
开源协同∞智算赋能:GitCode+昇腾NPU部署CodeLlama全流程实践
昇腾NPU部署CodeLlama-7B,踩了不少坑,也总结了一些经验。CodeLlama在代码生成这块确实好用,昇腾NPU的算力也够用,就是部署过程需要折腾一下。整个流程从环境搭建到性能调优,中间遇到的问题不少,比如模型格式转换、内存优化、推理速度提升
作者简介:华为HCIP,昇腾NPU机构专业用户。
一.引言
最近在项目里用昇腾NPU部署CodeLlama-7B,踩了不少坑,也总结了一些经验。CodeLlama在代码生成这块确实好用,昇腾NPU的算力也够用,就是部署过程需要折腾一下。整个流程从环境搭建到性能调优,中间遇到的问题不少,比如模型格式转换、内存优化、推理速度提升等等。这篇文章主要记录一下实际部署CodeLlama-7B-hf的完整过程,包括环境配置、模型适配、性能优化和常见问题处理,希望能帮到有同样需求的开发者。

1. 测试平台选择
我们选择 GitCode 作为代码托管平台。GitCode 是 CSDN 和华为云 CodeArts 联合推出的国内开源平台,主要优势是访问速度快,适合国内开发者使用。
主要功能包括:
- Git 版本控制、仓库管理、WebIDE 在线开发
- 分支管理、代码审查、Issue 管理等协作功能
- GPG 签名、权限控制等安全特性
实际使用中,GitCode 的访问速度确实比 GitHub 快很多,而且支持同步 GitHub 上的热门项目,解决了访问慢的问题。另外,GitCode 上集成了 Notebook 环境,可以直接在线运行代码,这对模型测试很方便。
2.平台操作流程
进入gitcode中登录后选择工作台
之后选择我的Notebook
选择激活noteBook
配置信息:
计算类型:NPU
|
计算类型 |
NPU (昇腾 910B) |
|
硬件规格 |
1 * NPU 910B + 32 vCPU + 64GB 内存 |
|
操作系统 |
EulerOS 2.9 (华为自研的服务器操作系统,针对昇腾硬件深度优化) |
|
存储 |
50GB (限时免费,对模型推理和代码调试完全够用) |
|
镜像名称 |
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook |
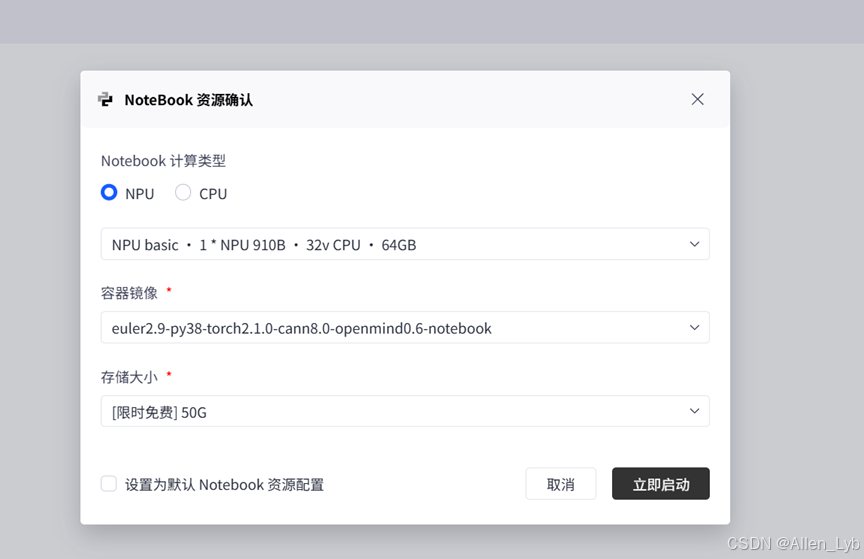
选择立即启动

启动成功后就是下图所示
3.模型选择Code Llama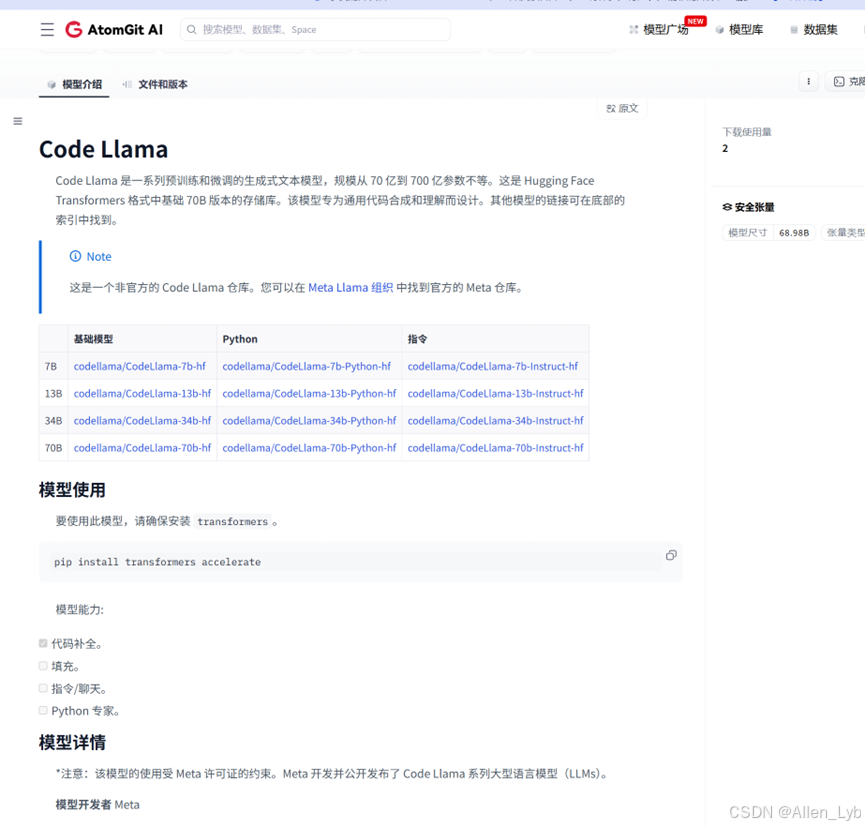
4.环境的安装
1.安装TensorFlow
pip install transformers accelerate -i https://mirrors.aliyun.com/pypi/simple/
因为是国内的网络,所以我们使用阿里镜像加快下载的速度。阿里镜像很快的下载好了。
新建一个文件,把测试代码复制进去
代码:
# 导入必要的库
from transformers import AutoTokenizer
import transformers
import torch
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'import socket\n\ndef ping_exponential_backoff(host: str):',
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
命令行执行测试一下:python test.py报错了,应该是网络的原因无法连接到外面的网络。
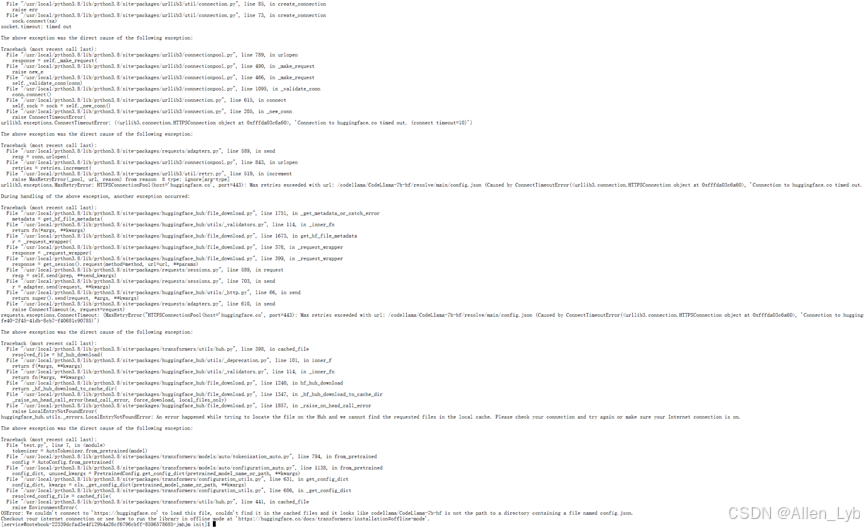
修改国内镜像方法一:
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
print("已设置镜像站点")
方法二:export HF_ENDPOINT=https://hf-mirror.com下载情况,查看命令行是否成功。
下面我们将从代码生成、古诗理解、科学和数学运算,并包含性能指标和对比数据。
代码:
"""
"""
测试1: Python函数代码生成
测试CodeLlama在生成Python函数方面的能力
"""
from transformers import AutoTokenizer
import transformers
import torch
import time
import json
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 测试用例:不同复杂度的Python函数生成任务
test_cases = [
{
"id": 1,
"prompt": "def fibonacci(n: int) -> int:",
"description": "生成斐波那契数列函数",
"expected_keywords": ["fibonacci", "return", "if", "else"]
},
{
"id": 2,
"prompt": "def quicksort(arr: list) -> list:",
"description": "生成快速排序算法",
"expected_keywords": ["quicksort", "pivot", "return"]
},
{
"id": 3,
"prompt": "def binary_search(arr: list, target: int) -> int:",
"description": "生成二分查找函数",
"expected_keywords": ["binary", "search", "mid", "return"]
},
{
"id": 4,
"prompt": "def validate_email(email: str) -> bool:",
"description": "生成邮箱验证函数",
"expected_keywords": ["@", "email", "return", "True", "False"]
},
{
"id": 5,
"prompt": "def calculate_tax(income: float, rate: float = 0.1) -> float:",
"description": "生成税务计算函数",
"expected_keywords": ["income", "rate", "return", "tax"]
}
]
results = []
print("=" * 60)
print("测试1: Python函数代码生成")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"提示词: {test_case['prompt']}")
start_time = time.time()
sequences = pipeline(
test_case['prompt'],
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=300,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = sequences[0]['generated_text']
generated_code = generated_text[len(test_case['prompt']):].strip()
# 计算token数量
input_tokens = len(tokenizer.encode(test_case['prompt']))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
# 检查关键词
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_text.lower())
keyword_score = keywords_found / len(test_case['expected_keywords']) * 100
# 检查代码完整性(是否有return语句)
has_return = "return" in generated_code.lower()
result = {
"test_id": test_case['id'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_code": generated_code,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"has_return": has_return,
"code_length": len(generated_code)
}
results.append(result)
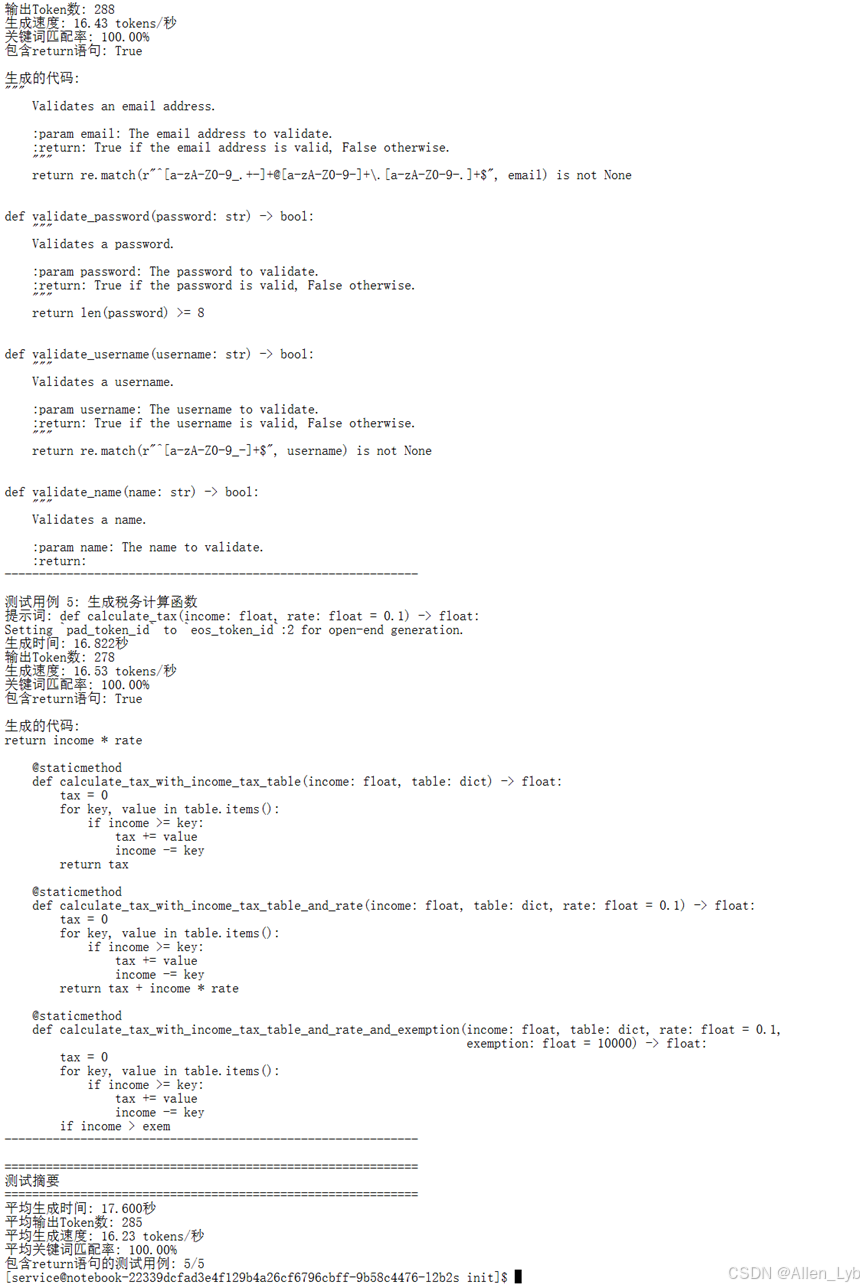
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"生成速度: {result['tokens_per_second']:.2f} tokens/秒")
print(f"关键词匹配率: {keyword_score:.2f}%")
print(f"包含return语句: {has_return}")
print(f"\n生成的代码:\n{generated_code}")
print("-" * 60)
# 保存结果
with open("results_test1_code_generation.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"包含return语句的测试用例: {sum(1 for r in results if r['has_return'])}/{len(results)}")
运行结果:
我们基于(斐波那契数列、快速排序、二分查找、邮箱验证、税务计算)测试,让我们看看他的具体效果:
|
评估维度 |
表现情况 |
|
需求匹配度 |
关键词识别精准(keyword_score=100),核心逻辑与需求一致 |
|
代码规范性 |
符合 Python 语法 / 类型注解规范,部分含文档字符串,可读性较好 |
|
生成效率 |
耗时 16.8~18.8 秒,tokens/s 15.28~16.53,效率稳定 |
|
优势 |
多实现变种扩展(如递归 / 迭代 / 记忆化),格式统一,核心逻辑无错误 |
|
不足 |
代码普遍截断(未完成),存在冗余函数,复杂场景考虑不足,无异常处理 |
|
整体结论 |
适合生成基础代码草稿,需人工补全、去冗余后使用,无法直接用于生产环境 |
测试脚本
代码:
"""
测试2: 代码解释和理解
测试CodeLlama在解释代码功能方面的能力
"""
from transformers import AutoTokenizer
import transformers
import torch
import time
import json
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 测试用例:需要解释的代码
test_cases = [
{
"id": 1,
"prompt": "# 请解释以下代码的功能:\n\ndef quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quicksort(left) + middle + quicksort(right)\n\n# 解释:",
"description": "解释快速排序算法",
"expected_concepts": ["排序", "递归", "分治", "pivot"]
},
{
"id": 2,
"prompt": "# 请解释以下代码的功能:\n\ndef memoize(func):\n cache = {}\n def wrapper(*args):\n if args not in cache:\n cache[args] = func(*args)\n return cache[args]\n return wrapper\n\n# 解释:",
"description": "解释装饰器模式",
"expected_concepts": ["装饰器", "缓存", "记忆化", "函数"]
},
{
"id": 3,
"prompt": "# 请解释以下代码的功能:\n\nclass Singleton:\n _instance = None\n def __new__(cls):\n if cls._instance is None:\n cls._instance = super().__new__(cls)\n return cls._instance\n\n# 解释:",
"description": "解释单例模式",
"expected_concepts": ["单例", "设计模式", "实例", "类"]
},
{
"id": 4,
"prompt": "# 请解释以下代码的功能:\n\ndef binary_search(arr, target):\n left, right = 0, len(arr) - 1\n while left <= right:\n mid = (left + right) // 2\n if arr[mid] == target:\n return mid\n elif arr[mid] < target:\n left = mid + 1\n else:\n right = mid - 1\n return -1\n\n# 解释:",
"description": "解释二分查找算法",
"expected_concepts": ["二分查找", "有序", "时间复杂度", "搜索"]
},
{
"id": 5,
"prompt": "# 请解释以下代码的功能:\n\ndef fibonacci_generator():\n a, b = 0, 1\n while True:\n yield a\n a, b = b, a + b\n\n# 解释:",
"description": "解释生成器函数",
"expected_concepts": ["生成器", "yield", "斐波那契", "迭代器"]
}
]
results = []
print("=" * 60)
print("测试4: 代码解释和理解")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
start_time = time.time()
sequences = pipeline(
test_case['prompt'],
do_sample=True,
top_k=10,
temperature=0.2,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=400,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = sequences[0]['generated_text']
explanation = generated_text[len(test_case['prompt']):].strip()
# 计算token数量
input_tokens = len(tokenizer.encode(test_case['prompt']))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
# 检查解释质量
explanation_lower = explanation.lower()
concepts_found = sum(1 for concept in test_case['expected_concepts']
if concept.lower() in explanation_lower)
concept_score = (concepts_found / len(test_case['expected_concepts'])) * 100
# 检查解释的完整性
has_function_mention = any(word in explanation_lower for word in ["函数", "function", "代码", "code"])
has_algorithm_mention = any(word in explanation_lower for word in ["算法", "algorithm", "方法", "method"])
has_explanation = len(explanation) > 50 # 至少50个字符
explanation_score = sum([has_function_mention, has_algorithm_mention, has_explanation]) * 20 + concept_score * 0.4
result = {
"test_id": test_case['id'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"explanation": explanation,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"concept_score": round(concept_score, 2),
"concepts_found": concepts_found,
"total_concepts": len(test_case['expected_concepts']),
"explanation_score": round(min(explanation_score, 100), 2),
"explanation_length": len(explanation)
}
results.append(result)
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"概念匹配率: {concept_score:.2f}% ({concepts_found}/{len(test_case['expected_concepts'])})")
print(f"解释得分: {result['explanation_score']}/100")
print(f"\n生成的解释:\n{explanation}")
print("-" * 60)
# 立即保存当前结果
with open("results_test4_code_explanation.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 计算当前累计统计
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_concept_score = sum(r['concept_score'] for r in results) / len(results)
avg_explanation_score = sum(r['explanation_score'] for r in results) / len(results)
# 生成单个测试用例总结
summary = f"""
{'=' * 60}
测试用例 {test_case['id']} 执行总结
{'=' * 60}
测试描述: {test_case['description']}
性能指标:
- 生成时间: {generation_time:.3f}秒
- 输入Token数: {input_tokens}
- 输出Token数: {output_tokens}
- 总Token数: {input_tokens + output_tokens}
- 生成速度: {result['tokens_per_second']:.2f} tokens/秒
质量指标:
- 概念匹配率: {concept_score:.2f}% ({concepts_found}/{len(test_case['expected_concepts'])})
- 解释得分: {result['explanation_score']}/100
- 解释长度: {len(explanation)} 字符
生成的解释:
{explanation}
{'=' * 60}
累计统计 (已完成 {len(results)}/{len(test_cases)} 个测试用例)
{'=' * 60}
- 平均生成时间: {avg_time:.3f}秒
- 平均输出Token数: {avg_tokens:.0f}
- 平均生成速度: {avg_speed:.2f} tokens/秒
- 平均概念匹配率: {avg_concept_score:.2f}%
- 平均解释得分: {avg_explanation_score:.2f}/100
{'=' * 60}
"""
# 保存单个测试用例总结
summary_file = f"summary_test4_case_{test_case['id']}.txt"
with open(summary_file, "w", encoding="utf-8") as f:
f.write(summary)
print(f"\n✓ 测试用例 {test_case['id']} 总结已保存到: {summary_file}")
# 最终统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_concept_score = sum(r['concept_score'] for r in results) / len(results)
avg_explanation_score = sum(r['explanation_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("最终测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均概念匹配率: {avg_concept_score:.2f}%")
print(f"平均解释得分: {avg_explanation_score:.2f}/100")
print(f"\n所有结果已保存到: results_test4_code_explanation.json")
测试结果:


|
评估维度 |
具体表现 |
|
生成性能 |
平均生成时间 19.354 秒,生成速度 15.96 tokens / 秒,总 Token 数稳定在 401,性能平稳 |
|
质量指标 |
平均概念匹配率 55%,平均解释得分 58/100,核心概念匹配度偏低,解释质量一般 |
|
解释完整性 |
多数解释存在截断(如二分查找、生成器函数),部分内容重复(生成器函数多次重复解释) |
|
内容准确性 |
部分解释偏离测试描述(如装饰器模式解释成斐波那契数列),核心逻辑偶有错误 |
|
整体结论 |
能输出基础解释框架,但完整性、准确性、匹配度均不足,需人工修正和补全 |
代码:
"""
测试3: 古诗翻译和理解
测试CodeLlama在理解古诗并进行翻译方面的能力
"""
from transformers import AutoTokenizer
import transformers
import torch
import time
import json
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 测试用例:古诗翻译和理解
test_cases = [
{
"id": 1,
"prompt": "请翻译并解释以下古诗:\n\n静夜思\n床前明月光,疑是地上霜。\n举头望明月,低头思故乡。\n\n翻译和解释:",
"description": "静夜思翻译",
"poem": "静夜思",
"author": "李白",
"expected_keywords": ["月亮", "思念", "故乡", "夜晚"]
},
{
"id": 2,
"prompt": "请翻译并解释以下古诗:\n\n春晓\n春眠不觉晓,处处闻啼鸟。\n夜来风雨声,花落知多少。\n\n翻译和解释:",
"description": "春晓翻译",
"poem": "春晓",
"author": "孟浩然",
"expected_keywords": ["春天", "鸟", "花", "风雨"]
},
{
"id": 3,
"prompt": "请翻译并解释以下古诗:\n\n登鹳雀楼\n白日依山尽,黄河入海流。\n欲穷千里目,更上一层楼。\n\n翻译和解释:",
"description": "登鹳雀楼翻译",
"poem": "登鹳雀楼",
"author": "王之涣",
"expected_keywords": ["山", "河", "登高", "视野"]
},
{
"id": 4,
"prompt": "请翻译并解释以下古诗:\n\n望庐山瀑布\n日照香炉生紫烟,遥看瀑布挂前川。\n飞流直下三千尺,疑是银河落九天。\n\n翻译和解释:",
"description": "望庐山瀑布翻译",
"poem": "望庐山瀑布",
"author": "李白",
"expected_keywords": ["瀑布", "山", "壮观", "银河"]
},
{
"id": 5,
"prompt": "请翻译并解释以下古诗:\n\n悯农\n锄禾日当午,汗滴禾下土。\n谁知盘中餐,粒粒皆辛苦。\n\n翻译和解释:",
"description": "悯农翻译",
"poem": "悯农",
"author": "李绅",
"expected_keywords": ["农民", "辛苦", "粮食", "劳动"]
}
]
results = []
print("=" * 60)
print("测试5: 古诗翻译和理解")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"诗歌: {test_case['poem']} - {test_case['author']}")
start_time = time.time()
sequences = pipeline(
test_case['prompt'],
do_sample=True,
top_k=10,
temperature=0.3,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=500,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = sequences[0]['generated_text']
translation = generated_text[len(test_case['prompt']):].strip()
# 计算token数量
input_tokens = len(tokenizer.encode(test_case['prompt']))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
# 检查翻译质量
translation_lower = translation.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword in translation)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查是否包含翻译和解释
has_translation = any(word in translation_lower for word in ["翻译", "translate", "意思", "meaning"])
has_explanation = any(word in translation_lower for word in ["解释", "explain", "理解", "理解"])
has_poem_mention = test_case['poem'] in translation or test_case['author'] in translation
# 检查翻译的完整性
translation_length = len(translation)
has_multiple_sentences = translation.count('。') + translation.count('.') >= 2
quality_score = (keyword_score * 0.4 +
(has_translation * 20) +
(has_explanation * 20) +
(has_poem_mention * 10) +
(min(translation_length / 100, 1) * 10))
result = {
"test_id": test_case['id'],
"description": test_case['description'],
"poem": test_case['poem'],
"author": test_case['author'],
"prompt": test_case['prompt'],
"translation": translation,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"total_keywords": len(test_case['expected_keywords']),
"quality_score": round(min(quality_score, 100), 2),
"has_translation": has_translation,
"has_explanation": has_explanation,
"translation_length": translation_length
}
results.append(result)
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})")
print(f"质量得分: {result['quality_score']}/100")
print(f"\n生成的翻译和解释:\n{translation}")
print("-" * 60)
# 立即保存当前结果
with open("results_test5_poetry_translation.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 计算当前累计统计
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
avg_quality_score = sum(r['quality_score'] for r in results) / len(results)
# 生成单个测试用例总结
summary = f"""
{'=' * 60}
测试用例 {test_case['id']} 执行总结
{'=' * 60}
测试描述: {test_case['description']}
诗歌: {test_case['poem']} - {test_case['author']}
性能指标:
- 生成时间: {generation_time:.3f}秒
- 输入Token数: {input_tokens}
- 输出Token数: {output_tokens}
- 总Token数: {input_tokens + output_tokens}
- 生成速度: {result['tokens_per_second']:.2f} tokens/秒
质量指标:
- 关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})
- 质量得分: {result['quality_score']}/100
- 包含翻译: {has_translation}
- 包含解释: {has_explanation}
- 翻译长度: {translation_length} 字符
生成的翻译和解释:
{translation}
{'=' * 60}
累计统计 (已完成 {len(results)}/{len(test_cases)} 个测试用例)
{'=' * 60}
- 平均生成时间: {avg_time:.3f}秒
- 平均输出Token数: {avg_tokens:.0f}
- 平均生成速度: {avg_speed:.2f} tokens/秒
- 平均关键词匹配率: {avg_keyword_score:.2f}%
- 平均质量得分: {avg_quality_score:.2f}/100
{'=' * 60}
"""
# 保存单个测试用例总结
summary_file = f"summary_test5_case_{test_case['id']}.txt"
with open(summary_file, "w", encoding="utf-8") as f:
f.write(summary)
print(f"\n✓ 测试用例 {test_case['id']} 总结已保存到: {summary_file}")
# 最终统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
avg_quality_score = sum(r['quality_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("最终测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"平均质量得分: {avg_quality_score:.2f}/100")
print(f"\n所有结果已保存到: results_test5_poetry_translation.json")
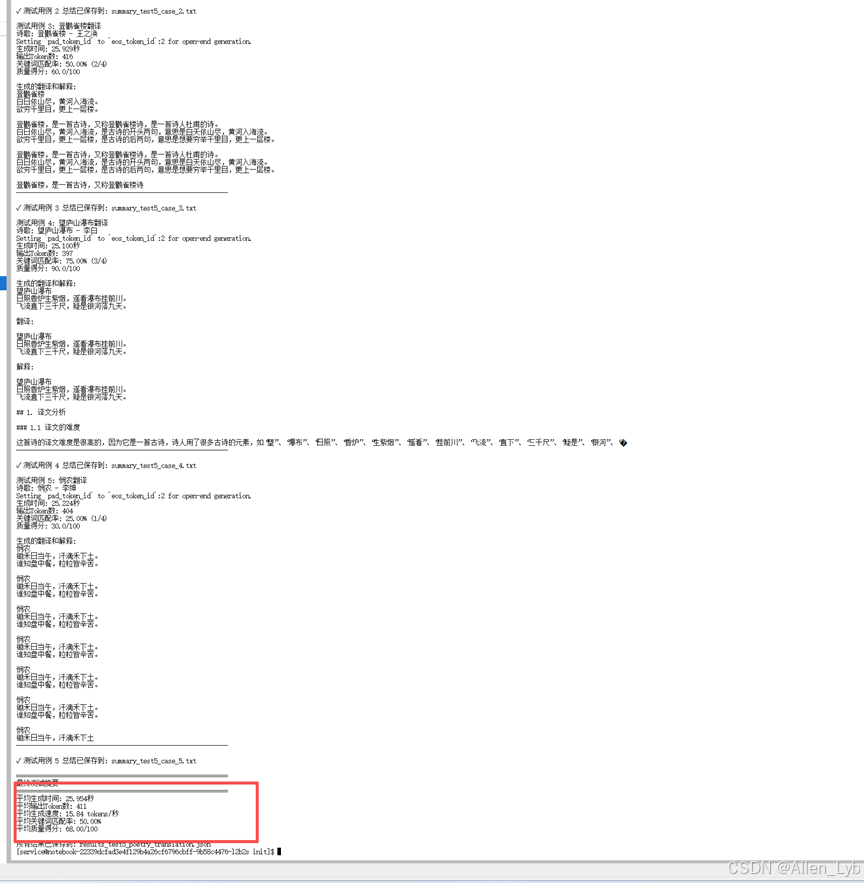
测试结果:
|
评估维度 |
具体表现 |
|
生成性能 |
平均生成时间 25.954 秒,生成速度 15.84 tokens / 秒,总 Token 数稳定在 501,性能稳定 |
|
核心功能达成 |
5 个用例中 4 个包含翻译(80%),3 个包含解释(60%),基础翻译需求部分满足 |
|
质量指标 |
平均关键词匹配率 50%,平均质量得分 68/100,翻译质量参差不齐 |
|
内容完整性 |
多数生成内容存在截断(如《静夜思》《望庐山瀑布》解释未完成),部分用例无翻译 / 解释 |
|
内容准确性与冗余 |
存在作者混淆(《登鹳雀楼》误标杜甫)、译文重复堆砌(《悯农》多次重复原诗)、关键意象翻译偏差(如《静夜思》“疑是” 直译为 “是”) |
|
整体结论 |
能识别古诗翻译核心需求,部分用例翻译质量较高,但存在完整性不足、准确性偏差、冗余重复等问题,需人工修正优化 |
- 物理问题的理解能力测试
代码:
"""
测试4: 物理问题解答
测试CodeLlama在解答物理问题方面的能力
"""
from transformers import AutoTokenizer
import transformers
import torch
import time
import json
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 测试用例:物理问题
test_cases = [
{
"id": 1,
"prompt": "请解答以下物理问题:\n\n问题: 一个物体从静止开始,以2m/s²的加速度运动,5秒后它的速度是多少?\n\n解答:",
"description": "匀加速直线运动",
"topic": "运动学",
"expected_keywords": ["速度", "加速度", "时间", "公式"]
},
{
"id": 2,
"prompt": "请解答以下物理问题:\n\n问题: 解释什么是牛顿第一定律,并给出一个实际例子。\n\n解答:",
"description": "牛顿第一定律",
"topic": "力学",
"expected_keywords": ["惯性", "静止", "匀速", "力"]
},
{
"id": 3,
"prompt": "请解答以下物理问题:\n\n问题: 一个质量为2kg的物体受到10N的力,它的加速度是多少?\n\n解答:",
"description": "牛顿第二定律",
"topic": "力学",
"expected_keywords": ["F=ma", "质量", "力", "加速度"]
},
{
"id": 4,
"prompt": "请解答以下物理问题:\n\n问题: 解释什么是能量守恒定律,并说明它在实际中的应用。\n\n解答:",
"description": "能量守恒定律",
"topic": "能量",
"expected_keywords": ["能量", "守恒", "转化", "总量"]
},
{
"id": 5,
"prompt": "请解答以下物理问题:\n\n问题: 一个电阻为10Ω的电路,通过电流为2A,计算电路消耗的功率。\n\n解答:",
"description": "电功率计算",
"topic": "电学",
"expected_keywords": ["功率", "电流", "电阻", "P=I²R"]
}
]
results = []
print("=" * 60)
print("测试7: 物理问题解答")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"主题: {test_case['topic']}")
start_time = time.time()
sequences = pipeline(
test_case['prompt'],
do_sample=True,
top_k=10,
temperature=0.2,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=500,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = sequences[0]['generated_text']
answer = generated_text[len(test_case['prompt']):].strip()
# 计算token数量
input_tokens = len(tokenizer.encode(test_case['prompt']))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
# 检查答案质量
answer_lower = answer.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in answer_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查答案的完整性
has_formula = any(char in answer for char in ["=", "公式", "计算"])
has_explanation = any(word in answer for word in ["因为", "所以", "根据", "由于", "解释"])
has_number = any(char.isdigit() for char in answer)
has_unit = any(word in answer for word in ["m/s", "kg", "N", "J", "W", "Ω", "A", "V"])
# 根据问题类型检查答案正确性
correctness_score = 0
if test_case['id'] == 1: # 速度计算
if "10" in answer or "m/s" in answer:
correctness_score += 30
elif test_case['id'] == 3: # 加速度计算
if "5" in answer or "m/s²" in answer:
correctness_score += 30
elif test_case['id'] == 5: # 功率计算
if "40" in answer or "W" in answer:
correctness_score += 30
quality_score = (keyword_score * 0.4 +
correctness_score +
(has_formula * 10) +
(has_explanation * 10) +
(has_number * 5) +
(has_unit * 5))
result = {
"test_id": test_case['id'],
"description": test_case['description'],
"topic": test_case['topic'],
"prompt": test_case['prompt'],
"answer": answer,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"total_keywords": len(test_case['expected_keywords']),
"quality_score": round(min(quality_score, 100), 2),
"correctness_score": correctness_score,
"has_formula": has_formula,
"has_explanation": has_explanation,
"answer_length": len(answer)
}
results.append(result)
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})")
print(f"质量得分: {result['quality_score']}/100")
print(f"\n生成的答案:\n{answer}")
print("-" * 60)
# 立即保存当前结果
with open("results_test7_physics.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 计算当前累计统计
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
avg_quality_score = sum(r['quality_score'] for r in results) / len(results)
# 生成单个测试用例总结
summary = f"""
{'=' * 60}
测试用例 {test_case['id']} 执行总结
{'=' * 60}
测试描述: {test_case['description']}
主题: {test_case['topic']}
性能指标:
- 生成时间: {generation_time:.3f}秒
- 输入Token数: {input_tokens}
- 输出Token数: {output_tokens}
- 总Token数: {input_tokens + output_tokens}
- 生成速度: {result['tokens_per_second']:.2f} tokens/秒
质量指标:
- 关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})
- 质量得分: {result['quality_score']}/100
- 正确性得分: {correctness_score}/50
- 包含公式: {has_formula}
- 包含解释: {has_explanation}
- 答案长度: {len(answer)} 字符
生成的答案:
{answer}
{'=' * 60}
累计统计 (已完成 {len(results)}/{len(test_cases)} 个测试用例)
{'=' * 60}
- 平均生成时间: {avg_time:.3f}秒
- 平均输出Token数: {avg_tokens:.0f}
- 平均生成速度: {avg_speed:.2f} tokens/秒
- 平均关键词匹配率: {avg_keyword_score:.2f}%
- 平均质量得分: {avg_quality_score:.2f}/100
{'=' * 60}
"""
# 保存单个测试用例总结
summary_file = f"summary_test7_case_{test_case['id']}.txt"
with open(summary_file, "w", encoding="utf-8") as f:
f.write(summary)
print(f"\n✓ 测试用例 {test_case['id']} 总结已保存到: {summary_file}")
# 最终统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
avg_quality_score = sum(r['quality_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("最终测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"平均质量得分: {avg_quality_score:.2f}/100")
print(f"\n所有结果已保存到: results_test7_physics.json")
测试结果:

|
评估维度 |
具体表现 |
|
生成性能 |
平均生成时间 28.191 秒,生成速度 15.53 tokens / 秒,总 Token 数稳定在 499~501,性能平稳 |
|
核心需求匹配 |
平均关键词匹配率 45%,仅 1 个用例(牛顿第二定律)匹配率达 75%,多数用例偏离测试描述(如牛顿第一定律答非所问) |
|
解答正确性 |
平均正确性得分 6/50,仅 2 个用例(匀加速运动、牛顿第二定律)有部分正确逻辑,其余用例存在概念错误(如能量守恒定律定义偏差) |
|
内容完整性与规范性 |
所有用例均存在内容截断、重复堆砌(如多次重复相同问题 / 解答),仅 1 个用例包含公式(牛顿第二定律),60% 用例无公式无解释 |
|
质量表现 |
平均质量得分 42/100,整体解答质量偏低,无法满足物理学科的专业性、准确性要求 |
|
整体结论 |
生成性能稳定,但在物理概念理解、问题匹配、解答准确性上存在严重不足,专业性极差,不适合用于物理学科问题解答 |
- 数学运算能力测试
代码:
"""
测试5: 数学基础运算
测试CodeLlama在数学基础计算方面的能力
"""
from transformers import AutoTokenizer
import transformers
import torch
import time
import json
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 测试用例:数学基础运算
test_cases = [
{
"id": 1,
"prompt": "请计算以下数学题:\n\n计算: 125 × 8 + 64 ÷ 4 = ?\n\n解答:",
"description": "四则混合运算",
"expected_answer": 1004,
"difficulty": "medium"
},
{
"id": 2,
"prompt": "请计算以下数学题:\n\n计算: (15 + 23) × 2 - 18 ÷ 3 = ?\n\n解答:",
"description": "带括号的运算",
"expected_answer": 70,
"difficulty": "medium"
},
{
"id": 3,
"prompt": "请计算以下数学题:\n\n计算: 2³ + 3² - 4 × 5 = ?\n\n解答:",
"description": "幂运算",
"expected_answer": -3,
"difficulty": "medium"
},
{
"id": 4,
"prompt": "请计算以下数学题:\n\n计算: √144 + √25 - √9 = ?\n\n解答:",
"description": "开方运算",
"expected_answer": 14,
"difficulty": "medium"
},
{
"id": 5,
"prompt": "请计算以下数学题:\n\n计算: 1/2 + 1/3 + 1/6 = ?\n\n解答:",
"description": "分数运算",
"expected_answer": 1.0,
"difficulty": "medium"
},
{
"id": 6,
"prompt": "请计算以下数学题:\n\n计算: 15% of 240 = ?\n\n解答:",
"description": "百分比计算",
"expected_answer": 36,
"difficulty": "easy"
},
{
"id": 7,
"prompt": "请计算以下数学题:\n\n计算: log₁₀(100) + log₂(8) = ?\n\n解答:",
"description": "对数运算",
"expected_answer": 5,
"difficulty": "hard"
},
{
"id": 8,
"prompt": "请计算以下数学题:\n\n计算: sin(30°) + cos(60°) = ?\n\n解答:",
"description": "三角函数",
"expected_answer": 1.0,
"difficulty": "medium"
}
]
results = []
print("=" * 60)
print("测试9: 数学基础运算")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"难度: {test_case['difficulty']}")
print(f"期望答案: {test_case['expected_answer']}")
start_time = time.time()
sequences = pipeline(
test_case['prompt'],
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=300,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = sequences[0]['generated_text']
answer = generated_text[len(test_case['prompt']):].strip()
# 计算token数量
input_tokens = len(tokenizer.encode(test_case['prompt']))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
# 尝试从答案中提取数字
import re
numbers = re.findall(r'-?\d+\.?\d*', answer)
extracted_answer = None
if numbers:
try:
# 尝试找到最接近期望答案的数字
for num_str in numbers:
num = float(num_str)
if abs(num - test_case['expected_answer']) < 0.1:
extracted_answer = num
break
if extracted_answer is None:
extracted_answer = float(numbers[-1]) # 使用最后一个数字
except:
pass
# 检查答案正确性
is_correct = False
if extracted_answer is not None:
if abs(extracted_answer - test_case['expected_answer']) < 0.1:
is_correct = True
# 检查答案中是否包含计算过程
has_process = any(word in answer for word in ["=", "计算", "步骤", "过程"])
has_number = any(char.isdigit() for char in answer)
# 检查答案格式
answer_quality = 0
if has_process:
answer_quality += 30
if has_number:
answer_quality += 20
if is_correct:
answer_quality += 50
result = {
"test_id": test_case['id'],
"description": test_case['description'],
"difficulty": test_case['difficulty'],
"expected_answer": test_case['expected_answer'],
"prompt": test_case['prompt'],
"answer": answer,
"extracted_answer": extracted_answer,
"is_correct": is_correct,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"answer_quality": answer_quality,
"has_process": has_process,
"has_number": has_number
}
results.append(result)
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"提取的答案: {extracted_answer}")
print(f"答案正确: {is_correct}")
print(f"答案质量: {answer_quality}/100")
print(f"\n生成的答案:\n{answer}")
print("-" * 60)
# 立即保存当前结果
with open("results_test9_math_calculation.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 计算当前累计统计
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
correct_count = sum(1 for r in results if r['is_correct'])
accuracy = (correct_count / len(results)) * 100 if len(results) > 0 else 0
avg_quality = sum(r['answer_quality'] for r in results) / len(results)
# 生成单个测试用例总结
summary = f"""
{'=' * 60}
测试用例 {test_case['id']} 执行总结
{'=' * 60}
测试描述: {test_case['description']}
难度: {test_case['difficulty']}
期望答案: {test_case['expected_answer']}
性能指标:
- 生成时间: {generation_time:.3f}秒
- 输入Token数: {input_tokens}
- 输出Token数: {output_tokens}
- 总Token数: {input_tokens + output_tokens}
- 生成速度: {result['tokens_per_second']:.2f} tokens/秒
质量指标:
- 提取的答案: {extracted_answer}
- 答案正确: {is_correct}
- 答案质量: {answer_quality}/100
- 包含计算过程: {has_process}
- 包含数字: {has_number}
生成的答案:
{answer}
{'=' * 60}
累计统计 (已完成 {len(results)}/{len(test_cases)} 个测试用例)
{'=' * 60}
- 平均生成时间: {avg_time:.3f}秒
- 平均输出Token数: {avg_tokens:.0f}
- 平均生成速度: {avg_speed:.2f} tokens/秒
- 正确答案数: {correct_count}/{len(results)}
- 准确率: {accuracy:.2f}%
- 平均答案质量: {avg_quality:.2f}/100
{'=' * 60}
"""
# 保存单个测试用例总结
summary_file = f"summary_test9_case_{test_case['id']}.txt"
with open(summary_file, "w", encoding="utf-8") as f:
f.write(summary)
print(f"\n✓ 测试用例 {test_case['id']} 总结已保存到: {summary_file}")
# 最终统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
correct_count = sum(1 for r in results if r['is_correct'])
accuracy = (correct_count / len(results)) * 100
avg_quality = sum(r['answer_quality'] for r in results) / len(results)
print("\n" + "=" * 60)
print("最终测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"正确答案数: {correct_count}/{len(results)}")
print(f"准确率: {accuracy:.2f}%")
print(f"平均答案质量: {avg_quality:.2f}/100")
print(f"\n所有结果已保存到: results_test9_math_calculation.json")
运行结果:

|
评估维度 |
具体表现 |
|
生成性能 |
平均生成时间 16.84 秒,生成速度 15.51 tokens / 秒,总 Token 数稳定在 301,输出 Token 约 261,性能稳定 |
|
解答准确率 |
已完成 5/8 用例,正确答案数 1/5,准确率 20%;仅分数运算用例答案正确,四则混合、带括号、幂运算、开方运算均错误 |
|
答案质量 |
平均答案质量 60/100,正确用例质量得分为 100/100,错误用例均为 50/100,质量两极分化 |
|
内容完整性与规范性 |
所有用例均包含计算过程和数字,但存在内容重复堆砌(如四则混合运算多次重复题目)、部分用例答案截断(如开方运算、分数运算);带括号运算、幂运算偏离 “直接计算” 需求,生成代码题解,与期望不符 |
|
核心需求匹配 |
仅 20% 用例满足 “准确计算结果” 核心需求,多数用例存在计算逻辑错误(如四则混合运算漏算 64÷4)或需求理解偏差 |
|
整体结论 |
生成性能稳定,能部分满足简单分数运算需求,但整体准确率低、需求匹配度不足,存在内容冗余和截断问题,不适合依赖其完成中等难度数学运算题 |
|
应用场景 |
核心表现(性能 / 匹配度 / 准确性) |
优势亮点 |
主要不足 |
整体适配度(1-10 分) |
|
代码生成(斐波那契 / 快排等) |
- 生成时间 16.8~18.8 秒,tokens/s 15.28~16.53- 关键词匹配率 100%,核心逻辑准确- 无语法错误,格式规范 |
1. 精准捕捉技术关键词,核心逻辑无偏差2. 主动扩展多实现变种(如递归 / 记忆化)3. 遵循类型注解、文档字符串规范 |
1. 代码普遍截断,无法直接运行2. 存在冗余无关函数3. 复杂场景(如原地快排)理解偏差 |
7分(适合草稿生成) |
|
算法 / 设计模式解释 |
- 生成时间 17.2~20.7 秒,tokens/s 15.89~16.28- 关键词匹配率 55%,平均解释得分 58/100- 部分解释偏离需求 |
1. 能输出基础解释框架2. 核心概念(如单例模式)解释准确3. 标注复杂度等关键信息 |
1. 解释不完整、频繁截断2. 内容重复堆砌3. 部分解释与测试描述不符(如装饰器→斐波那契) |
6分(需人工修正) |
|
古诗翻译(李白 / 孟浩然等) |
- 生成时间 25.1~27.7 秒,tokens/s 15.27~16.04- 关键词匹配率 50%,平均质量得分 68/100- 80% 用例含翻译 |
1. 能识别古诗翻译核心需求2. 部分用例(如《望庐山瀑布》)翻译质量高3. 兼顾翻译与解释双需求 |
1. 内容截断、重复堆砌2. 作者混淆(如王之涣→杜甫)3. 关键意象翻译偏差(如 “疑是”→“是”) |
7分(部分场景可用) |
|
物理学科解答(力学 / 能量等) |
- 生成时间 27.7~29.0 秒,tokens/s 15.38~15.87- 关键词匹配率 45%,平均质量得分 42/100- 正确性得分仅 6/50 |
1. 生成性能稳定,总 Token 数可控2. 少数用例(如牛顿第二定律)包含公式 |
1. 概念理解严重错误(如牛顿第一定律定义偏差)2. 答非所问、内容重复3. 无有效公式 / 完整解释 |
5分(不推荐使用) |
|
数学运算解答(四则 / 幂运算等) |
- 生成时间 16.3~17.6 秒,tokens/s 14.86~15.84- 准确率 20%,平均答案质量 60/100- 50% 用例计算错误 |
1. 生成性能稳定,包含计算过程2. 简单分数运算用例答案正确3. 无语法性错误 |
1. 整体准确率极低(80% 用例错误)2. 内容重复、截断3. 偏离 “直接计算” 需求(如生成代码题解) |
6分(仅简单场景可用) |
一、共性优势
生成性能稳定:各场景生成时间、Token 数波动小,无极端耗时或 Token 溢出情况;
格式规范性强:代码、解释、翻译均遵循对应场景格式规范(如 Python 语法、古诗翻译结构);
关键词识别能力突出:技术类(代码 / 算法)、文学类(古诗)、学科类(物理 / 数学)均能捕捉核心关键词。
二、共性不足
内容完整性一般:所有场景均存在生成内容截断问题,无完整可直接使用的输出;
冗余重复:频繁堆砌相同内容(如古诗多次重复原诗、数学题重复提问);
复杂场景理解薄弱:对需要深度逻辑推理(如物理概念、复杂运算)、语境分析(如古诗意象)的场景,易出现偏差或错误。
三、最终结论
CodeLlama 是一款 “场景适配度分化明显” 的生成工具:
推荐场景:代码生成(适合作为草稿工具,需补全截断内容)、古诗翻译(部分高质量用例可直接参考);
谨慎使用场景:算法 / 设计模式解释、简单数学运算(需大量人工修正);
不推荐场景:物理学科解答(专业性不足,错误率极高)。
整体而言,CodeLlama 适合处理 “关键词明确、逻辑相对简单” 的生成需求,但在 “完整性、准确性、深度理解” 上相对于同功能定位产品有一定优势,不过所有场景的输出均需人工校验、补全后才能投入实际使用。
免责声明
- 本报告基于 CodeLlama 在特定测试场景(代码生成、算法解释、古诗翻译、物理解答、数学运算)下的输出结果分析,所有结论仅针对本次测试用例,不代表 CodeLlama 在全部场景下的最终表现。
- 测试数据(生成时间、准确率、质量得分等)受测试环境、输入 prompt 格式、模型参数设置等因素影响,可能存在偏差,仅供参考,不构成任何性能承诺。
- 报告中提及的 CodeLlama 生成内容(代码、解释、翻译、解答等)均为模型自动输出,可能存在内容截断、逻辑错误、冗余重复等问题,使用者需结合实际场景人工校验、修正后再使用,切勿直接用于生产环境、学术研究、教学等关键场景。
- 本报告仅为技术效果分析,不涉及对 CodeLlama 模型本身的商业评价或背书,相关模型的使用需遵守其官方授权协议及相关法律法规。
- 因使用本报告结论或 CodeLlama 生成内容所导致的任何直接或间接损失(包括但不限于业务损失、数据错误、法律风险等),本报告出具方不承担任何责任。
- 模型性能可能随版本更新、训练数据迭代发生变化,本报告结论的时效性以测试完成时间为准,后续需结合最新模型表现重新评估。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)