComfyUI 是一个基于节点(node-based)工作流的图形用户界面(GUI),专为运行和定制 Stable Diffusion 等扩散模型(diffusion models)而设计。它由社区开发者开发,因其高度模块化、灵活性强以及对高级用户友好的特性,在 AI 图像生成领域广受欢迎。ComfyUI 是目前最强大的 Stable Diffusion 前端之一。ComfyUI基于torch-npu实现昇腾原生支持,但是可能是笔者能力有限,调用双芯或者双卡都失败了,只能单卡单芯运行。如有大佬,欢迎指点迷津。
典型应用场景:
- AI 艺术创作
- 游戏/影视概念设计
- 电商产品图生成
- 学术研究与模型测试
- 自动化图像生成流水线
参考文献:
一、笔者测试过的模型
注意:似乎昇腾并不支持量化的sd模型,笔者努力了很久,也跑不起来,欢迎大佬执行一二。
| 模型名称 | 情况 |
|---|---|
| SDXL | OK |
| stable-diffusion-3-medium | OK |
| stable-diffusion-3.5-medium | OK |
以上三个模型512512分辨率的生图时间差不多都在20s/图左右。如果觉得慢,可以使用mindie sd去做,10241024分辨率,sd3模型差不多有15s/图的速度。
另外,第一次运行,需要进行图编译,如果cpu性能差,可能会导致生图时间非常长,笔者这边大概需要2分钟左右。后续只要不修改工作流中的参数,就会直接使用换成的算子直接运行。
二、环境准备
1. 准备本地NPU环境
硬件环境:Atlas 300I Inference series (Atlas 300I Duo)
软件环境:
- 使用docker环境,这里偷懒使用昇腾提供的mindie的环境,这样只需要拉取ComfyUI的源码和对应的模型就可以了:
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.1.RC1-300I-Duo-py311-openeuler24.03-lts
- 从新创建环境
- 从昇腾社区下载以下两个软件包。
Ascend-cann-toolkit_8.2.RC1_linux-x86_64.run Ascend-cann-kernels-310p_8.2.RC1_linux-x86_64.run- 安装CANN软件包(大概需要半个小时)
chmod +x Ascend=cann-* ./Ascend-cann-toolkit_8.2.RC1_linux-x86_64.run --install -q ./Ascend-cann-kernels-310p_8.2.RC1_linux-x86_64.run --install -q- 安装torch和torch_npu,torch-npu下载。
pip install torch==2.1.0 # aarch64环境 pip install torch==2.1.0 -i https://download.pytorch.org/whl/cpu # x86环境 pip install ./torch_npu-2.1.0.xxxx # 根据你下载的文件定- 后续步骤同容器安装。
2. 安装ComfyUI和依赖
- 执行下面的代码
git clone https://github.com/comfyanonymous/ComfyUI.git -b v0.3.65
cd ComfyUI
pip install -r requirements.txt -i https://mirrors.huaweicloud.com/repository/pypi/simple
- 检查torch版本(我是x86环境)
pip list | grep torch
mindietorch 2.1rc1+torch2.1.0.abi0
torch 2.1.0+cpu
torch-npu 2.1.0.post13.dev20250722
torchaudio 2.1.0+cpu
torchsde 0.2.6
torchvision 0.16.0+cpu
三、启动并配置ComfyUI
1. 启动ComfyUI
- 如果是昇腾跑的话,最后两个参数一定要带。
python3 main.py --listen 0.0.0.0 --port 8188 --auto-launch --disable-xformers --cpu-vae
- 使用浏览器访问运行ComfyUI的电脑的“ip:8188”,如“192.168.3.11:8188”,就可以看到下面的界面了。
2. 挑选模板和模型下载
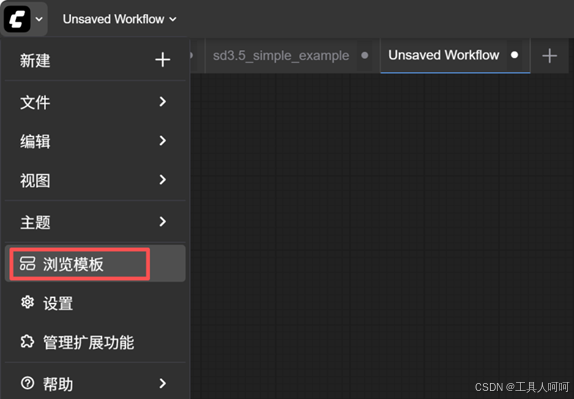
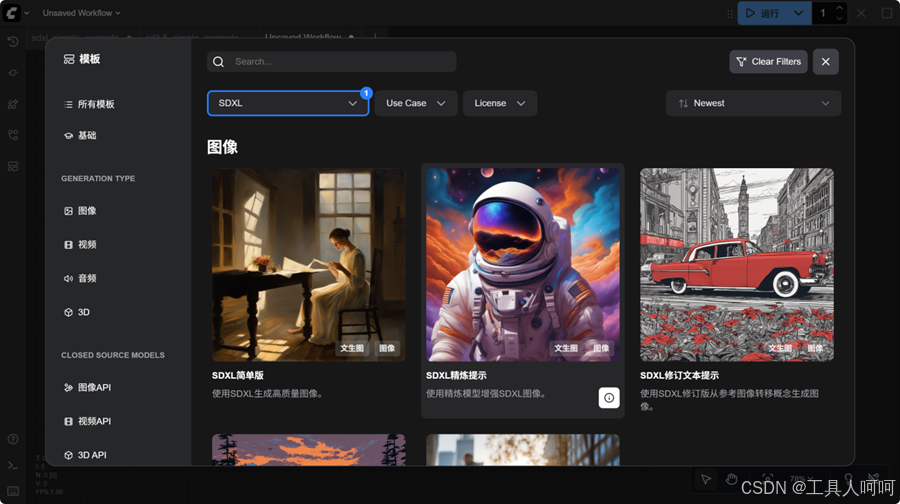
- 在左上角选择“浏览模板”,挑选一个模板打开。比如选择SDXL分类下的第一个模板。
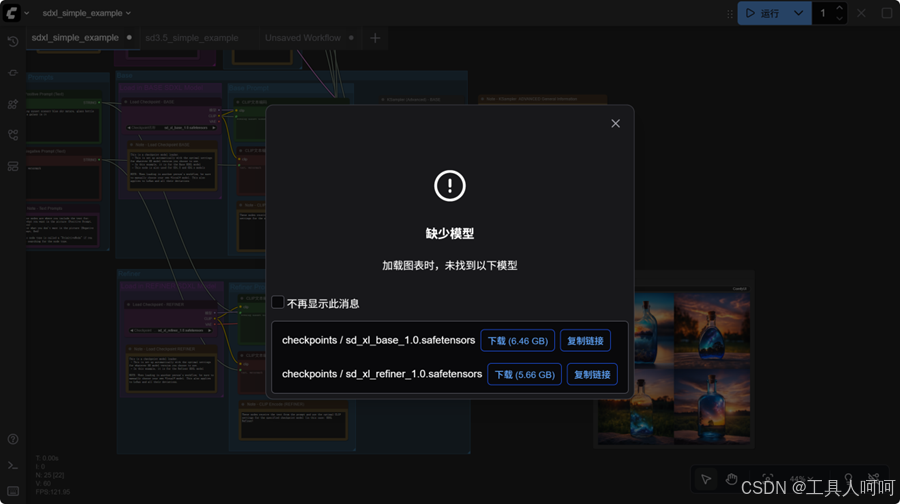
- 这里会跳出缺少模型的提示。如果可以访问huggingface,直接点击下载即可。如果不行,可以点击“复制链接”,将链接中的“huggingface.co”替换成“hf-mirror.com”,然后通过浏览器或者wget命令下载就可以了。
- 如果是自己单独下载的模型,那么需要将下载的模型放置到ComfyUI项目的models/checkpoints”目录下,然后在左侧的模型库中刷新,就可以看到刚刚下载的模型了。
四、模型配置
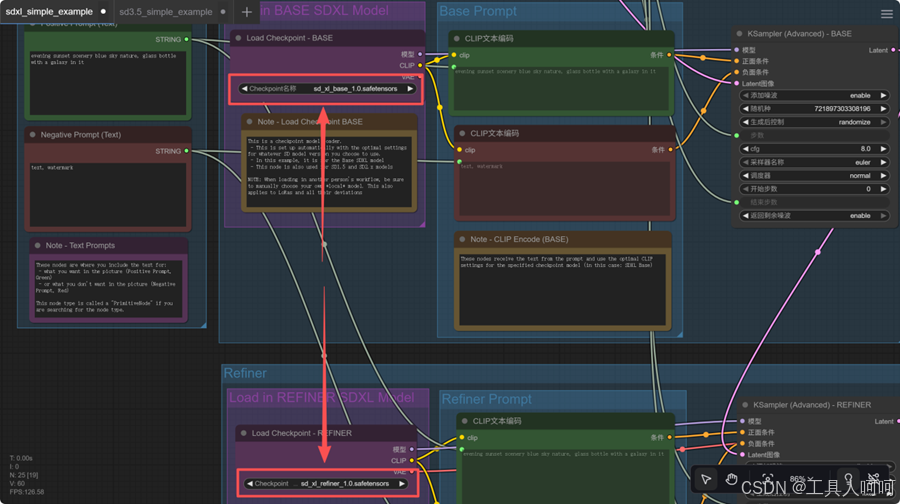
- 大部分模板(比如sdxl简单版)只需要修改模型权重路径,也就是下图所示的load checkpoint组件中的模型名称就可以直接run了。
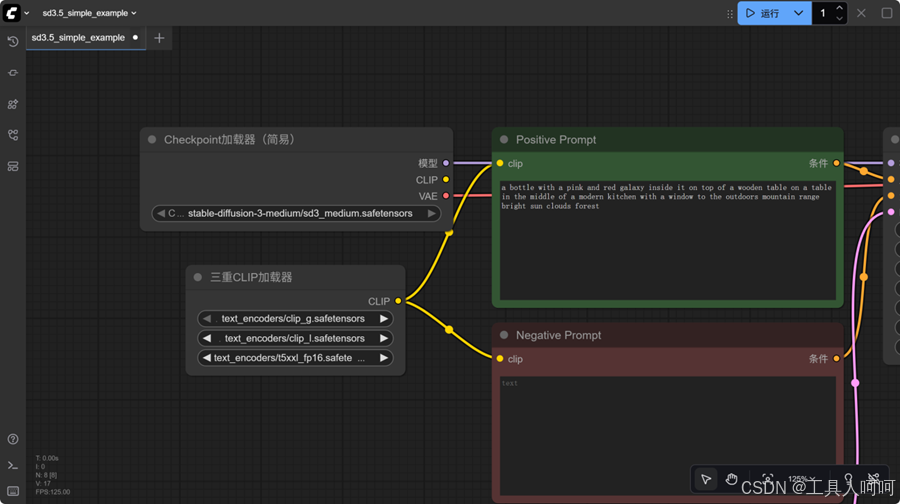
- sd3和sd3.5稍微麻烦一点,这里我使用的模板是“SD3.5简单版”。需要添加一个“三重CLIP加载器”去加载clip模型文件。
五、运行结果
点击右上角的运行按钮,等待几分钟,就可以得到图片。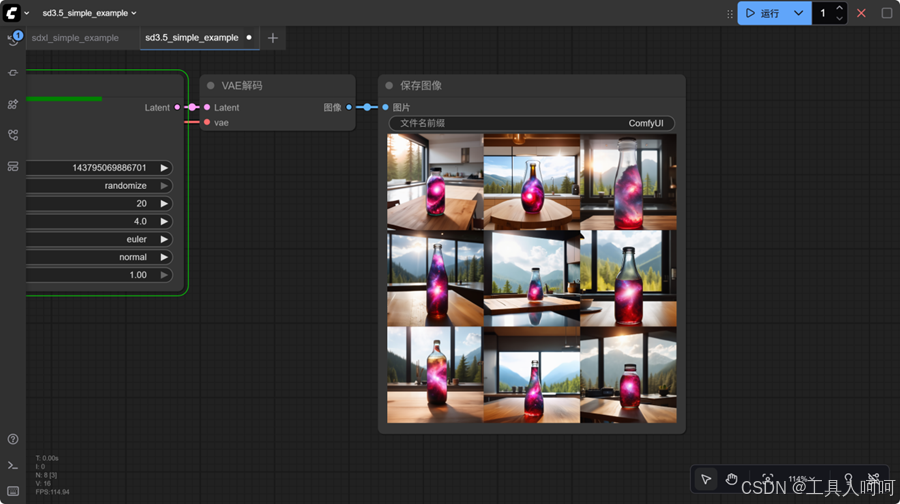
六、常见问题
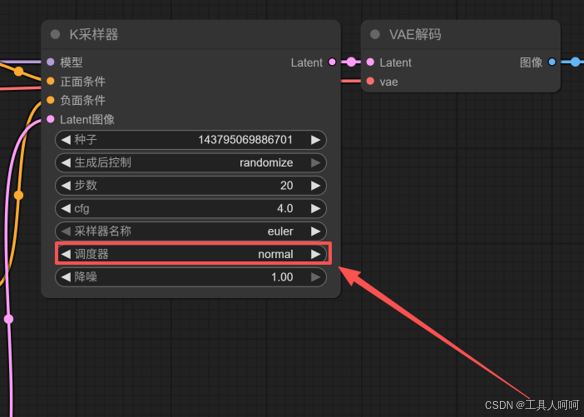
- 工作流运行到K采样器的时候报错,此问题笔者在“sd3.5简单版”模板中遇到了,也是查了很久,最后发现是昇腾不支持模板默认的调度器,修改为“normal”就可以了。
- sd系列的模型使用中文提示词的情况下,文生图效果很差,但是英文提示词非常准确。笔者查询资料发现,sd模型大部分使用英文prompt。最简单的解决办法就是直接使用英文提示词。
- 文生图效果很差,这种一般是提示词写的不行或者使用了中文提示词,笔者的解决方法很粗暴,让AI帮我优化一下提示词不就行了嘛。这里用vllm起了一个0.6B的模型,优化提示词足够了,速度也快,对出图的总时间影响很小。
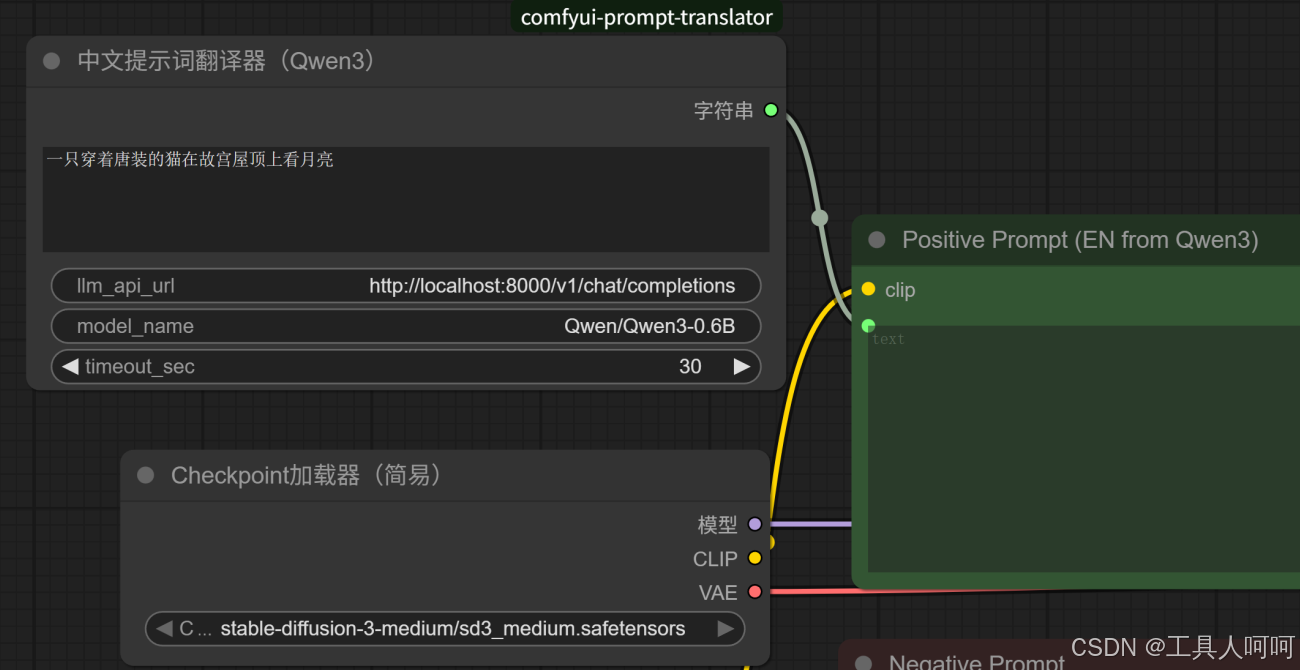
七、总结与后续改进方向
ComfyUI从使用上来说,已经大大的简化了sd模型的相关参数配置,我们要做的只是套用模板,修改参数,运行。通过图形化的界面,使得更多开发者能够轻易的上手使用。
后续改进可以基于以下几个方面去做:
- 修改工作流参数,添加新的工作流组件等,使得其可以直接通过自然语言生成所需的图片,例如结合语音输入实现更好的人机交互。
- 通过AI优化提示词节点,实现只需几个关键词,就可以生成原先几百字的prompt才能实现的效果。当然,这可能需要针对这个场景单独微调一个小参数量的模型,以实现快速prompt优化。
- ComfyUI是支持API调用的,其实就是一个json文件,我们在开发我们自己的应用的时候,只需要替换Positive Prompt或者Positive Prompt节点的内容,然后将新的json文件直接发送给服务器就可以了。后续使用python从服务器上接收生成的图片。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)