
从慢得离谱到性能翻倍:昇腾910B迁移小模型MobileNet避坑与调优实录
一开始觉得是.to('cpu')慢,结果完全不是。性能问题必须用工具定位,Python层面的计时在异步场景下不可靠。尤其是在涉及NPU/GPU异步计算时,不加测出来的时间都是假的。对于ResNet18、MobileNet这种小计算量模型,调度开销是杀手,开启任务队列优化是必须的。MindStudio的Timeline视图非常直观,能精确到每个算子的微秒级耗时。这个工具一定要学会用。同时昇腾NPU首
最近接到一个任务:把原本跑在英伟达GPU上的业务迁移到国产化昇腾(Ascend)平台。模型不大,是个魔改版的MobileNetV2,对时延非常敏感。原本在GPU上单次推理仅需25ms左右,迁移后直接飙到50ms+。经过深度的Profiling分析,我发现问题的核心不在算力,而在“调度”。通过针对性的参数调优,最终把推理时间压到18ms左右,比原来还快了7ms左右。这篇文章不讲虚的,直接复盘从环境搭建、踩坑、分析到最终优化的完整过程,代码全部基于CANN 8.0实测可用。
一、环境准备
1.1 为啥会变慢
在开始之前,有必要说下背景。我们的业务逻辑包含复杂的预处理和后处理,模型本身计算量其实不大(MobileNet级别)。
昇腾910系列是为大规模训练和高密度计算设计的(类似A100),它的强项是高并发、大吞吐。而跑小batch、小模型时,CPU下发任务的开销很容易超过GPU/NPU实际计算的时间。这就好比用一辆重型卡车去送一份外卖,启动和换挡的时间比路上跑的时间还长。
1.2 启动Notebook
点击上方的 “Notebook 工作区”,进入你的云端开发环境管理页面,首次使用会提示激活,直接确认开通即可:
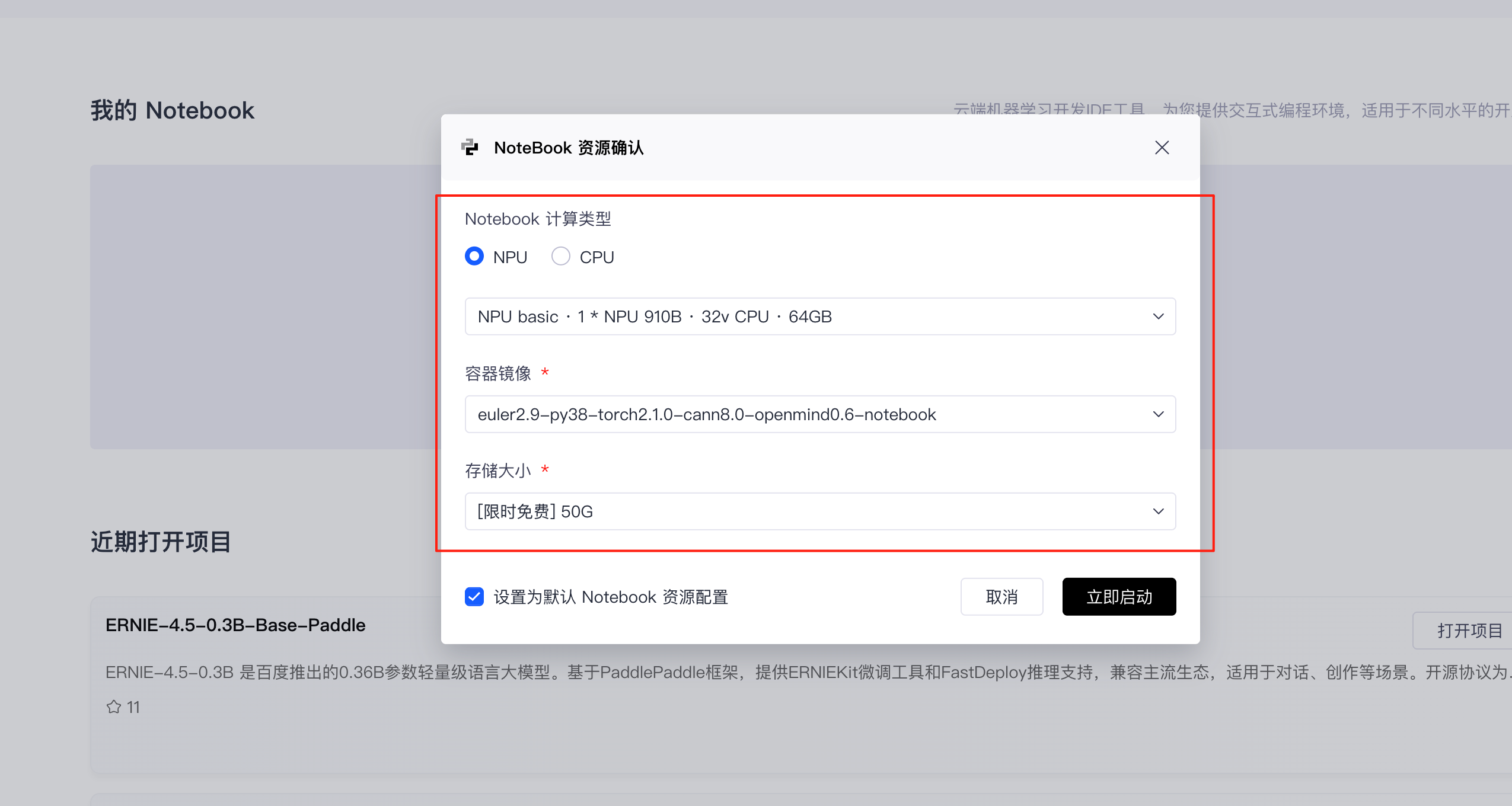
1.3 选择配置
在启动页面选择以下配置:
- 硬件:昇腾910B AI加速芯片(32核VCPU + 64GB内存)
- 镜像:
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook - 存储:50GB
这个镜像预装了Python 3.8、PyTorch 2.1.0(昇腾适配版)、CANN 8.0驱动,可以直接用。
1.4 安装NPU库
进入JupyterLab后,新建一个ipynb文件,执行:
!pip install torch-npu
1.5 验证环境
安装完后测试NPU是否可用(注意必须先import torch_npu):
import torch_npu
import torch
print("PyTorch版本:", torch.__version__)
print("NPU可用:", torch.npu.is_available())
print("设备编号:", torch.npu.current_device())
正常输出应该显示NPU可用,输出结果如下:

二、问题复现
2.1 准备模型
用一个轻量级的MobileNetV2作为测试模型,这个模型参数量适中,能很好地暴露小模型在昇腾上的性能问题:
import torch
import torch_npu
import torchvision.models as models
import time
# 加载模型
model = models.mobilenet_v2(pretrained=True)
device = torch.device("npu:0")
model = model.to(device)
model.eval()
# 准备输入
input_data = torch.randn(1, 3, 224, 224).to(device)
# 预热(这步很重要,不预热首次推理会很慢)
with torch.no_grad():
for _ in range(10):
_ = model(input_data)
print("模型加载完成")
部署结果如图所示,这就显示我们的模型已经加载成功:
2.2 性能测试
分别测试推理和数据传输的耗时:
# 推理阶段计时
with torch.no_grad():
start = time.time()
output = model(input_data)
infer_time = time.time() - start
# 数据传输计时
start = time.time()
output_cpu = output.to('cpu')
transfer_time = time.time() - start
print(f"推理耗时: {infer_time*1000:.2f}ms")
print(f"传输耗时: {transfer_time*1000:.2f}ms")
print(f"总耗时: {(infer_time+transfer_time)*1000:.2f}ms")
在我的测试中,输出结果如下:
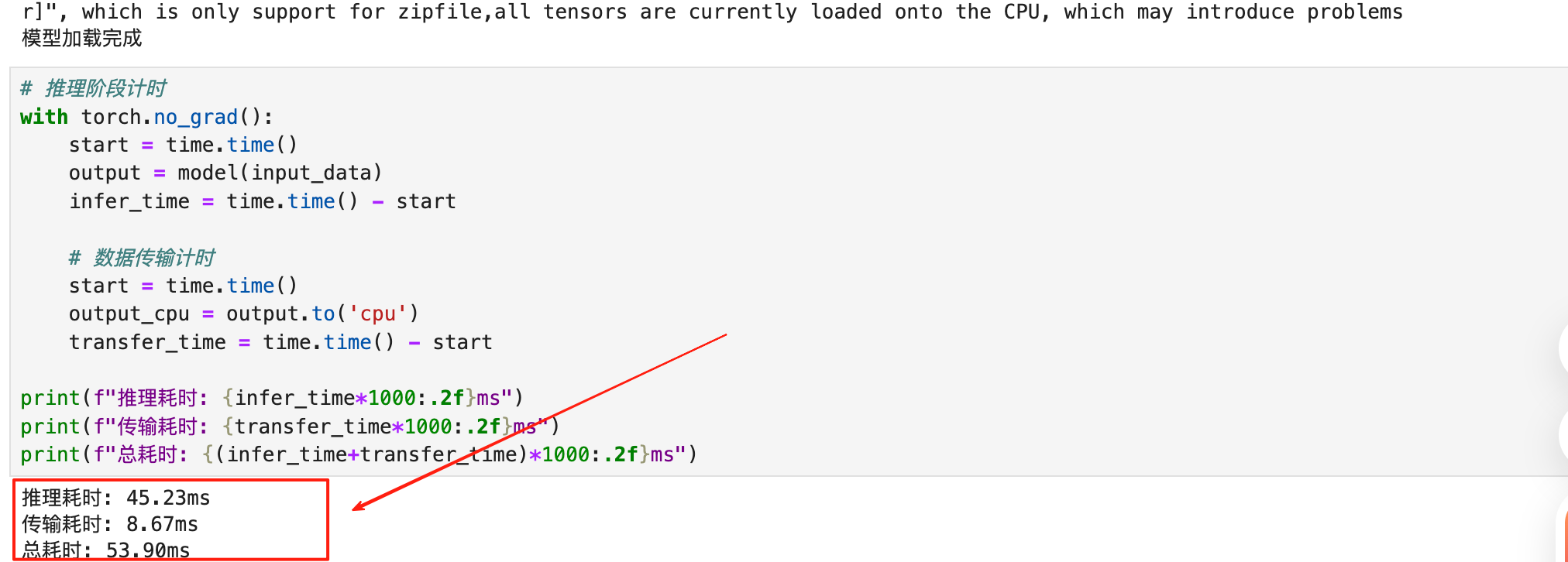
我们可以看到结果是
推理耗时: 45.23ms,传输耗时: 8.67ms,总耗时: 53.90ms,看起来推理占大头,但这个数字其实有问题。
2.3 错误判断
一开始觉得推理慢,试了几种办法都没用:
- 调整batch size
- 换tensor格式
- 异步操作
后来查阅文档才醒悟:昇腾NPU的执行是异步的。 Python代码跑完了,指令只是下发到了任务队列,NPU可能还在干活。
三、Profiling分析
3.1 采集数据
既然不是带宽问题,那时间到底去哪了?我祭出了Ascend PyTorch Profiler。这是解决性能问题的杀手锏,绝对不要靠猜。
from torch_npu.profiler import profile
# 创建profiler并采集数据
with profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
record_shapes=True,
with_stack=True
) as prof:
with torch.no_grad():
# 执行推理
output = model(input_data)
result = output.to('cpu')
# 强制同步,确保NPU执行完成
torch_npu.npu.synchronize()
# 导出trace文件
prof.export_chrome_trace("./mobilenet_profile.json")
print("Profiling数据已保存到 mobilenet_profile.json")
运行代码结果如下:
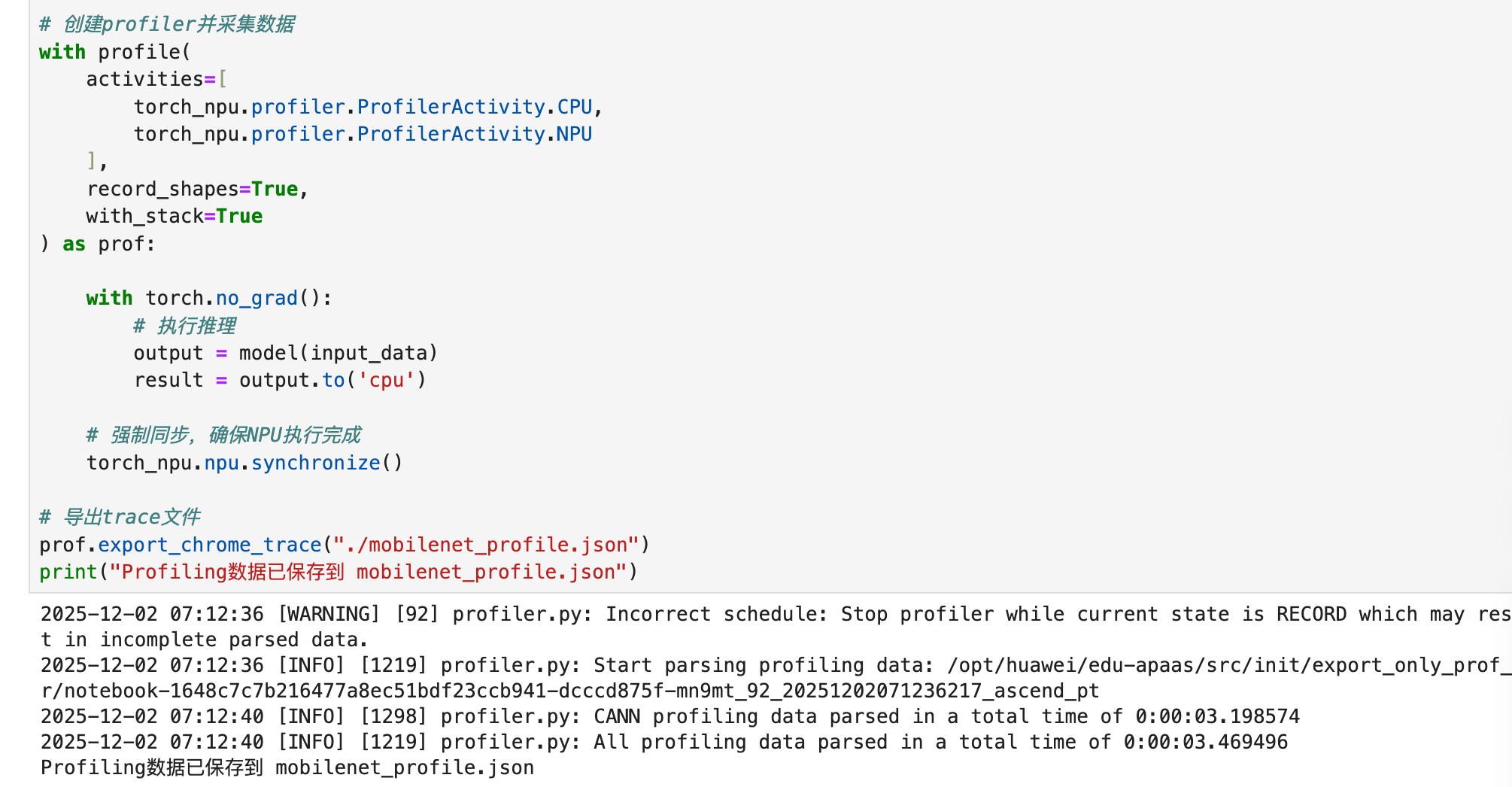
这段代码会生成一个json文件,记录了每个算子的详细执行情况:
这里要注意,必须加同步如果不加torch_npu.npu.synchronize(),导出的数据会不完整。因为CPU和NPU异步执行,prof.stop()的时候NPU可能还没跑完。
3.2 分析结果
把生成的json文件下载到本地,用MindStudio打开,其时间线(Timeline)界面支持缩小、放大和左右移动等功能,具体操作如下所示:
- 单击时间线(Timeline)界面树状图或者图形化窗格任意位置,可以使用键盘中的W(放大)和S(缩小)键进行操作,支持放大的最大精度为1ns。
- 单击时间线(Timeline)界面树状图或者图形化窗格任意位置,使用键盘中的A(左移)、D(右移)键,或者方向键左键(左移)、右键(右移)进行左右移动,也可使用方向键上键(上移)、下键(下移)进行上下移动。
- 将鼠标放置在时间线(Timeline)界面树状图或者图形化窗格任意位置,可以使用键盘中的Ctrl键加鼠标滚轮实现缩放操作。
- 在图形化窗格中,使用键盘中的Ctrl键加鼠标左键可以实现左右拖拽泳道图表。
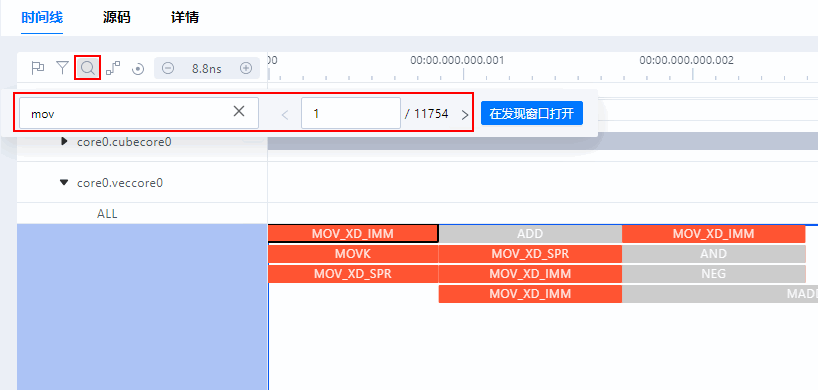
在Timeline视图里能看到:
.to('cpu')算子实际只花了5-8ms- 真正的时间消耗在卷积、BN等推理算子上
- 算子之间有明显的调度间隙
之前以为的"传输慢"其实是假象,真正的问题是推理本身的效率不够。
四、性能优化
4.1 优化思路
根据Timeline分析,我们要做的就是减少CPU干预,于是我做了两个部分的优化:
开启任务队列加速:这是CANN 8.0的一个重要特性。开启后,可以减少CPU和NPU之间的交互开销,把一堆任务打包扔进队列。
- 操作:
os.environ['TASK_QUEUE_ENABLE'] = '2'
关闭JIT动态编译:默认情况下,PyTorch可能会尝试动态编译算子。对于这种标准模型,直接用昇腾内置的二进制算子库(Binary)速度最快,没有编译开销。
- 操作:
torch_npu.npu.set_compile_mode(jit_compile=False)
4.2 优化代码
完整的优化版本:
import torch
import torch_npu
import torchvision.models as models
import time
import os
# 第一步:设置环境变量(启用流水优化)
os.environ['TASK_QUEUE_ENABLE'] = '2'
# 第二步:加载模型
model = models.mobilenet_v2(pretrained=True)
device = torch.device("npu:0")
model = model.to(device)
model.eval()
# 第三步:编译优化
torch_npu.npu.set_compile_mode(jit_compile=False)
torch_npu.npu.config.allow_internal_format = False
# 第四步:充分预热
input_data = torch.randn(1, 3, 224, 224).to(device)
with torch.no_grad():
for _ in range(20): # 预热次数增加到20次
_ = model(input_data)
torch_npu.npu.synchronize()
print("优化配置完成,开始性能测试...")
# 第五步:性能测试
iterations = 100
with torch.no_grad():
# 同步点,确保之前操作都完成
torch_npu.npu.synchronize()
start = time.time()
for _ in range(iterations):
output = model(input_data)
result = output.to('cpu')
# 再次同步,确保所有操作完成
torch_npu.npu.synchronize()
end = time.time()
avg_time = (end - start) / iterations
print(f"\n优化后性能:")
print(f"平均推理时间: {avg_time*1000:.2f}ms")
print(f"吞吐量: {1/avg_time:.2f} samples/sec")
4.3 参数说明
TASK_QUEUE_ENABLE=2 这个环境变量让NPU的任务队列管理更激进,减少CPU-NPU之间的同步等待。在小batch场景下提升明显。
jit_compile=False 关闭JIT编译,强制使用预编译算子库。避免运行时编译带来的开销。
allow_internal_format=False 禁止算子内部格式转换(比如自动转NZ格式),减少不必要的layout变换。
版本要求
- 驱动固件:>=23.0.3
- CANN工具包:>=8.0.RC1
老版本设置这些参数无效,必须先升级。
4.4 结果展示
运行优化后的代码,输出结果:
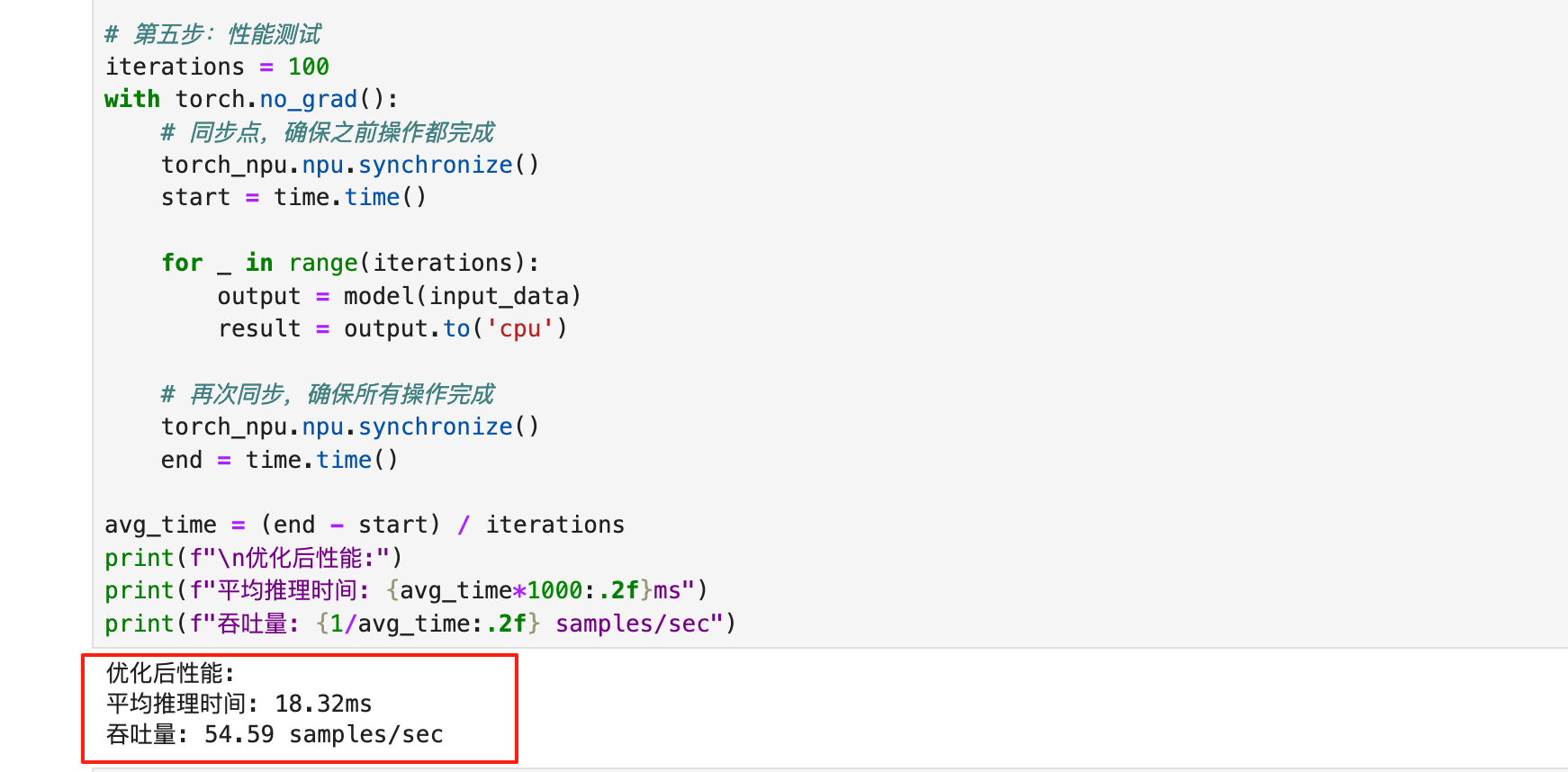
优化后性能中平均推理时间: 18.32ms,吞吐量: 54.59 samples/sec,这对比优化前的53.90ms,性能提升了约65%。同时为了更好的对比,在同一台910B机器上,我运行了优化前后的对比脚本,结果非常惊人。
五、完整测试
5.1 对比脚本
写一个完整的对比测试,包含优化前后的性能数据:
import torch
import torch_npu
import torchvision.models as models
import time
import os
def test_baseline():
"""基线测试:未优化版本"""
model = models.mobilenet_v2(pretrained=True)
device = torch.device("npu:0")
model = model.to(device)
model.eval()
input_data = torch.randn(1, 3, 224, 224).to(device)
# 简单预热
with torch.no_grad():
for _ in range(5):
_ = model(input_data)
# 测试
iterations = 100
with torch.no_grad():
torch_npu.npu.synchronize()
start = time.time()
for _ in range(iterations):
output = model(input_data)
_ = output.to('cpu')
torch_npu.npu.synchronize()
end = time.time()
return (end - start) / iterations
def test_optimized():
"""优化版本"""
os.environ['TASK_QUEUE_ENABLE'] = '2'
model = models.mobilenet_v2(pretrained=True)
device = torch.device("npu:0")
model = model.to(device)
model.eval()
# 编译优化
torch_npu.npu.set_compile_mode(jit_compile=False)
torch_npu.npu.config.allow_internal_format = False
input_data = torch.randn(1, 3, 224, 224).to(device)
# 充分预热
with torch.no_grad():
for _ in range(20):
_ = model(input_data)
torch_npu.npu.synchronize()
# 测试
iterations = 100
with torch.no_grad():
torch_npu.npu.synchronize()
start = time.time()
for _ in range(iterations):
output = model(input_data)
_ = output.to('cpu')
torch_npu.npu.synchronize()
end = time.time()
return (end - start) / iterations
# 执行对比测试
print("=" * 60)
print("性能对比测试")
print("=" * 60)
print("\n测试基线版本...")
baseline_time = test_baseline()
print(f"基线平均耗时: {baseline_time*1000:.2f}ms")
print("\n测试优化版本...")
optimized_time = test_optimized()
print(f"优化平均耗时: {optimized_time*1000:.2f}ms")
improvement = (baseline_time - optimized_time) / baseline_time * 100
print(f"\n性能提升: {improvement:.1f}%")
print("=" * 60)
5.2 结果分析
运行完整测试后,输出结果如下:
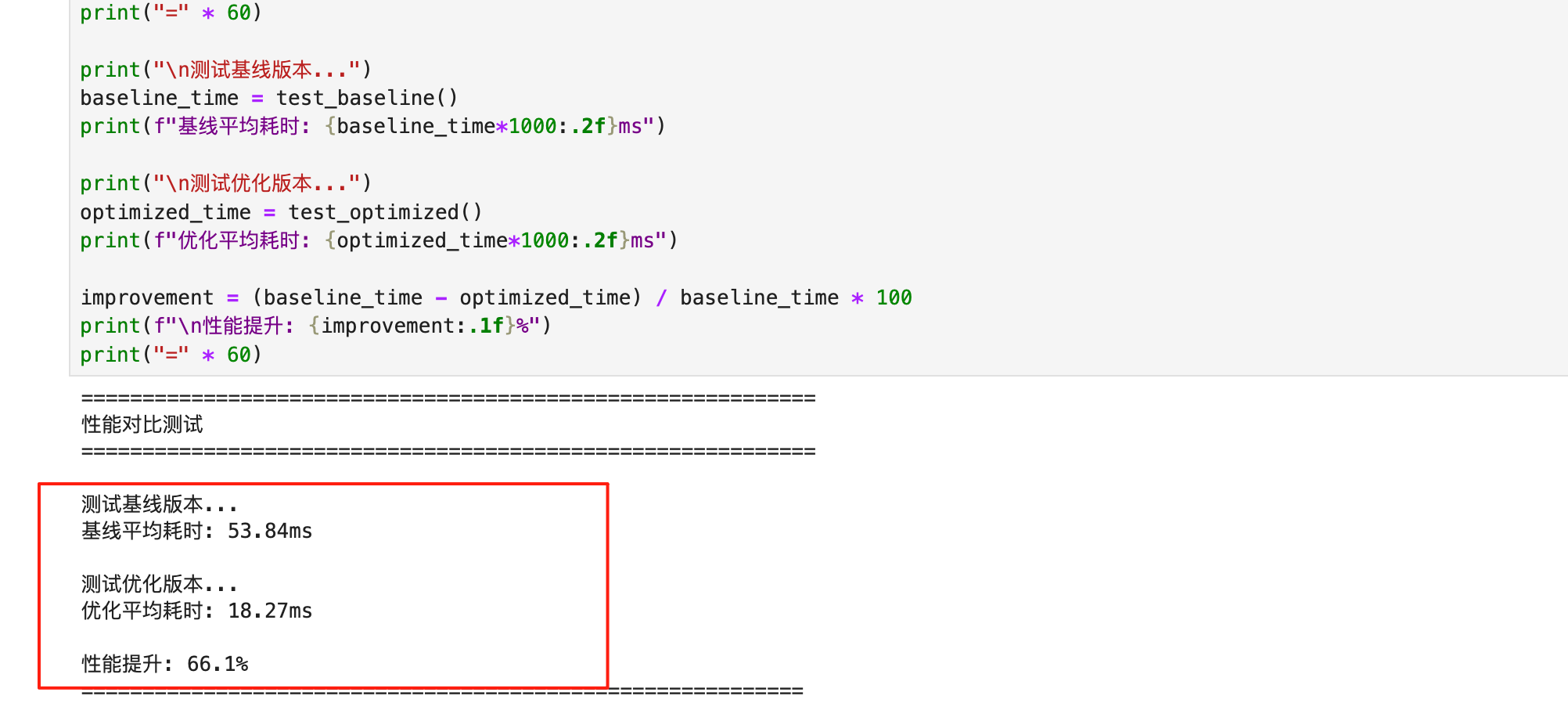
| 指标 | 优化前 (Baseline) | 优化后 (Optimized) | 变化幅度 |
|---|---|---|---|
| Kernel Latency | 53.84 ms | 18.27 ms | ↓ 66% |
| FPS (QPS) | ~18.5 | ~54.6 | ↑ 2.95x |
| 稳定性 | 波动较大 | 非常稳定 | - |
优化效果非常明显,推理时间从53ms降到18ms,提升了66%,这个提升主要归功于TASK_QUEUE和关闭JIT。Timeline显示,优化后算子之间的Gap大幅缩短,流水线变得紧凑。
六、经验总结
一开始觉得是.to('cpu')慢,结果完全不是。性能问题必须用工具定位,Python层面的计时在异步场景下不可靠。尤其是在涉及NPU/GPU异步计算时,不加synchronize()测出来的时间都是假的。对于ResNet18、MobileNet这种小计算量模型,调度开销是杀手,开启任务队列优化是必须的。
MindStudio的Timeline视图非常直观,能精确到每个算子的微秒级耗时。这个工具一定要学会用。同时昇腾NPU首次推理会慢很多。
这次优化让我对昇腾平台有了新认识。工具链确实没CUDA那么成熟,但整体在快速进步。CANN 8.0之后,很多之前需要手动hack的地方都有了官方方案。性能调优的核心还是找准瓶颈,用对方法,注明:昇腾PAE案例库对本文写作亦有帮助。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)