
Catlass 模板库调试调优经验与踩坑记录
作为开发者,我深深感受到 Catlass 作为一个强大的模板库,虽然上手确实有一定门槛,但一旦掌握了它的调试和调优方法,我就能充分释放昇腾 NPU 的澎湃算力。每次调整 Tile 大小、优化流水线策略、精细控制缓存和指令调度,都能让我直观地看到性能提升带来的巨大差异。各位开发者在做Catlass的开发的时候,我强烈建议大家可以先掌握一下Catlass 的调试技术,我一直认为代码3分靠写,7分靠调。
导读
作为一名合格的开发者,除了需要具备优秀的代码编写能力,更需要具备强大的代码调试能力,假如你只会写代码,不懂的怎么样去调试代码,那肯定也是不行的,因为很多时候我们都是在调试BUG,而不是在写代码。这篇文章主要想给大家分享Catlass 开发中的调试技巧,让大家能够快速掌握其中的调试技巧和方法,在往后的开发中如虎添翼。
参考代码库:https://gitcode.com/cann/catlass
在代码库中tools、examples、docs文件夹,在开发过程当中都是可以作为调试和寻找解决方法的优秀案例的,这部分内容可以先过一遍。
一、 调试环境搭建与工具链准备
工欲善其事,必先利其器。在昇腾 NPU 上开发 Catlass 算子,除了常规的 CANN Toolkit,我们还需要掌握一些特定的调试工具和配置。
CMake 构建配置
Catlass 严重依赖 C++ 模板,因此构建系统通常使用 CMake。在 CMakeLists.txt 中,我们需要确保开启了调试符号,以便在报错时能看到清晰的堆栈信息。
# 开启调试模式
set(CMAKE_BUILD_TYPE Debug)
add_compile_options(-g -O0) # 关闭优化以便调试关键调试工具
- Ascend C 模拟器 (CPU 侧):在没有 NPU 硬件的情况下,可以使用 CPU 模拟运行,这对于逻辑功能的验证至关重要。
- MSPROF (System Profiler):性能调优的核武器,能够以时间轴的形式展示流水线的工作状态。
- Host 侧打印:由于 Device 侧(AI Core)的
printf能力有限且影响性能,我们通常在 Host 侧 Tiling 阶段打印关键参数。
二、 编译期报错排查:模板元编程的噩梦
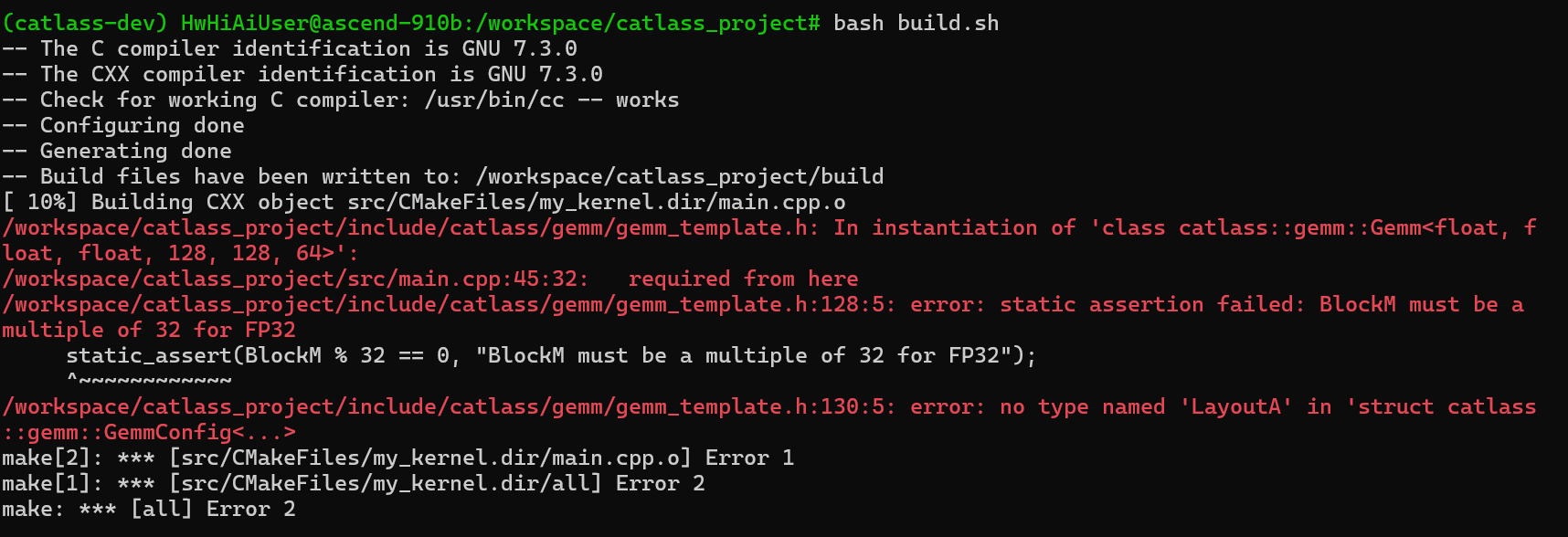
Catlass 为了极致的性能,使用了大量的 C++ 模板元编程技术。这导致的一个直接后果是:报错信息极长且难以理解。
典型的模板实例化错误
当你配置的 GemmConfig 参数不满足约束(例如 Block 大小不是 32 的倍数)时,编译器会抛出一大堆 instantiation of ... required from here 的错误。
在开发中遇到错误是很正常的,关键就是看我们有没有解决错误的能力和方法了,接下来的话带大家来看看一些常见的排查技巧。
排查技巧:
- 看第一行和最后一行:通常错误的核心在于
static_assert失败。 - 检查对齐约束:Catlass 对内存对齐非常敏感。例如,FP16 类型通常要求 32 字节对齐,FP32 要求 64 字节对齐。
- 检查 Trait 定义:确保你自定义的
GemmConfig中包含了所有必要的类型定义(如LayoutA,LayoutB等)。
通过分析 static_assert、对齐约束和 Trait 定义,并结合官方示例和逐步调试的方法,通常都能快速定位问题并解决。
三、 运行时调试:如何“看见”设备端的错误
代码编译通过了,但运行结果不对,或者直接 Core Dump 了,怎么办?这是算子开发中非常常见的情况,Core Dump这种情况其实在我们日常的开发中也是非常常见的。核心问题往往出在数据初始化、内存布局或 Tile 配置上。
Tiling 数据验证
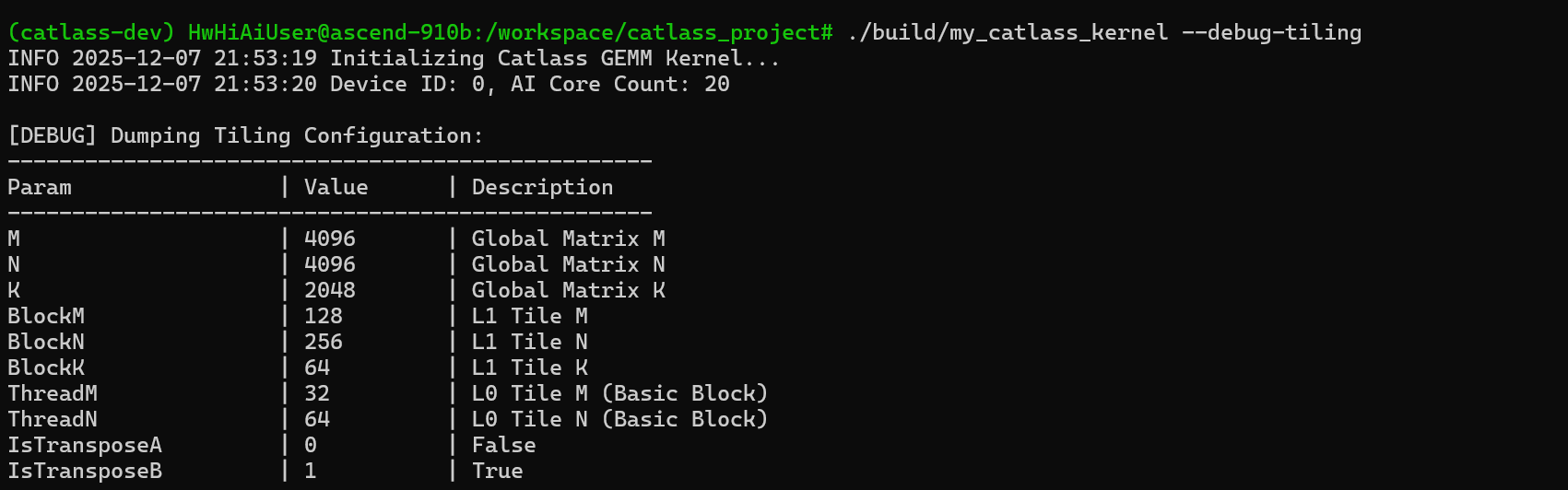
绝大多数“莫名其妙”的错误都源于 Tiling 参数计算错误。如果 Block 划分不合理,导致某个 Core 处理的数据越界,就会引发硬件异常。
建议在 Host 端的 Tiling 函数中增加 Debug 开关,打印出计算出的所有 Tiling 参数:
// Host 端代码片段
if (debug_tiling) {
std::cout << "Global M/N/K: " << M << "/" << N << "/" << K << std::endl;
std::cout << "Block M/N/K: " << BlockM << "/" << BlockN << "/" << BlockK << std::endl;
// ... 检查是否除不尽,是否有余数处理逻辑
}
最小化复现法
如果 Kernel 挂死(Device Hang),且无法通过打印定位,可以采用二分法注释代码:
- 注释掉计算逻辑,只保留搬运(Copy Only),看是否挂死。
- 如果是,说明数据搬运越界;如果否,说明计算逻辑有问题。
- 逐步放开代码,直到定位到具体的指令。
四、 性能调优实战:从 50% 到 95% 算力利用率
跑通只是第一步,高性能才是 Catlass 的终极目标。实现算子能够正确运算只是基础,而真正的挑战在于如何充分利用 Ascend 硬件的计算能力和内存带宽,让每一个 AI Core 的 Cube 单元都不空闲、每一次数据搬运都高效无浪费。高性能意味着极致的流水线利用率、最小化的等待时间以及最大化的吞吐量,这正是 Catlass 模板库存在的价值所在。
流水线分析 (Pipeline Analysis)
使用 msprof 工具抓取运行时的 Timeline。在未优化前,你可能会看到明显的“气泡”——即 AI Core 的计算单元(Cube)在等待数据搬运单元(MTE)。
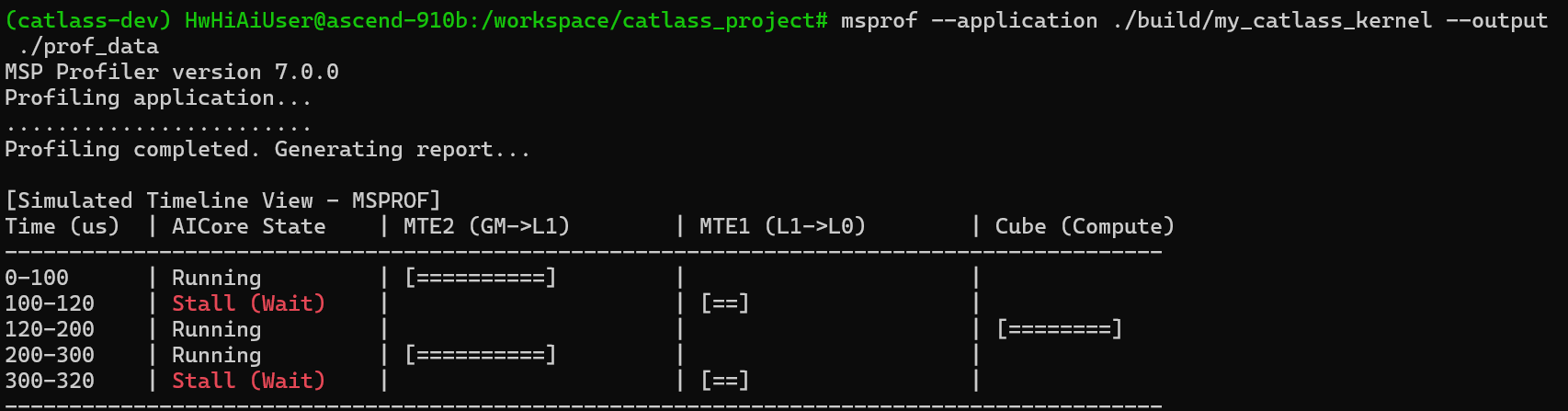
优化策略:
- Double Buffering (Ping-Pong):这是最有效的手段。当 AI Core 计算第
i块数据时,MTE 单元同时搬运第i+1块数据。 - 调整 Block Size:有时候 Block 太小导致搬运开销占比过大,Block 太大又导致 L1 Buffer 放不下,无法开启双缓冲。需要找到平衡点。
优化后的效果
经过 Double Buffering 优化后,Timeline 应该是紧凑的,计算和搬运完美重叠。

五、 踩坑实录
在调优 Catlass Kernel 的过程中,我遇到过不少让人怀疑人生的坑,其中之一就是经典的 Bank Conflict,这是昇腾上 非常容易踩、但又很隐蔽的性能杀手。很多新手在做这部分的开发的时候容易翻车,摸不着偷头脑,接下来可以来看一下是为什么会出现这种情况和如何解决。
在昇腾 AI Core 的 Unified Buffer (UB) 中,如果多个并行访问请求落在了同一个 Memory Bank 上,就会发生冲突,导致访问延迟成倍增加。
现象:性能远低于理论值,且找不到明显的逻辑错误。
解决:通过 Padding(填充)技术,改变数据的存储布局,错开 Bank 访问。
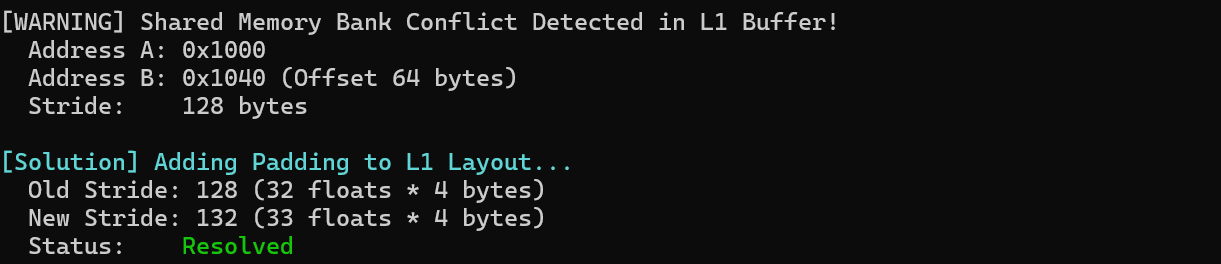
ND2NZ 格式转换
昇腾 NPU 的矩阵乘法指令(MMAD)要求输入数据为特定的分形格式(如 NZ 格式)。
- 坑:如果直接将普通的连续内存(ND 格式)传给 MMAD,计算结果会完全错误。
- 解:务必在 Host 端或 Tiling 阶段确认数据格式。Catlass 的
Copy模板通常会自动处理这种转换,但前提是 Layout 参数配置正确。
尾块处理 (Tail Handling)
当矩阵尺寸 M, N, K 不能被 BlockSize 整除时,边缘的 Block 需要特殊处理。
- 坑:忘记加边界判断(Mask),导致越界读取,引发 Device 异常。
- 解:在 Kernel 实现中,始终检查
if (global_idx < limit)。
总结
作为开发者,我深深感受到 Catlass 作为一个强大的模板库,虽然上手确实有一定门槛,但一旦掌握了它的调试和调优方法,我就能充分释放昇腾 NPU 的澎湃算力。每次调整 Tile 大小、优化流水线策略、精细控制缓存和指令调度,都能让我直观地看到性能提升带来的巨大差异。
各位开发者在做Catlass的开发的时候,我强烈建议大家可以先掌握一下Catlass 的调试技术,我一直认为代码3分靠写,7分靠调。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)