
基于华为昇腾AI的全栈开发实践:从芯片到应用的落地指南
摘要: 华为昇腾AI提供从芯片到应用的全栈智能计算解决方案,基于昇腾910B/310B芯片、MindSpore框架和Atlas硬件平台,实现高效AI开发与部署。本文以CIFAR-10图像分类为例,展示昇腾开发全流程:环境搭建(驱动、MindSpore、ACL安装)、ResNet18模型训练(自动调用昇腾算力优化)及推理部署。开发者可通过昇腾AI的四层架构和开源工具链快速实现智能应用落地,覆盖制造、
基于华为昇腾AI的全栈开发实践:从芯片到应用的落地指南
引言
在人工智能产业化加速的浪潮中,算力底座的性能与生态完整性直接决定了AI应用的落地效率。华为昇腾AI(hiascend.com)作为全栈全场景智能计算解决方案,通过“芯片-框架-平台-应用”的四层架构,构建了从底层硬件到上层业务的端到端技术闭环。本文将结合昇腾AI的核心技术特性、开发实战案例及生态优势,为开发者提供一份可直接落地的昇腾AI开发指南,助力快速上手智能应用开发。
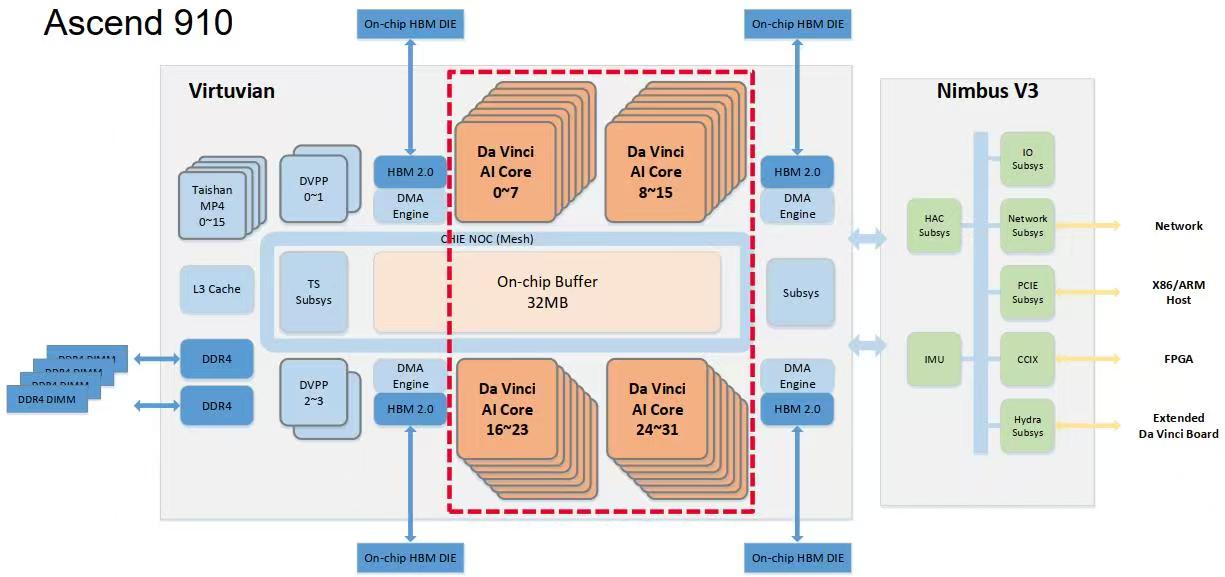
一、昇腾AI全栈架构解析
华为昇腾AI的核心竞争力在于全栈协同优化,各层级无缝衔接,最大化释放硬件算力:
-
芯片层:昇腾910B(云端训练)、昇腾310B(边缘推理)等处理器采用达芬奇架构,支持INT8/FP16/FP32多精度计算,算力密度与能效比行业领先,满足不同场景的算力需求;
-
-
框架层:MindSpore全场景AI框架提供统一API,支持昇腾芯片原生优化,实现训练与推理的一键切换,同时兼容TensorFlow/PyTorch模型迁移;
-
平台层:昇腾AI平台(包括Atlas系列硬件)提供驱动、固件、开发工具链,支持容器化部署与分布式调度,降低开发与部署门槛;
-
应用层:昇腾AI市场提供海量预训练模型、行业解决方案,覆盖制造、医疗、交通等领域,支持开发者快速二次开发。
二、昇腾AI开发实战:MindSpore模型训练与推理
下面通过“图像分类模型训练+昇腾310B推理部署”的完整流程,展示昇腾AI的开发实践,所有代码可直接在昇腾环境中运行。
2.1 开发环境搭建
2.1.1 硬件要求
- 处理器:昇腾310B/910B芯片(或Atlas 200I DK A2开发板)
- 内存:≥16GB
- 操作系统:Ubuntu 20.04 LTS
2.1.2 软件安装(参考hiascend.com官方文档)
bash
1. 安装昇腾驱动(以Ubuntu为例)
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Drivers/Ascend%20Driver/ascend-driver-23.0.0-ubuntu20.04-x86_64.run
chmod +x ascend-driver-23.0.0-ubuntu20.04-x86_64.run
./ascend-driver-23.0.0-ubuntu20.04-x86_64.run --install
2. 安装MindSpore昇腾版本(Python 3.8+)
pip install mindspore-ascend==2.4.0
3. 安装昇腾推理引擎(ACL)
pip install aclruntime==0.8.1
2.1.3 环境验证
python
import mindspore
from mindspore import context
import aclruntime
验证MindSpore与昇腾设备适配
context.set_context(device_target=“Ascend”)
print(f"MindSpore版本:{mindspore.version}“)
print(f"设备类型:{context.get_context(‘device_target’)}”)
print(f"ACL运行时版本:{aclruntime.version}")
print(“昇腾AI开发环境搭建成功!”)
2.2 基于MindSpore的图像分类模型训练
以CIFAR-10数据集为例,使用ResNet18模型进行训练,训练过程自动调用昇腾芯片算力优化:
python
import mindspore as ms
import mindspore.nn as nn
from mindspore import dataset as ds
from mindspore.dataset.vision import Resize, Normalize, ToTensor
from mindspore.train import Model, LossMonitor, CheckpointConfig, ModelCheckpoint
from mindspore.common.initializer import Normal
1. 数据集加载与预处理
def create_dataset(data_path, batch_size=32):
# 加载CIFAR-10数据集(需提前下载)
dataset = ds.Cifar10Dataset(data_path, shuffle=True)
# 预处理管道
transform = [
Resize((224, 224)), # 缩放至224x224
ToTensor(), # 转为Tensor(C,H,W)
Normalize(mean=[0.491, 0.482, 0.447], std=[0.247, 0.243, 0.262]) # 归一化
]
dataset = dataset.map(operations=transform, input_columns="image")
dataset = dataset.map(operations=lambda x: (x.astype(ms.int32)), input_columns="label")
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
2. 定义ResNet18模型(简化版)
class ResNet18(nn.Cell):
def init(self, num_classes=10):
super(ResNet18, self).init()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, weight_init=Normal(0.02))
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 简化残差块(实际需实现完整ResNet18结构)
self.layer1 = self._make_layer(64, 64, 2)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Dense(512, num_classes, weight_init=Normal(0.02))
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or in_channels != out_channels:
downsample = nn.SequentialCell(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, weight_init=Normal(0.02)),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(nn.ResidualBlock(in_channels, out_channels, stride, downsample))
for _ in range(1, blocks):
layers.append(nn.ResidualBlock(out_channels, out_channels))
return nn.SequentialCell(*layers)
def construct(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
3. 模型训练配置
if name == “main”:
# 数据集路径(需替换为实际路径)
data_path = “./cifar-10-batches-bin”
train_dataset = create_dataset(data_path)
# 初始化模型、损失函数、优化器
net = ResNet18(num_classes=10)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
optimizer = nn.Adam(net.trainable_params(), learning_rate=0.001)
# 配置模型保存
config = CheckpointConfig(save_checkpoint_steps=1000, keep_checkpoint_max=5)
ckpt_callback = ModelCheckpoint(prefix="resnet18_cifar10", directory="./checkpoint", config=config)
# 初始化模型并训练
model = Model(net, loss_fn=loss_fn, optimizer=optimizer, metrics={"accuracy"})
print("开始在昇腾芯片上训练模型...")
model.train(epoch=10, train_dataset=train_dataset, callbacks=[LossMonitor(100), ckpt_callback], dataset_sink_mode=True)
print("模型训练完成!")
2.3 昇腾310B推理部署(基于ACL Runtime)
将训练好的模型转换为昇腾适配格式,并通过ACL Runtime进行推理部署:
python
import aclruntime as acl
import numpy as np
from PIL import Image
import mindspore as ms
from mindspore import Tensor
1. 模型转换(MindSpore模型→昇腾OM模型)
def convert_model_to_om(checkpoint_path, om_path):
# 加载训练好的模型
net = ResNet18(num_classes=10)
ms.load_checkpoint(checkpoint_path, net=net)
# 构建输入Tensor(适配模型输入格式)
input_tensor = Tensor(np.ones((1, 3, 224, 224), dtype=np.float32))
# 导出ONNX模型
ms.export(net, input_tensor, file_name="resnet18_cifar10.onnx", file_format="ONNX")
# 使用atc工具转换为OM模型(昇腾专用格式)
import os
atc_cmd = f"atc --model=resnet18_cifar10.onnx --framework=5 --output={om_path} --input_format=NCHW --input_shape=input:1,3,224,224 --log=error"
os.system(atc_cmd)
print(f"OM模型已保存至:{om_path}")
2. 昇腾310B推理执行
def ascend_inference(om_path, image_path):
# 初始化ACL环境
acl.init()
device_id = 0
context, ret = acl.create_context(device_id)
assert ret == 0, “创建ACL上下文失败”
# 加载OM模型
model = acl.Model(om_path)
model.load()
# 图像预处理
image = Image.open(image_path).convert("RGB")
image = image.resize((224, 224))
image = np.array(image).astype(np.float32) / 255.0
image = (image - [0.491, 0.482, 0.447]) / [0.247, 0.243, 0.262]
image = image.transpose((2, 0, 1)) # HWC→NCHW
image = np.expand_dims(image, axis=0)
# 准备输入输出数据
input_data = acl.create_data_buffer(image.tobytes(), image.nbytes)
input_desc = acl.create_tensor_desc(acl.DT_FLOAT32, (1, 3, 224, 224), acl.NCHW)
outputs = model.execute([(input_desc, input_data)])
# 解析输出结果
output_data = acl.get_data_buffer_addr(outputs[0][1])
output = np.frombuffer(output_data, dtype=np.float32).reshape((1, 10))
pred_label = np.argmax(output, axis=1)[0]
# 释放资源
acl.destroy_data_buffer(input_data)
acl.destroy_tensor_desc(input_desc)
model.unload()
acl.destroy_context(context)
acl.finalize()
return pred_label
3. 推理实战
if name == “main”:
# 模型转换(仅需执行一次)
convert_model_to_om(“./checkpoint/resnet18_cifar10-10_1000.ckpt”, “resnet18_cifar10.om”)
# 执行推理
image_path = "test_image.jpg" # 测试图像路径
pred_label = ascend_inference("resnet18_cifar10.om", image_path)
print(f"推理结果:预测标签为 {pred_label}(对应CIFAR-10类别)")
2.4 代码核心说明
- 模型转换:通过 atc 工具将MindSpore模型转为昇腾OM格式,充分利用硬件加速特性;
- ACL Runtime:昇腾推理核心接口,提供环境初始化、模型加载、数据传输、推理执行的全流程支持;
- 全栈优化:训练阶段通过MindSpore的昇腾原生优化提升算力利用率,推理阶段通过OM模型和ACL接口实现低延迟部署。
三、昇腾AI生态与资源支持
华为昇腾AI为开发者提供了全方位的生态支持,降低开发门槛:
- 昇腾开发者社区(hiascend.com/developer):提供技术文档、教程、问题答疑、案例分享,支持在线交流;
- Atlas开发板:提供Atlas 200I DK A2等低成本开发硬件,方便开发者本地调试;
- ModelZoo:包含数千个预训练模型(覆盖CV、NLP、语音等领域),支持直接迁移使用;
- 技术培训与认证:提供昇腾AI工程师认证课程,助力开发者提升专业技能。
结尾
华为昇腾AI通过全栈协同的技术架构,为AI应用开发提供了从底层算力到上层工具的一站式解决方案。本文通过完整的开发实战案例,展示了从环境搭建、模型训练到推理部署的全流程,代码可直接应用于实际项目。随着昇腾AI生态的持续完善,越来越多的行业场景将受益于其高效的算力输出和便捷的开发体验。
对于开发者而言,昇腾AI不仅是一个计算平台,更是一个创新生态——无论是学生、科研人员还是企业开发者,都能在其中找到适合自己的开发工具和资源。未来,昇腾AI将持续推动人工智能技术的工业化落地,为千行百业的智能化升级注入新动能。
如果你需要进一步优化代码性能、获取特定行业的昇腾AI解决方案案例,或者想了解模型迁移的详细步骤,我可以为你提供更针对性的支持,需要我帮你补充这些内容吗?
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)