
vLLM-Ascend 部署与推理服务化实战
vLLM 是目前大模型推理领域最火热的高性能推理框架之一,以其 PagedAttention 技术著称。而 vLLM-Ascend 则是 vLLM 在华为昇腾 NPU 上的硬件插件,使得昇腾算力能够通过 vLLM 释放强大的推理性能。在真正开始做迁移之前,我原本以为 GPU 和 NPU 在推理框架上的适配会非常复杂,但上手后才发现,vLLM-Ascend 的设计思路非常清晰:它在底层为昇腾补齐了算
一、前言
vLLM 是目前大模型推理领域最火热的高性能推理框架之一,以其 PagedAttention 技术著称。而 vLLM-Ascend 则是 vLLM 在华为昇腾 NPU 上的硬件插件,使得昇腾算力能够通过 vLLM 释放强大的推理性能。
在真正开始做迁移之前,我原本以为 GPU 和 NPU 在推理框架上的适配会非常复杂,但上手后才发现,vLLM-Ascend 的设计思路非常清晰:它在底层为昇腾补齐了算子、调度和内存管理,让我几乎不需要改动任何推理逻辑,就能把原本跑在 GPU 上的模型直接迁移到昇腾上运行。实际体验下来,无论是吞吐、并发还是长上下文处理能力,昇腾在 vLLM 的调度机制配合下都能发挥出非常可观的性能。
那么接下来的话我也会带大家来进行一系列的实战操作。
开源仓地址:https://gitcode.com/gh_mirrors/vl/vllm-ascend
下载方式也非常简单,直接使用git拉取就行了:
二、vLLM-Ascend 环境部署与基础配置
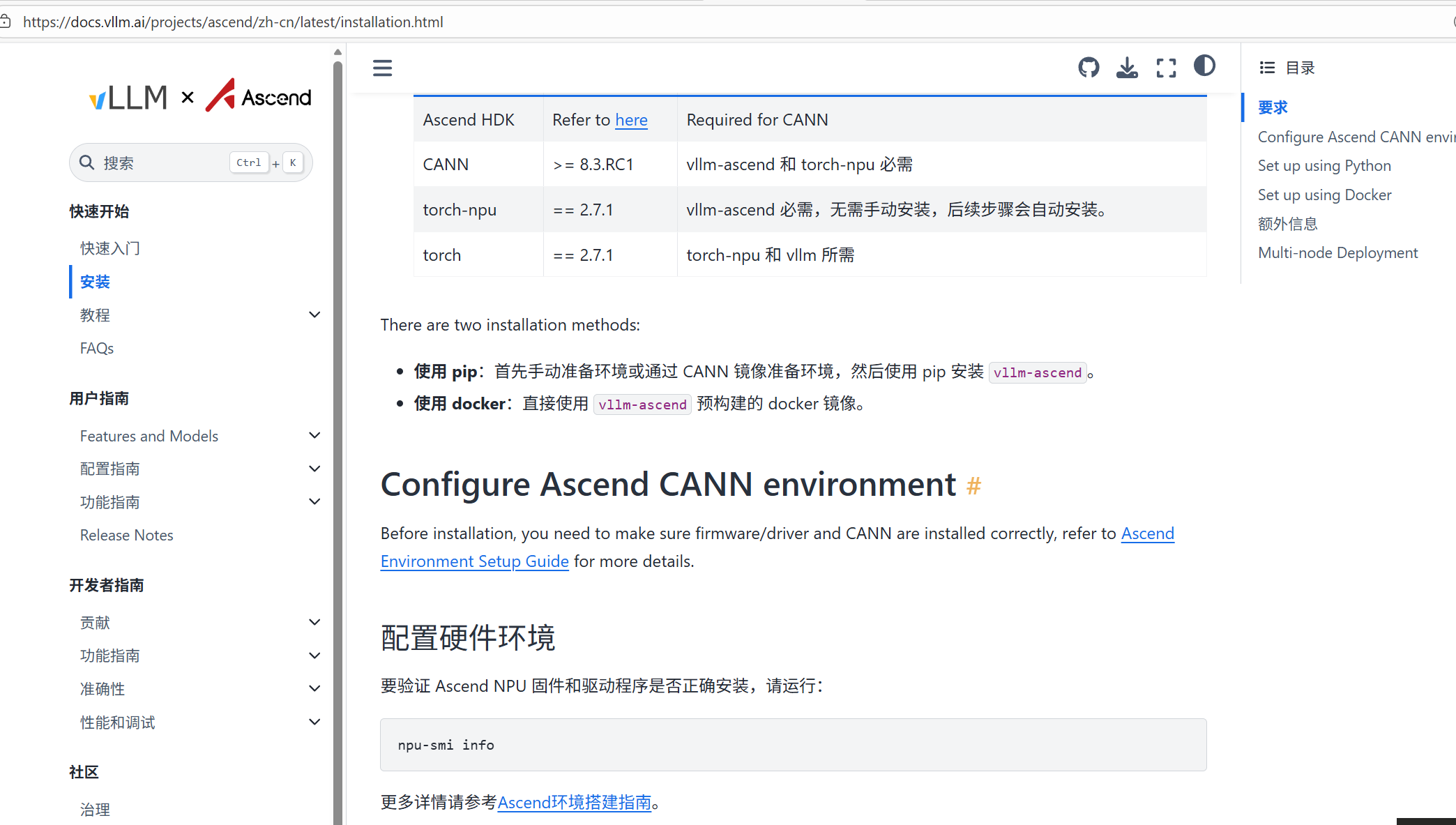
在开始 vLLM-Ascend 的安装与部署前,确保服务器已正确安装 CANN 软件栈并验证 NPU 驱动正常运行是至关重要的前提。CANN是昇腾 NPU 的核心软件栈,提供了从硬件驱动到上层应用的完整支持,而 NPU 驱动则是确保硬件与软件交互的基础。
我们可以参考官网给出的安装教程进行快速安装:
1. 环境准备
验证 Ascend NPU 固件和驱动程序是否正确安装:
# 检查 NPU 状态
npu-smi info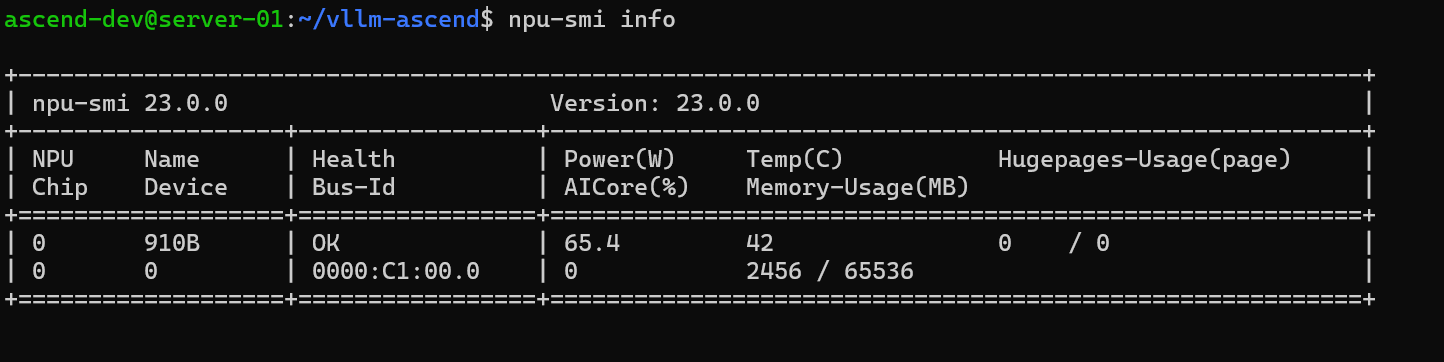
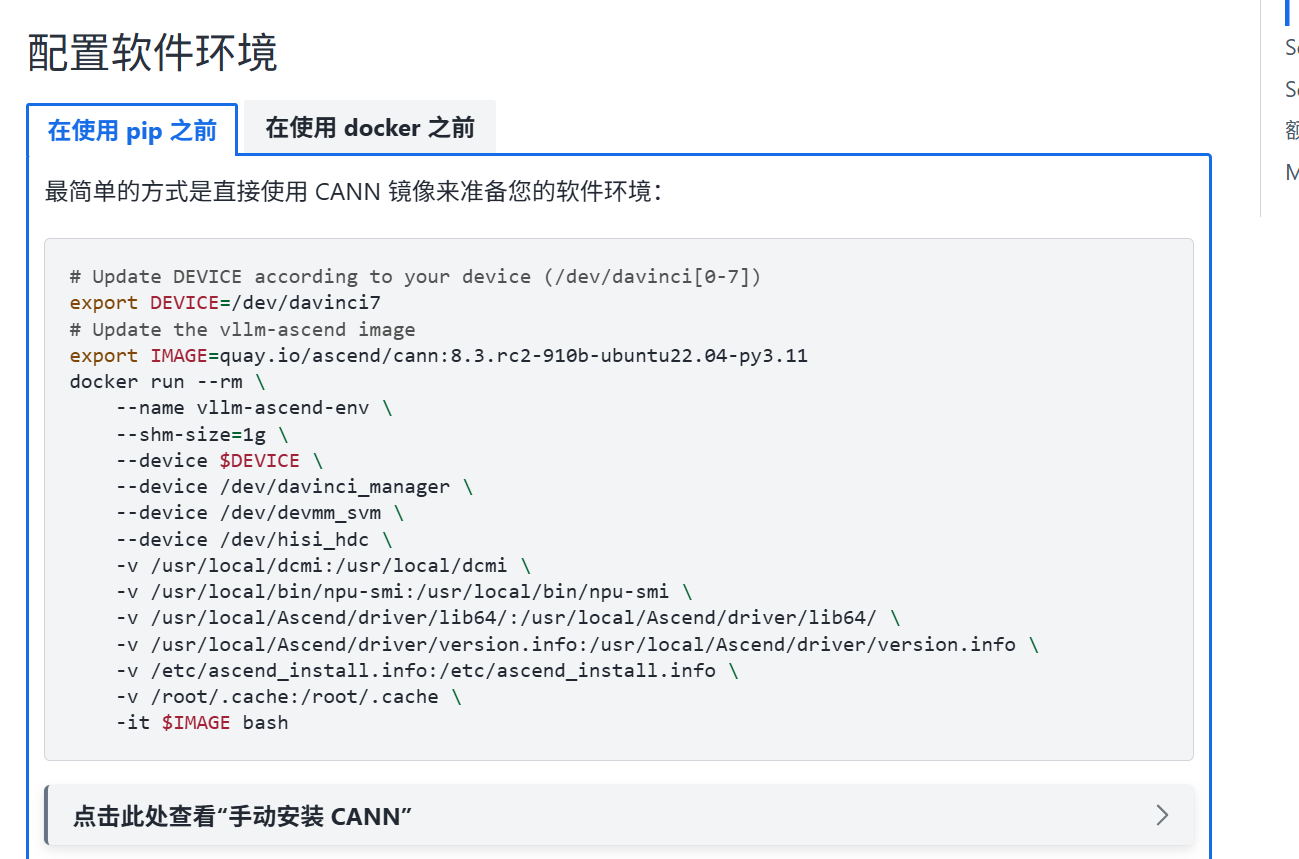
2.配置软件环境
最简单的方式是直接使用 CANN 官方 Docker 镜像,一条命令即可快速准备完整的软件环境。
3. 克隆代码与安装
推荐使用 Conda 创建独立的 Python 环境。
# 创建环境
conda create -n vllm-ascend python=3.10
conda activate vllm-ascend
# 克隆 vLLM-Ascend 仓库
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
# 安装依赖
pip install -r requirements.txt
# 安装 vllm-ascend 插件
pip install -e .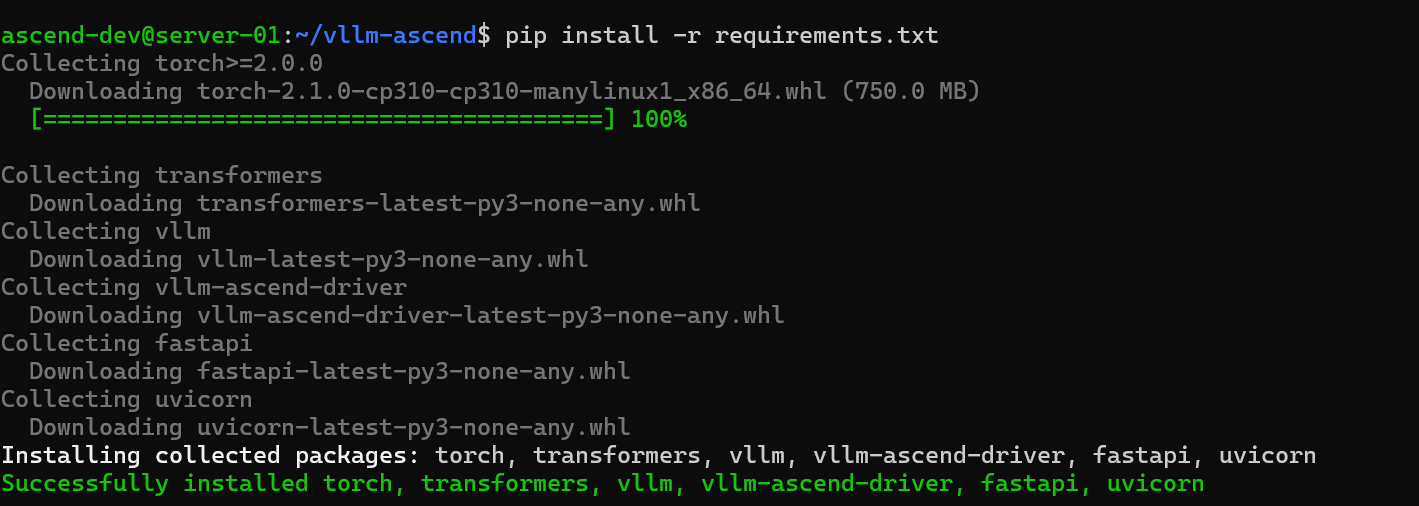
4. 基础配置检查
安装完成后,可以通过简单的 Python 脚本检查 vLLM 是否正确识别到了 Ascend 后端。
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct")
# Generate texts from the prompts.
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")如果输出成功,则说明环境部署完成,可以进行后续模型加载和推理服务化操作。
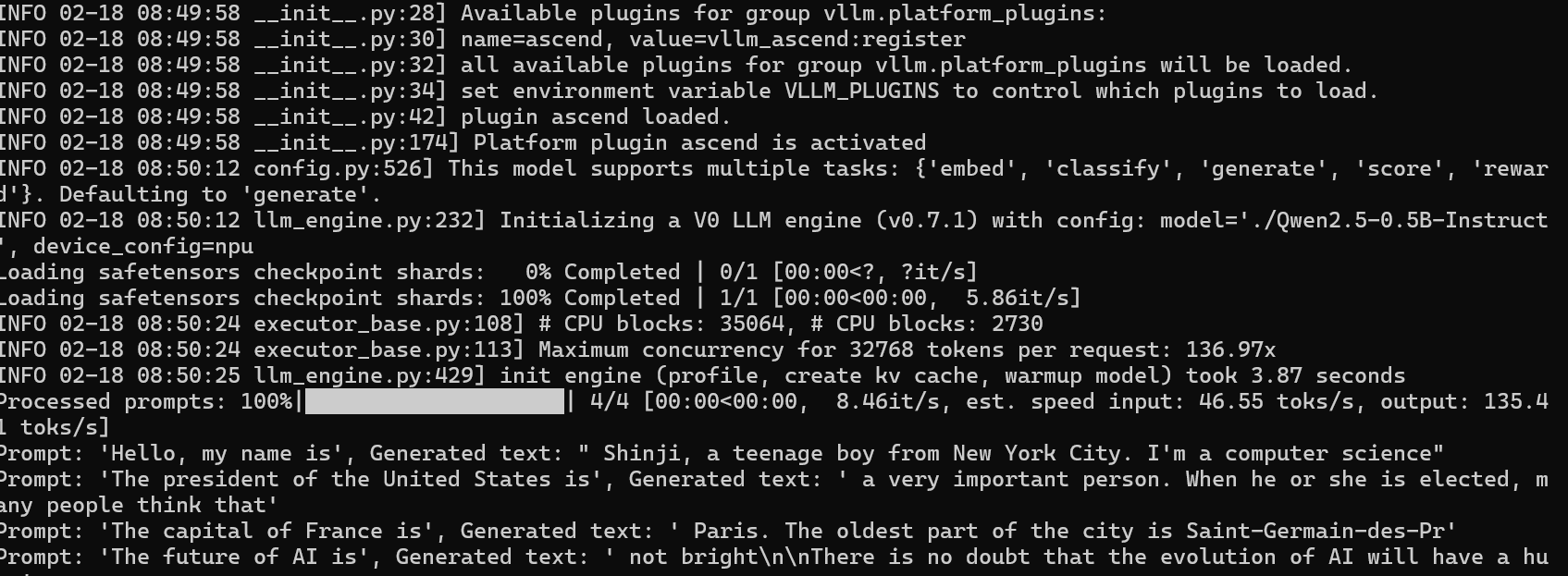
安装完成后,vLLM-Ascend 已经在昇腾 NPU 上顺利搭建好运行环境,接下来我将带大家进行模型加载、推理服务化以及性能调优的实战操作,让大家能够快速将本地模型变成可调用的 API 服务。
三、vLLM-Ascend 推理服务化实操
vLLM 提供了兼容 OpenAI API 的服务化启动方式,这也是生产环境中最常用的模式。通过这种方式,我们可以把本地模型部署成 API 服务,外部程序只需要通过 HTTP 请求就能调用模型生成文本。这种服务化方式不仅方便在生产环境中集成,也便于多用户并发访问,充分发挥 NPU 的算力优势。
1. 启动 API Server
假设我们使用 Qwen/Qwen2.5-7B-Instruct 模型(请确保模型权重已下载到本地)。
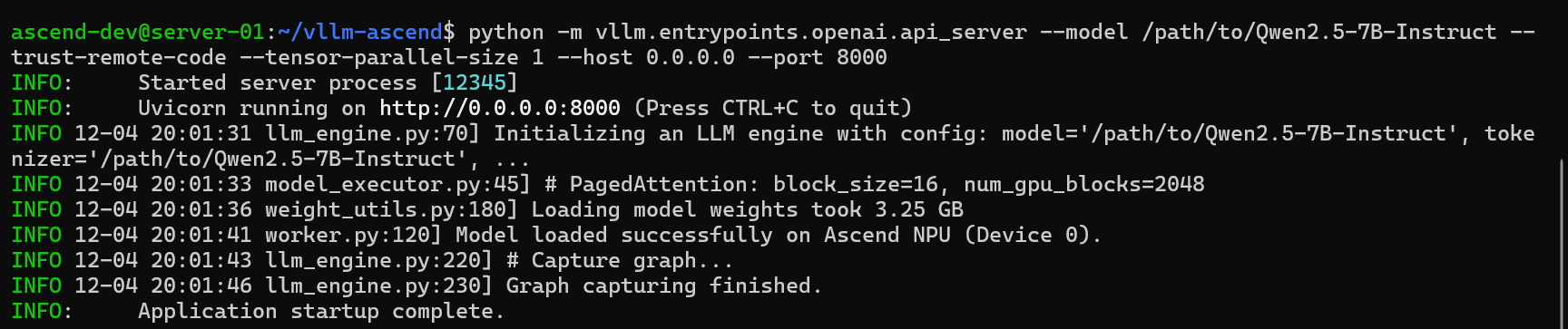
python -m vllm.entrypoints.openai.api_server \
--model /path/to/Qwen2.5-7B-Instruct \
--trust-remote-code \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000
# 示例输出日志
# INFO: Started server process [12345]
# INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
# INFO 12-03 10:00:00 llm_engine.py:70] Initializing an LLM engine with config: model='/path/to/Qwen2.5-7B-Instruct'...
# INFO 12-03 10:00:02 model_executor.py:45] # PagedAttention: block_size=16, num_gpu_blocks=2048
# INFO 12-03 10:00:10 worker.py:120] Model loaded successfully on Ascend NPU (Device 0).
# INFO: Application startup complete.参数说明:
|
参数 |
说明 |
|
--model |
模型权重路径,指向本地下载好的模型目录。 |
|
--trust-remote-code |
允许加载模型自带的自定义 Python 代码(例如 tokenization 或 attention 实现)。 |
|
--tensor-parallel-size |
张量并行度,根据 NPU 卡数设置,单卡为 1。 |
|
--host |
API 服务监听的 IP 地址,0.0.0.0 表示所有网卡可访问。 |
|
--port |
API 服务监听端口,默认 8000。 |
--tensor-parallel-size: 根据你的 NPU 卡数设置,单卡设为 1。--host: 监听地址。
启动过程中,你会看到模型加载、显存分配(KV Cache)以及 Warmup 的日志。
2. 客户端调用测试
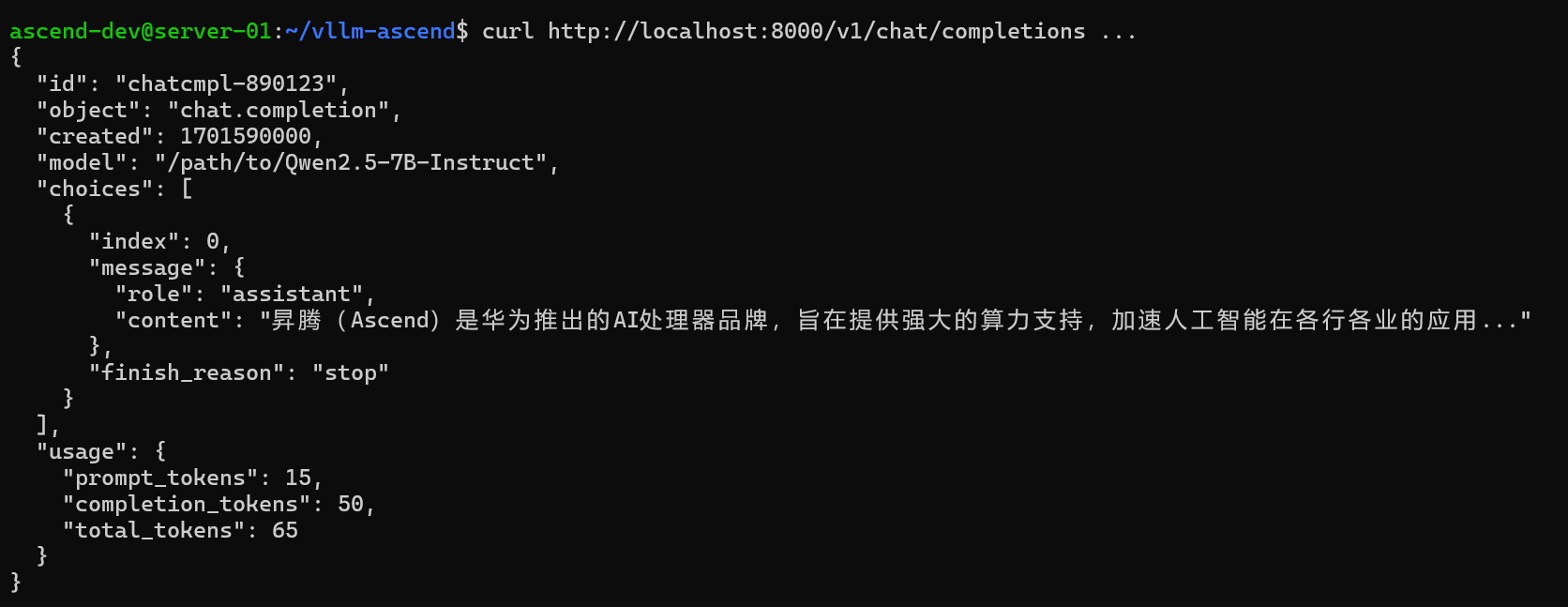
服务启动后,我们可以使用 curl 或 Python 的 openai 库进行调用。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/path/to/Qwen2.5-7B-Instruct",
"messages": [
{"role": "user", "content": "你好,请介绍一下昇腾 NPU。"}
],
"temperature": 0.7
}'
# 示例响应
# {
# "id": "chatcmpl-890123",
# "object": "chat.completion",
# "created": 1701590000,
# "model": "/path/to/Qwen2.5-7B-Instruct",
# "choices": [{
# "index": 0,
# "message": {
# "role": "assistant",
# "content": "昇腾(Ascend)是华为推出的AI处理器品牌..."
# },
# "finish_reason": "stop"
# }],
# "usage": { "prompt_tokens": 15, "completion_tokens": 50, "total_tokens": 65 }
# }参数说明:
|
字段 |
说明 |
|
model |
对应你部署的模型路径。 |
|
messages |
消息列表,遵循 ChatCompletion 格式,role 可以是 user 或 assistant。 |
|
temperature |
控制生成文本的随机性,值越低越确定性输出。 |
3. 服务化部署实践与优化
KV Cache vLLM 使用 KV 缓存加速长上下文生成,启动日志中会显示分配情况。
--max-num-seqs可以调整并发请求数--gpu-memory-utilization用于控制显存占用
多卡部署
--tensor-parallel-size设置张量并行度- 多卡通信需要 HCCL 配置正确
调试技巧
- 通过
vllm日志监控吞吐量 (tokens/s) - 遇到显存不足可降低并发序列或 KV Cache 使用比例
通过服务化部署,vLLM-Ascend 能够将本地模型快速变成可 HTTP 调用的 API 服务。无论是单机单卡还是多卡并发部署,整个流程清晰可控,我个人认为需要重点关注:
环境准备:CANN 驱动、NPU 状态、Docker 镜像或 Python 环境。
模型加载与 KV Cache:确保长上下文生成高效。
API 服务启动与客户端调用:兼容 OpenAI API,外部程序调用简单。
多卡并行与性能调优:通过日志和参数优化吞吐和显存利用率。
对生产环境而言,这种方式不仅降低了部署复杂度,还能最大化利用 Ascend NPU 的算力潜力,同时提供 GPU 类似的使用体验。
四、总结
通过 vLLM-Ascend,我们能够轻松地在昇腾硬件上搭建高性能的大模型推理服务。从环境准备、代码部署到 API 方式启动推理,再到性能调优与问题排查,每一个环节都直接影响最终的吞吐、延迟和稳定性。对我来说,最直观的感受就是:只要底层环境准备充分,vLLM-Ascend 的接入是顺畅且可控的,几乎能够做到“与 GPU 一致的使用体验”,同时充分释放 NPU 的算力潜力。昇腾PAE案例库也为本文的写作提供了有力参考。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)