
【昇腾CANN训练营·服务化篇】打破“排队”魔咒:用 MindIE 打造企业级 LLM 推理服务
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在 ACL 离线推理跑通 ResNet 后,很多人试图用同样的方法部署 LLaMA,结果发现显存利用率极低,并发一高就崩。本文将揭示 LLM 推理与传统 CV 推理的本质区别,深度解析 MindIE 的 Continuous Batching 与 PagedAttention 技术,并手把手带你搭建一个兼容 OpenAI 接口的高性能推理服务。
前言:从“静态拼车”到“动态流水线”
在上一期 ACL 部署篇中,我们将模型转为 .om 离线模型,设置固定的 Batch Size(例如 8),这在 CV 领域非常高效。但在 LLM 时代,这种 Offline Inference(离线推理) 模式遇到了巨大的挑战。
LLM 的两个痛点:
-
长度不一:用户的输入有的只有 5 个 Token,有的长达 2000 个 Token。
-
生成未知:你永远不知道模型下一句要说多少话。
如果强行用 Batch=8 跑,整个系统必须等待那个“最啰嗦”的请求生成完,其他 7 个已经生成完的请求只能陪跑。这不仅增加了用户延迟,还让昂贵的 910B 算力在等待中白白空转。
为了解决这个问题,昇腾推出了 MindIE (Mind Inference Engine) —— 对标 NVIDIA Triton + TensorRT-LLM 的大模型推理神器。
一、 核心黑科技:榨干每一滴显存
MindIE 之所以快,不是因为它算得更快,而是因为它调度得更聪明。
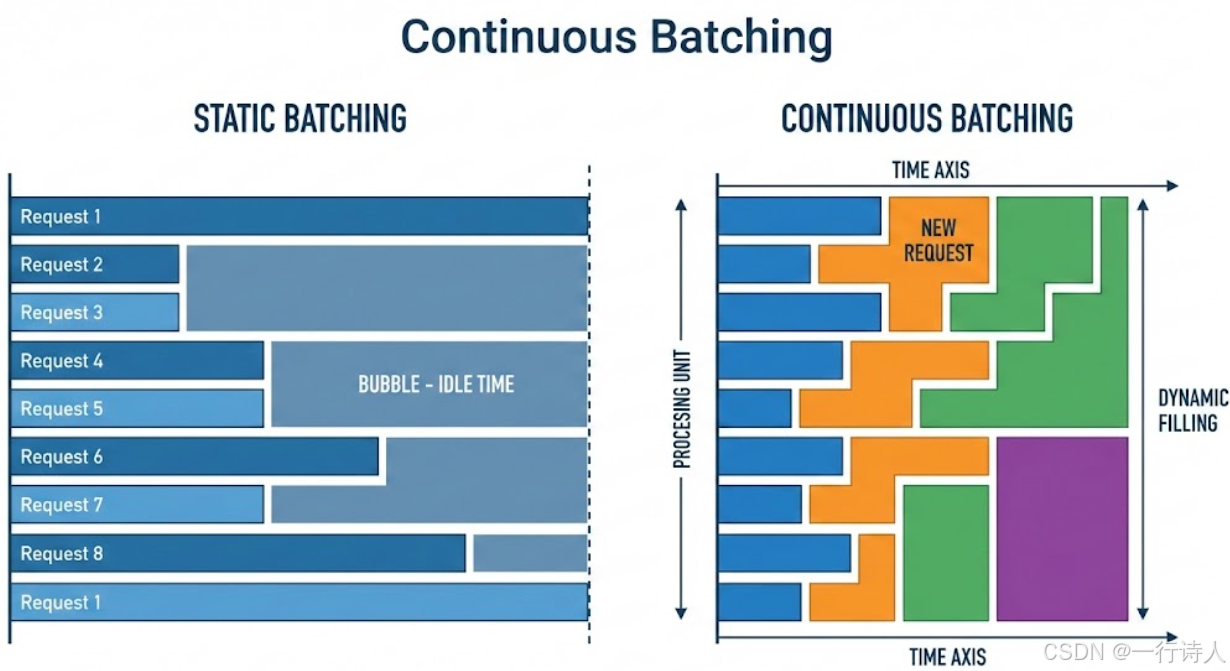
1.1 连续批处理 (Continuous Batching)
传统的 Batching 就像“坐大巴”,必须人齐了才发车,所有人到终点才停车。 MindIE 的 Continuous Batching 就像“俄罗斯方块”或“传送带”。
-
原理:当一个请求生成结束(遇到
<EOS>),它的槽位(Slot)会立刻被释放,MindIE 马上把排队中的新请求填进来,无需等待其他请求结束。 -
效果:GPU/NPU 始终处于满载状态,吞吐量提升数倍。
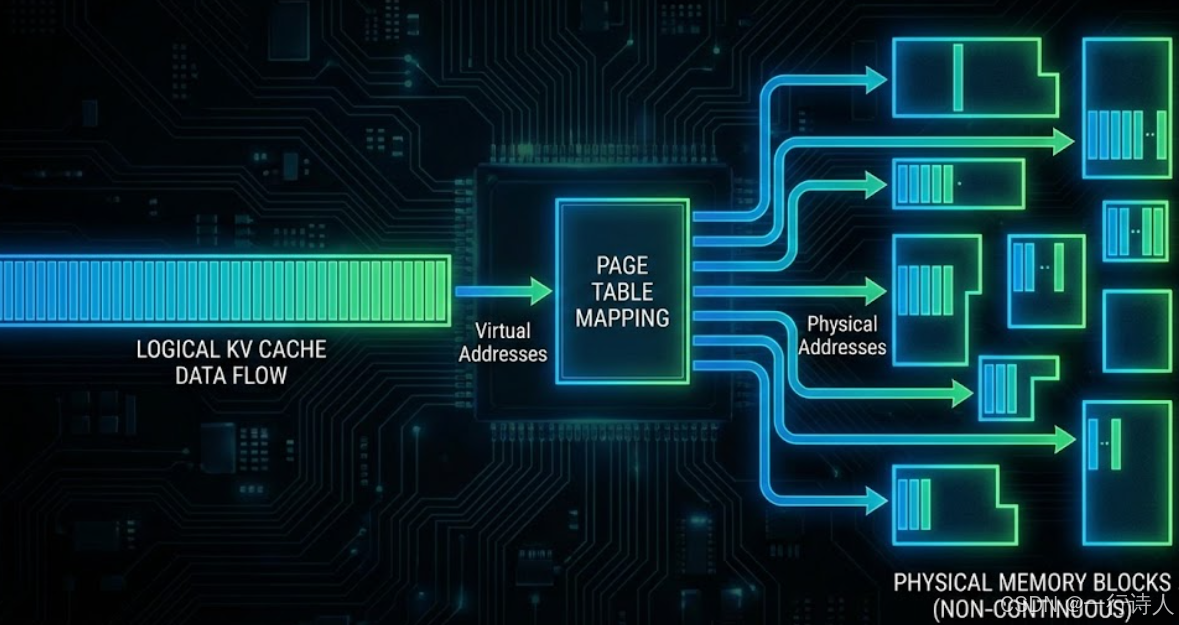
1.2 分页注意力 (PagedAttention)
LLM 推理中最大的显存杀手是 KV Cache。传统做法是按最大长度(如 4096)预分配显存,结果就是:用户只问了句“你好”,显存却占了几 GB,大量空间被浪费(Fragmentation)。
MindIE 引入了 PagedAttention,这其实就是操作系统 虚拟内存(Virtual Memory) 思想在 LLM 里的复活。
-
原理:将 KV Cache 切分成一个个小的 Block(页)。逻辑上连续的 Token,物理上可以存储在不连续的显存块中。需要多少申请多少,彻底消灭显存碎片。
二、 实战:部署 LLaMA3-8B 服务
MindIE 最让开发者舒适的一点是:它提供了标准化的服务外壳。你不需要自己写 FastAPI,不需要自己写调度器,改改配置就能用。
2.1 核心配置解析 (config.json)
不要被几百行的配置文件吓倒,核心只需要关注 ServerConfig 和 BackendConfig。
{
"ServerConfig": {
"ipAddress": "0.0.0.0",
"port": 1025, // 服务端口
"maxLinkNum": 1000 // 最大连接数
},
"BackendConfig": {
"backendName": "mindieservice_llm_engine",
"npuDeviceIds": [[0]], // 只有一张卡就写 [[0]],两张卡写 [[0,1]]
"ModelDeployConfig": {
"maxBatchSize": 64, // 显存允许的最大并发数
"ModelConfig": [
{
"modelName": "llama3_8b",
"modelWeightPath": "/data/models/llama3-8b-hf", // 原始权重路径
"npuMemSizeRatio": 0.8 // 关键!预留多少比例显存给 KV Cache
// 设置为 0.8 表示 80% 显存用于 KV Cache,越大能支持的并发/长度越高
// 但要给权重和中间激活值留足空间,否则会 OOM
}
]
}
}
}
2.2 启动与避坑
进入 MindIE 安装目录的 bin 文件夹启动服务:
cd /usr/local/Ascend/mindie/latest/bin
./mindieservice_daemon
观察日志的技巧: 启动初期你会看到大量的 Graph Compilation 日志,这是 MindIE 在做图编译优化。千万别以为卡死了,耐心等待直到出现 HTTPServer start success!。
2.3 零代码迁移:OpenAI 接口调用
MindIE Service 最大的诚意在于兼容了 OpenAI 的 v1/chat/completions 接口。这意味着你原本基于 GPT-4 开发的应用,只需要改一下 base_url 就能无缝迁移到昇腾 NPU 上。
from openai import OpenAI
# 假装我们在连 OpenAI,其实连的是本地的 910B
client = OpenAI(
api_key="EMPTY", # 本地服务不需要 Key
base_url="[http://127.0.0.1:1025/v1](http://127.0.0.1:1025/v1)",
)
# 流式输出测试
response = client.chat.completions.create(
model="llama3_8b",
messages=[
{"role": "system", "content": "你是一个昇腾技术专家"},
{"role": "user", "content": "请解释一下什么是 NPU?"}
],
stream=True # 开启流式,体验打字机效果
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
三、 进阶:自定义与 Torch 模式
除了加载标准权重,MindIE 还支持 Torch 模式。如果你的模型里包含一些特殊的、未被标准算子库覆盖的算子(比如最新的 MoE 路由算法),你可以直接通过 PyTorch 代码加载模型。
MindIE 底层会利用 Dynamo 抓取 PyTorch 的图,将其中的标准算子映射为 NPU 高性能算子,无法映射的保留在 Python 层执行。这在性能和灵活性之间取得了完美的平衡。
四、 总结
如果说 ACL 是昇腾的“C++ 刺刀”,那么 MindIE 就是“机械化步兵团”。
-
对于开发者:它屏蔽了复杂的 KV Cache 管理和多卡通信细节。
-
对于企业:它提供了开箱即用的高并发服务,直接对齐行业标准的 OpenAI 接口。
掌握了 MindIE,你就拥有了将大模型从“实验代码”转化为“生产服务”的核心能力。
本文基于 MindIE 1.0.RC2 版本撰写,更多参数调优请参考昇腾社区《MindIE Service 开发指南》。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 16
16 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)