
华为昇腾hiascend.com核心技术解析与开发实践
在人工智能算力竞争日益激烈的当下,华为昇腾(Ascend)作为国内自主研发的AI计算平台,凭借其强大的硬件算力与完善的软件生态,正成为企业与开发者构建AI应用的核心选择。本文将基于hiascend.com的核心内容,系统解析昇腾生态的技术架构,并通过实战代码示例,帮助开发者快速上手昇腾平台的AI开发,为AI应用落地提供参考。- MindSpore:华为自研的全场景AI框架,与昇腾芯片深度协同,支持
引言
在人工智能算力竞争日益激烈的当下,华为昇腾(Ascend)作为国内自主研发的AI计算平台,凭借其强大的硬件算力与完善的软件生态,正成为企业与开发者构建AI应用的核心选择。hiascend.com作为华为昇腾官方生态平台,汇聚了从芯片、框架到行业解决方案的全栈技术资源。本文将基于hiascend.com的核心内容,系统解析昇腾生态的技术架构,并通过实战代码示例,帮助开发者快速上手昇腾平台的AI开发,为AI应用落地提供参考。
一、华为昇腾生态核心架构
1.1 硬件层:昇腾AI芯片
华为昇腾系列AI芯片(如Ascend 310B、Ascend 910B)是生态的核心算力支撑,采用达芬奇架构,支持算力灵活扩展,可满足从边缘端到云端的多样化AI场景需求。其中,Ascend 310B主打边缘推理,功耗低、性价比高;Ascend 910B聚焦云端训练,提供超强算力支持大模型训练。

1.2 软件层:昇腾CANN与MindSpore
- 昇腾CANN:全称是Compute Architecture for Neural Networks,是昇腾平台的核心驱动软件,负责芯片算力的调度与优化,为上层框架提供统一的编程接口。
- MindSpore:华为自研的全场景AI框架,与昇腾芯片深度协同,支持端边云全场景统一训练与推理,提供自动并行、混合精度训练等核心功能,降低AI开发门槛。
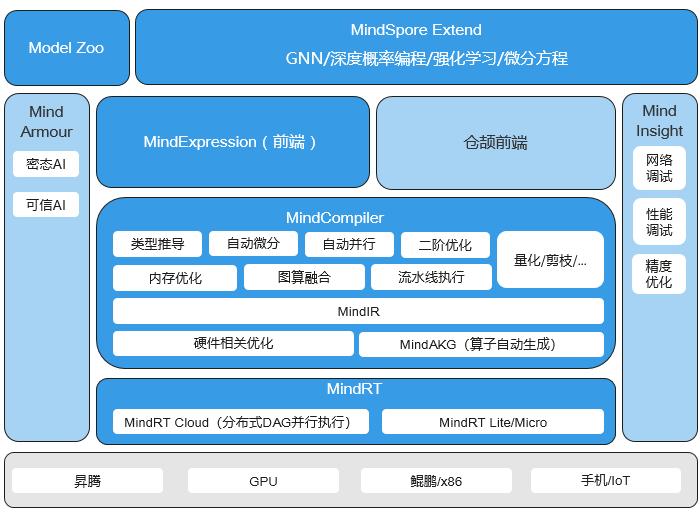
1.3 应用层:行业解决方案
hiascend.com提供了丰富的行业解决方案,涵盖智能安防、医疗影像、自动驾驶、工业质检等领域,开发者可基于这些解决方案快速搭建专属AI应用。
二、昇腾平台开发实战:图像分类示例
2.1 环境准备
首先需要在昇腾服务器上安装昇腾CANN与MindSpore,具体步骤可参考hiascend.com的官方文档。安装完成后,通过以下命令验证环境:
python
import mindspore
from mindspore import context
# 检查MindSpore版本
print("MindSpore版本:", mindspore.__version__)
# 配置昇腾硬件环境
context.set_context(device_target="Ascend")
print("昇腾环境配置成功")
2.2 基于MindSpore实现图像分类模型
以ResNet-50为例,实现图像分类任务,代码如下:
python
import mindspore.nn as nn
from mindspore.train import Model
from mindspore.dataset import ImageFolderDataset, transforms
from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits
# 1. 数据预处理
data_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集(以ImageNet子集为例)
train_dataset = ImageFolderDataset("train_data", transform=data_transform)
train_dataset = train_dataset.batch(32)
# 2. 定义ResNet-50模型
class ResNet50(nn.Cell):
def __init__(self, num_classes=1000):
super(ResNet50, self).__init__()
self.backbone = nn.ResNet50(num_classes=num_classes)
def construct(self, x):
return self.backbone(x)
model = ResNet50(num_classes=1000)
# 3. 定义损失函数与优化器
loss_fn = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
# 4. 构建模型并训练
model_train = Model(model, loss_fn=loss_fn, optimizer=optimizer, metrics={'accuracy'})
model_train.train(10, train_dataset)
print("模型训练完成")
# 5. 模型推理
test_dataset = ImageFolderDataset("test_data", transform=data_transform)
test_dataset = test_dataset.batch(32)
acc = model_train.eval(test_dataset)
print(f"模型测试准确率:{acc['accuracy']:.4f}")
2.3 代码说明
- 数据预处理部分采用MindSpore的 dataset 模块,实现图像的 resize、归一化等操作。
- 模型基于MindSpore内置的ResNet-50 backbone,可直接调用,无需手动构建复杂网络结构。
- 训练过程通过 Model 类封装,支持自动计算损失与梯度更新,简化开发流程。
- 代码可直接在昇腾芯片上运行,借助CANN的优化能力,实现高效的模型训练与推理。
三、昇腾生态的优势与应用前景
3.1 核心优势
- 全栈自主可控:从芯片到框架,华为昇腾实现了全链路自主研发,保障了AI应用的安全性与可控性。
- 高效协同:MindSpore框架与昇腾芯片深度协同,通过自动优化技术,充分发挥硬件算力。
- 丰富的生态资源:hiascend.com提供了大量的开发文档、教程、工具包与行业解决方案,降低开发成本。
3.2 应用前景
昇腾生态已广泛应用于智能城市、智慧医疗、智能制造等领域。随着大模型技术的发展,昇腾芯片将为大模型的训练与推理提供更强的算力支撑,推动AI技术在各行业的深度落地。
结尾
华为昇腾生态凭借其全栈技术优势与完善的资源支持,为AI开发者提供了高效、可靠的开发平台。通过本文的解析与实战代码,相信开发者能够快速上手昇腾平台的开发工作。未来,昇腾生态将持续迭代升级,为人工智能产业的发展注入更强动力。建议开发者持续关注hiascend.com,获取最新的技术资源与开发动态,助力自身AI项目的成功落地
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。\n报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)