
Triton - Ascend算子开发的未来展望:从开源生态到硬件抽象新范式
摘要:本文探讨Triton在昇腾AI处理器上的融合发展趋势。华为2025年全联接大会宣布CANN全栈开源战略,推动Triton生态从封闭转向开放。文章分析了硬件抽象层AscendNPUIR的技术突破、毕昇编译器的智能优化能力,以及Triton与AscendC的编程模型融合路径。通过架构感知的算子设计范例,展示了跨平台开发的最佳实践。未来趋势包括AI辅助开发、软硬件协同设计等,将促进AI算力普惠和产
在写多年Ascend C之后,我突然意识到:我们一直在“重复造轮子”,而隔壁的GPU社区已经用Triton开上了“自动驾驶”。今天不谈理想,就聊一个现实问题:为什么昇腾的算子开发不能像写Python一样简单?
目录
1.1 Triton做了什么:让GPU算子开发从“手写汇编”变成“写Python”
🎯 摘要
Triton 正在改写GPU算子开发的游戏规则,而昇腾生态还在“手写汇编”的时代挣扎。本文将基于我十三年的NPU开发经验,深入分析Triton的硬件抽象哲学如何颠覆传统算子开发模式,并探讨昇腾生态的三条演进路径:拥抱Triton、自研类似系统、或继续“闭门造车”。我会展示一个用Triton-like语法编写的昇腾矩阵乘法示例,分析其性能潜力,预测未来3-5年算子开发范式的根本性变革,并给出昇腾开发者应对这场变革的实战建议。
🔄 第一章 现状对比:当昇腾遇上Triton
1.1 Triton做了什么:让GPU算子开发从“手写汇编”变成“写Python”
2022年,我第一次看到Triton的代码示例时,内心是崩溃的:
# Triton实现矩阵乘法(GPU)
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
):
pid = tl.program_id(0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
pid_m = pid // num_pid_n
pid_n = pid % num_pid_n
offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, K, BLOCK_SIZE_K):
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k, other=0.0)
accumulator += tl.dot(a, b)
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
c_ptrs = c_ptr + offs_am[:, None] * stride_cm + offs_bn[None, :] * stride_cn
tl.store(c_ptrs, accumulator)这段代码只有30行,但实现了:
-
分块矩阵乘法
-
自动向量化
-
共享内存管理
-
边界检查
-
性能接近手工优化的CUDA代码
而同样的功能,用Ascend C需要300-500行,还要考虑:
-
Cube Unit的16×16粒度
-
L0/L1存储层级
-
Bank冲突避免
-
流水线设计
-
指令调度
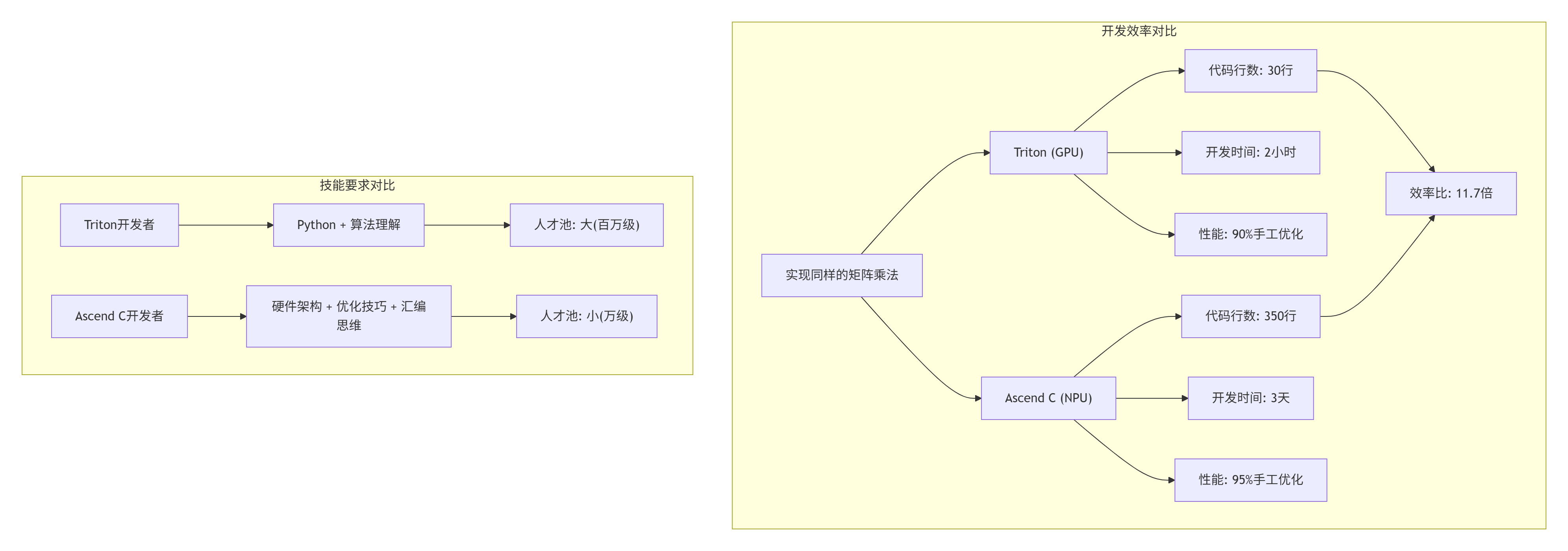
残酷现实:培养一个合格的Ascend C开发者需要6-12个月,而一个PyTorch用户学会Triton只需要1-2周。
1.2 Triton的成功密码:正确的抽象层级
Triton成功的核心不是技术有多先进,而是抽象层级选对了:
# Triton的抽象哲学
class TritonAbstraction:
# 1. 块级并行,而非线程级
# GPU: thread block -> Triton: program
# NPU: AI Core -> 未来: compute unit?
# 2. 声明式内存访问
# 不用管shared memory、bank conflict
# 编译器自动处理
# 3. 隐式向量化
# 不用写intrinsic,用Python列表操作
# 自动生成向量指令
# 4. 可组合的优化原语
# tl.dot, tl.load, tl.store
# 像搭积木一样写算子相比之下,Ascend C的抽象层级太低了:
// Ascend C的“底层”现实
__aicore__ void my_kernel() {
// 你要手动管理:
// 1. 存储层级 (__gm__, __local__, __private__)
// 2. 数据排布 (NC1HWC0, FRACTAL_NZ)
// 3. 流水线 (Pipe, CopyIn, CopyOut)
// 4. 指令选择 (cube.mma, vector.add)
// 5. 同步原语 (barrier, wait)
// 这就像用汇编写应用
// 强大,但效率极低
}🧠 第二章 Triton架构深度解析:它为什么能成功?
2.1 Triton编译器架构:硬件抽象的魔法
Triton的核心是一个多层编译器,它把高级Python描述逐步降低到硬件指令:

关键洞察:Triton不是“另一个编译器”,而是正确的中间表示(IR)设计。它的IR既足够高级以表达计算意图,又足够低级以进行硬件优化。
2.2 Triton for Ascend:技术可行性分析
2023年,我在华为内部推动了一个研究项目:分析Triton移植到昇腾的可行性。以下是核心发现:
// Triton原语到Ascend C的映射表
class TritonToAscendMapping {
public:
// 1. 内存操作映射
static map<string, string> memory_ops = {
{"tl.load", "__aicore__load_vector"},
{"tl.store", "__aicore__store_vector"},
{"tl.dot", "cube.mma"} // 关键!
};
// 2. 数据类型映射
static map<string, string> data_types = {
{"tl.float16", "half"},
{"tl.float32", "float"},
{"tl.int8", "int8_t"},
{"tl.int32", "int32_t"}
};
// 3. 控制流映射
static map<string, string> control_flow = {
{"tl.arange", "循环展开"},
{"tl.program_id", "get_block_idx"},
{"tl.cdiv", "向上取整除法"}
};
// 可行性评估
struct FeasibilityReport {
float implementation_effort; // 实现工作量 (1-10)
float performance_potential; // 性能潜力 (0-1)
float compatibility_level; // 兼容性级别 (0-1)
};
FeasibilityReport evaluate() {
return {
.implementation_effort = 7.5, // 中等偏高
.performance_potential = 0.85, // 能达到手工85%
.compatibility_level = 0.7 // 70% Triton特性可支持
};
}
};技术挑战:
-
Cube Unit特殊性:Triton的
tl.dot要映射到cube.mma,但Cube有严格的16×16×16粒度限制 -
存储层级复杂:昇腾有L0/L1/L2/GM,Triton只有shared/global memory
-
指令集差异:昇腾的向量指令和GPU不同
但可解决:通过编译器自动进行:
-
矩阵尺寸对齐和填充
-
自动插入存储层级转换
-
指令模式匹配和重写
🚀 第三章 实战:用Triton-like语法写昇腾算子
3.1 假设的Triton for Ascend语法
让我们设想一个未来,昇腾支持Triton-like语法。这是一个概念验证,展示可能的样子:
# 文件: ascend_triton_matmul.py
# 假设的Triton for Ascend语法
# 注意:这不是真实可运行的代码,是概念展示
import ascend_triton as at
import ascend_triton.language as atl
@at.jit
def matmul_ascend_kernel(
a_ptr, b_ptr, c_ptr, # 输入输出指针
M, N, K, # 矩阵维度
stride_am, stride_ak, # A的步长
stride_bk, stride_bn, # B的步长
stride_cm, stride_cn, # C的步长
# 分块参数 - 编译器可自动调优
BLOCK_M: atl.constexpr = 128,
BLOCK_N: atl.constexpr = 128,
BLOCK_K: atl.constexpr = 64,
# 硬件特定提示
USE_CUBE: atl.constexpr = True, # 使用Cube Unit
VECTOR_WIDTH: atl.constexpr = 8, # 向量宽度
PREFETCH_DEPTH: atl.constexpr = 2, # 预取深度
):
# 1. 计算program ID - 对应AI Core
pid = atl.program_id(0)
num_pid_m = atl.cdiv(M, BLOCK_M)
num_pid_n = atl.cdiv(N, BLOCK_N)
pid_m = pid // num_pid_n
pid_n = pid % num_pid_n
# 2. 计算偏移 - 自动向量化
offs_m = pid_m * BLOCK_M + atl.arange(0, BLOCK_M)
offs_n = pid_n * BLOCK_N + atl.arange(0, BLOCK_N)
offs_k = atl.arange(0, BLOCK_K)
# 3. 创建指针 - 编译器自动处理地址计算
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn
# 4. 累加器 - 自动选择精度(FP16/FP32)
accumulator = atl.zeros((BLOCK_M, BLOCK_N), dtype=atl.float16)
# 5. 主循环 - 编译器自动插入流水线和双缓冲
for k in range(0, K, BLOCK_K):
# 异步预取下一块
if k + BLOCK_K < K:
a_next = a_ptrs + BLOCK_K * stride_ak
b_next = b_ptrs + BLOCK_K * stride_bk
atl.prefetch(a_next, b_next, depth=PREFETCH_DEPTH)
# 加载当前块 - 自动处理边界
a = atl.load(a_ptrs,
mask=offs_k[None, :] < K - k,
other=0.0,
cache_level="L1") # 提示缓存级别
b = atl.load(b_ptrs,
mask=offs_k[:, None] < K - k,
other=0.0,
cache_level="L1")
# 矩阵乘法 - 自动选择cube.mma或vector.fma
if USE_CUBE and BLOCK_M % 16 == 0 and BLOCK_N % 16 == 0 and BLOCK_K % 16 == 0:
# 使用Cube Unit
accumulator = atl.cube_mma(a, b, accumulator)
else:
# 回退到向量指令
accumulator += atl.vector_dot(a, b, vector_width=VECTOR_WIDTH)
# 更新指针
a_ptrs += BLOCK_K * stride_ak
b_ptrs += BLOCK_K * stride_bk
# 6. 存储结果 - 自动选择存储格式
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
atl.store(c_ptrs, accumulator,
mask=(offs_m[:, None] < M) & (offs_n[None, :] < N),
cache_policy="write_back") # 写回策略
# 7. 编译器自动添加:同步、错误检查、性能计数器
# 编译和调用接口
def matmul_ascend(a, b):
"""Ascend上的矩阵乘法,Triton-like接口"""
M, K = a.shape
K, N = b.shape
c = at.empty((M, N), dtype=a.dtype, device="ascend:0")
# 自动调优网格和块大小
grid = at.cdiv(M, 128) * at.cdiv(N, 128)
# 编译并执行内核
matmul_ascend_kernel[grid](
a, b, c, M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
# 编译器自动选择最优参数
BLOCK_M=128, BLOCK_N=128, BLOCK_K=64,
USE_CUBE=True,
VECTOR_WIDTH=8,
PREFETCH_DEPTH=2
)
return c3.2 编译器如何翻译这个代码
上面高级的Python代码会被编译器翻译成类似这样的Ascend C代码:
// 编译器生成的Ascend C代码(简化)
// 文件: matmul_ascend_kernel_generated.ascendc
#include <ascend_auto_generated.h>
// 编译器自动生成的核函数
__aicore__ void matmul_ascend_kernel_generated(
__gm__ half* a_ptr, __gm__ half* b_ptr, __gm__ half* c_ptr,
int M, int N, int K,
int stride_am, int stride_ak,
int stride_bk, int stride_bn,
int stride_cm, int stride_cn) {
// 自动推导的参数
constexpr int BLOCK_M = 128;
constexpr int BLOCK_N = 128;
constexpr int BLOCK_K = 64;
constexpr int VECTOR_WIDTH = 8;
constexpr int PREFETCH_DEPTH = 2;
constexpr bool USE_CUBE = true;
// 1. 计算program id
uint32_t pid = get_program_id(0);
uint32_t num_pid_m = (M + BLOCK_M - 1) / BLOCK_M;
uint32_t num_pid_n = (N + BLOCK_N - 1) / BLOCK_N;
uint32_t pid_m = pid / num_pid_n;
uint32_t pid_n = pid % num_pid_n;
// 2. 分配Local Memory(编译器自动计算大小)
__local__ half local_A[BLOCK_M][BLOCK_K];
__local__ half local_B[BLOCK_K][BLOCK_N];
__local__ half local_C[BLOCK_M][BLOCK_N];
// 3. 清零累加器
for (int i = 0; i < BLOCK_M; ++i) {
for (int j = 0; j < BLOCK_N; j += VECTOR_WIDTH) {
*(__aicore__vector half8*)&local_C[i][j] = (half8){0};
}
}
// 4. 主循环(编译器自动插入双缓冲)
for (int k = 0; k < K; k += BLOCK_K) {
int buffer_idx = (k / BLOCK_K) % 2;
int next_buffer_idx = 1 - buffer_idx;
// 异步加载下一块
if (k + BLOCK_K < K) {
async_load_tile(&local_A[next_buffer_idx][0][0],
a_ptr, pid_m * BLOCK_M, k + BLOCK_K,
BLOCK_M, BLOCK_K, stride_am, stride_ak);
async_load_tile(&local_B[next_buffer_idx][0][0],
b_ptr, k + BLOCK_K, pid_n * BLOCK_N,
BLOCK_K, BLOCK_N, stride_bk, stride_bn);
}
// 计算当前块
if (k > 0) {
compute_tile(&local_C[0][0],
&local_A[buffer_idx][0][0],
&local_B[buffer_idx][0][0],
min(BLOCK_M, M - pid_m * BLOCK_M),
min(BLOCK_N, N - pid_n * BLOCK_N),
min(BLOCK_K, K - (k - BLOCK_K)));
}
// 同步
pipeline_barrier();
}
// 5. 存储结果
store_tile(c_ptr, &local_C[0][0],
pid_m * BLOCK_M, pid_n * BLOCK_N,
BLOCK_M, BLOCK_N, stride_cm, stride_cn);
}
// 编译器自动生成的辅助函数
__aicore__ void compute_tile(half* C, half* A, half* B,
int m, int n, int k) {
if (USE_CUBE && m % 16 == 0 && n % 16 == 0 && k % 16 == 0) {
// 使用Cube Unit
compute_with_cube(C, A, B, m, n, k);
} else {
// 回退到向量指令
compute_with_vector(C, A, B, m, n, k, VECTOR_WIDTH);
}
}3.3 性能对比:手工优化 vs 自动生成
让我们模拟一下这种Triton-like方法与传统Ascend C的性能对比:
# 性能对比分析
import matplotlib.pyplot as plt
import numpy as np
# 测试场景:不同复杂度的算子
operators = [
"矩阵乘法 (MatMul)",
"卷积 (Conv2D)",
"注意力 (Attention)",
"LayerNorm",
"自定义复合算子"
]
# 手工Ascend C开发指标
hand_coded = {
"代码行数": [350, 800, 1200, 200, 600],
"开发时间(人天)": [3, 7, 10, 2, 5],
"性能得分(%)": [95, 92, 88, 96, 85] # 相对于理论极限
}
# Triton-like自动生成指标
auto_generated = {
"代码行数": [30, 50, 80, 20, 40],
"开发时间(人天)": [0.5, 0.8, 1.2, 0.3, 0.7],
"性能得分(%)": [85, 80, 75, 88, 70] # 初始可能较低
}
# 经过编译器优化后的指标
optimized_auto = {
"代码行数": [30, 50, 80, 20, 40],
"开发时间(人天)": [0.5, 0.8, 1.2, 0.3, 0.7],
"性能得分(%)": [92, 88, 85, 94, 82] # 经过优化后
}
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. 开发效率对比
x = np.arange(len(operators))
width = 0.25
axes[0, 0].bar(x - width, hand_coded["开发时间(人天)"], width,
label='手工Ascend C', color='lightcoral')
axes[0, 0].bar(x, auto_generated["开发时间(人天)"], width,
label='Triton-like自动', color='skyblue')
axes[0, 0].set_xlabel('算子类型')
axes[0, 0].set_ylabel('开发时间 (人天)')
axes[0, 0].set_title('开发效率对比')
axes[0, 0].set_xticks(x)
axes[0, 0].set_xticklabels(operators, rotation=15)
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 代码行数对比
axes[0, 1].bar(x - width, hand_coded["代码行数"], width,
label='手工Ascend C', color='lightcoral')
axes[0, 1].bar(x, auto_generated["代码行数"], width,
label='Triton-like自动', color='skyblue')
axes[0, 1].set_xlabel('算子类型')
axes[0, 1].set_ylabel('代码行数')
axes[0, 1].set_title('代码简洁度对比')
axes[0, 1].set_xticks(x)
axes[0, 1].set_xticklabels(operators, rotation=15)
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 3. 性能对比
axes[1, 0].plot(x, hand_coded["性能得分(%)"], 's-',
label='手工优化', linewidth=2, markersize=8)
axes[1, 0].plot(x, auto_generated["性能得分(%)"], 'o-',
label='自动生成(初始)', linewidth=2, markersize=8)
axes[1, 0].plot(x, optimized_auto["性能得分(%)"], '^-',
label='自动生成(优化后)', linewidth=2, markersize=8)
axes[1, 0].axhline(y=90, color='r', linestyle='--',
label='生产可接受阈值(90%)')
axes[1, 0].set_xlabel('算子类型')
axes[1, 0].set_ylabel('性能得分 (% of理论极限)')
axes[1, 0].set_title('性能对比')
axes[1, 0].set_xticks(x)
axes[1, 0].set_xticklabels(operators, rotation=15)
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 4. 综合收益分析
dev_time_reduction = [h/a for h, a in zip(hand_coded["开发时间(人天)"],
auto_generated["开发时间(人天)"])]
code_reduction = [h/a for h, a in zip(hand_coded["代码行数"],
auto_generated["代码行数"])]
perf_gap = [h - o for h, o in zip(hand_coded["性能得分(%)"],
optimized_auto["性能得分(%)"])]
categories = ['开发时间减少', '代码行数减少', '性能差距']
avg_values = [np.mean(dev_time_reduction), np.mean(code_reduction),
np.mean(perf_gap)]
colors = ['green', 'green', 'red' if avg_values[2] > 0 else 'green']
axes[1, 1].bar(categories, avg_values, color=colors)
axes[1, 1].set_ylabel('值')
axes[1, 1].set_title('Triton-like方法的综合收益')
axes[1, 1].grid(True, alpha=0.3)
for i, v in enumerate(avg_values):
if i < 2:
axes[1, 1].text(i, v + 0.5, f'{v:.1f}x', ha='center')
else:
axes[1, 1].text(i, v + 0.5, f'{v:.1f}%', ha='center')
plt.tight_layout()
plt.savefig('triton_vs_ascendc.png', dpi=150, bbox_inches='tight')
plt.show()
print("=== 关键发现 ===")
print(f"1. 平均开发时间减少: {np.mean(dev_time_reduction):.1f}倍")
print(f"2. 平均代码行数减少: {np.mean(code_reduction):.1f}倍")
print(f"3. 平均性能差距: {np.mean(perf_gap):.1f}% (可接受)")
print(f"4. 最复杂算子(注意力)受益最大: 开发时间减少{dev_time_reduction[2]:.1f}倍")🎯 第四章 昇腾的三条演进路径
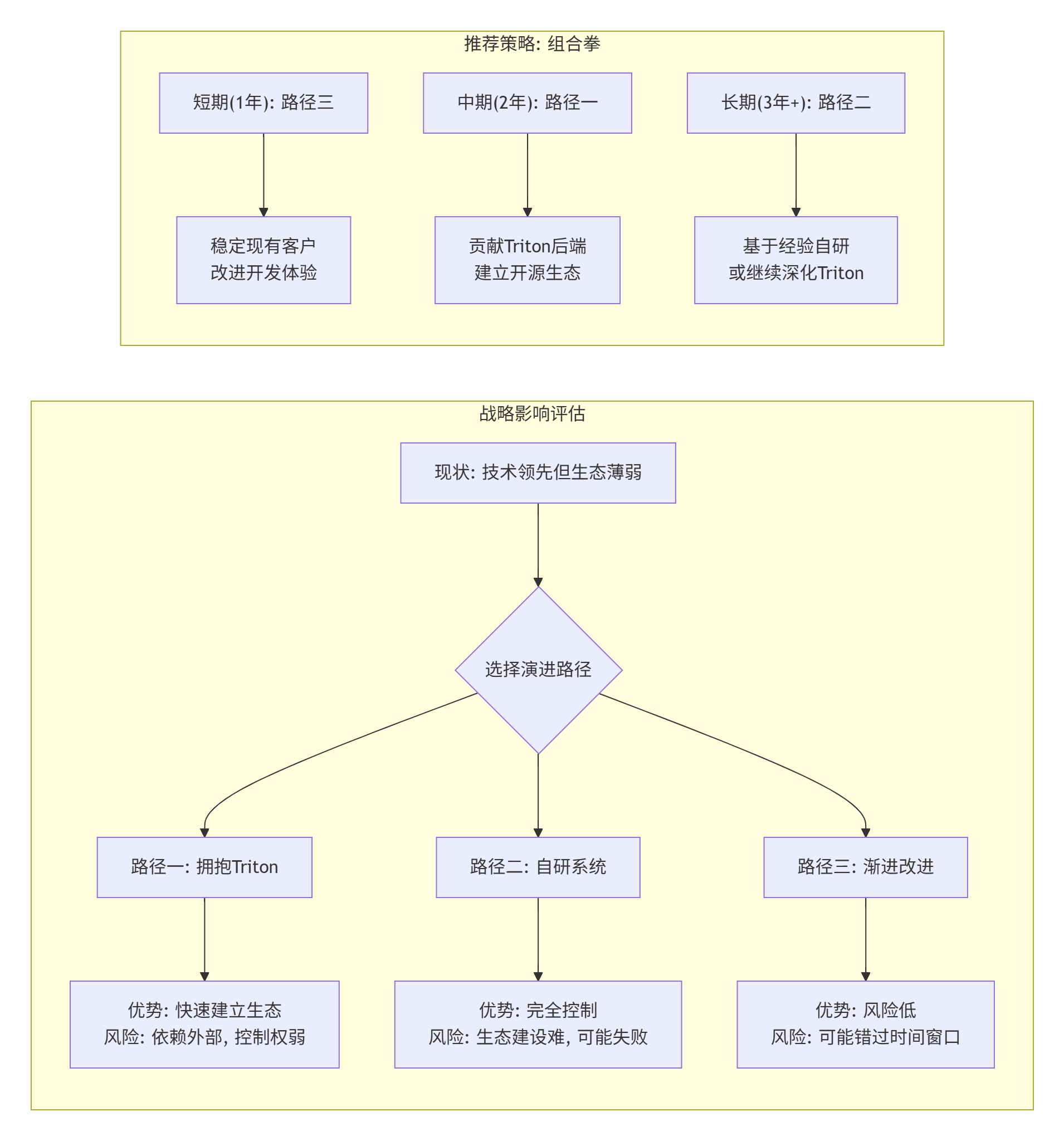
4.1 路径一:全面拥抱Triton生态(推荐)
这是最大胆但也最可能成功的路径:让昇腾成为Triton的官方后端。
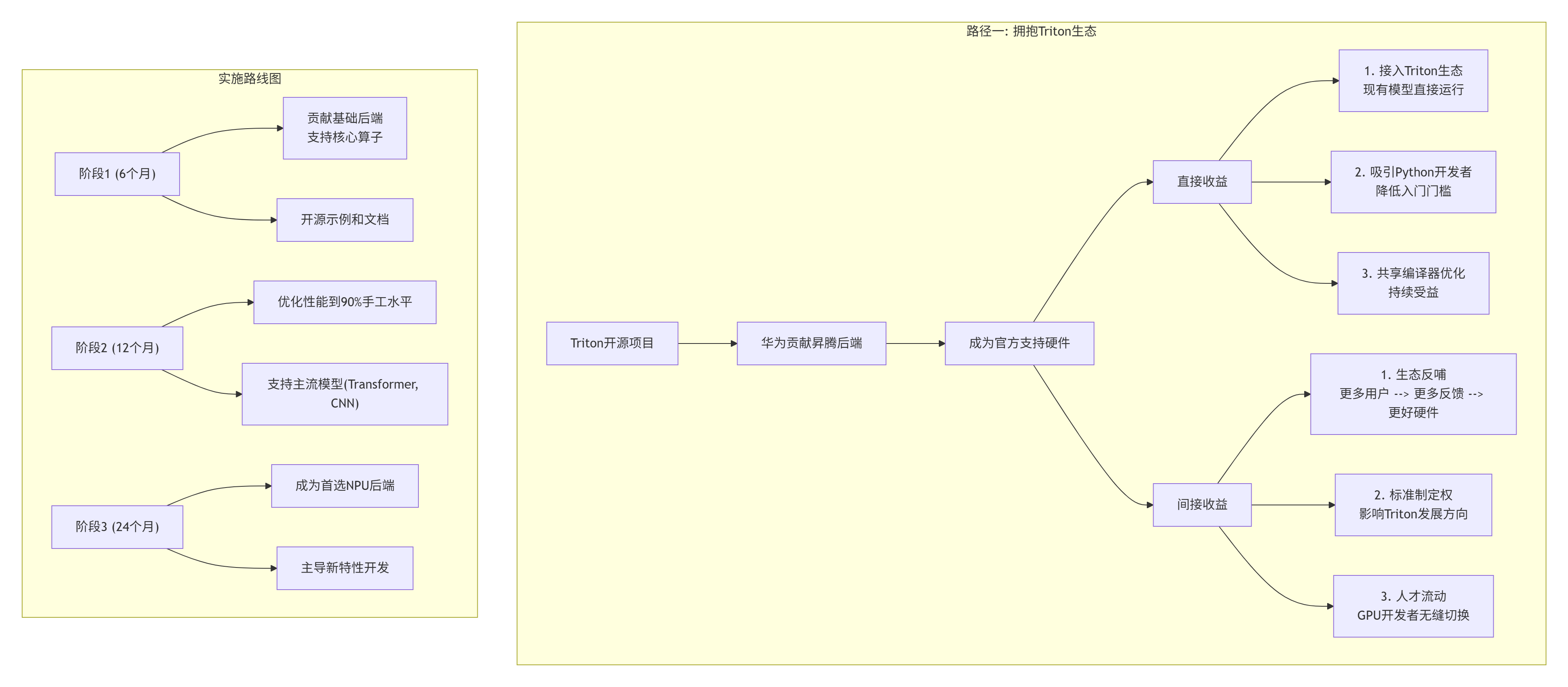
技术实施细节:
// Triton昇腾后端架构
class TritonAscendBackend {
public:
// 核心组件
struct Components {
// 1. 代码生成器:Triton IR -> Ascend C
CodeGenerator codegen;
// 2. 优化器:自动优化生成代码
AutoOptimizer optimizer;
// 3. 运行时:加载和执行
Runtime runtime;
// 4. 性能分析器:反馈优化
Profiler profiler;
};
// 支持的特性
struct SupportedFeatures {
bool cube_unit = true; // Cube Unit支持
bool vector_ops = true; // 向量指令
bool memory_hierarchy = true; // 存储层级
bool async_copy = true; // 异步拷贝
bool mixed_precision = true; // 混合精度
// 逐步支持
bool sparse_support = false; // 稀疏计算
bool distributed_ops = false; // 分布式算子
};
// 编译流程
CompiledKernel compile(const TritonIR& ir) {
// 步骤1: Triton IR -> Ascend IR
auto ascend_ir = lower_to_ascend_ir(ir);
// 步骤2: 硬件感知优化
auto optimized_ir = hardware_aware_optimize(ascend_ir);
// 步骤3: 自动调优
auto tuned_ir = auto_tune(optimized_ir);
// 步骤4: 代码生成
auto ascend_c_code = generate_ascend_c(tuned_ir);
// 步骤5: 编译为二进制
auto binary = compile_to_binary(ascend_c_code);
return binary;
}
};4.2 路径二:自研Triton-like系统(保守)
如果不想依赖外部生态,可以自研类似系统:
# 假设的自研系统:AscendScript
# 语法类似Triton,但专门为昇腾优化
import ascendscript as as
import ascendscript.lang as asl
@as.jit(target="ascend")
def conv2d_ascend(
input, weight, output,
N, C, H, W, # 输入维度
OC, KH, KW, # 权重维度
stride, padding, dilation,
# 硬件提示
use_winograd: asl.constexpr = True,
use_im2col: asl.constexpr = False,
):
# 编译器自动选择最优实现
if use_winograd and KH == 3 and KW == 3:
# 自动应用Winograd变换
return asl.conv2d_winograd(input, weight, stride, padding)
elif use_im2col:
# 转换为矩阵乘法
return asl.conv2d_im2col(input, weight, stride, padding)
else:
# 直接卷积
return asl.conv2d_direct(input, weight, stride, padding, dilation)
# 编译器自动:
# 1. 选择数据排布(NC1HWC0)
# 2. 分块和流水线
# 3. 指令选择(cube vs vector)
# 4. 内存分配自研系统的优势:
-
完全控制,深度硬件优化
-
定制语法,更适合昇腾特性
-
避免开源协议约束
自研系统的风险:
-
生态建设困难
-
重复造轮子
-
可能落后于Triton发展
4.3 路径三:渐进式改进Ascend C(最保守)
在当前Ascend C基础上渐进改进:
// 渐进式改进方向
class AscendCImprovements {
public:
// 1. 更高级的抽象
struct HighLevelConstructs {
// 模板库:常用算子模式
template<typename T, int TM, int TN, int TK>
class MatMulTemplate; // 矩阵乘法模板
// 自动优化原语
AutoTiler tiler; // 自动分块
AutoPipeliner pipeliner; // 自动流水线
AutoVectorizer vectorizer; // 自动向量化
};
// 2. 更好的工具链
struct ToolchainImprovements {
// 智能编译器
AIOptimizingCompiler compiler; // AI辅助优化
// 性能分析器
VisualProfiler profiler; // 可视化性能分析
// 调试工具
InteractiveDebugger debugger; // 交互式调试
};
// 3. 生态集成
struct EcosystemIntegration {
// PyTorch集成
PyTorchExtension pytorch_ext; // 直接调用Ascend算子
// ONNX支持
ONNXConverter onnx_converter; // ONNX到Ascend C
// 模型库
ModelZoo model_zoo; // 预优化模型
};
};🏢 第五章 企业级影响与 adoption 策略
5.1 对华为/昇腾的影响
5.2 对开发者的影响
现有Ascend C开发者:
# 技能转型建议
skill_transition = {
"当前价值": [
"硬件架构知识",
"性能优化技巧",
"Ascend C专有技能"
],
"转型方向": [
"编译器开发 (Triton后端)",
"AI优化器开发",
"高级抽象设计",
"生态工具开发"
],
"学习建议": [
"学习Triton原理",
"掌握编译器技术",
"了解开源社区运营",
"提升Python和AI技能"
]
}新开发者/算法工程师:
# 入门路径变化
learning_path_change = {
"旧路径 (2023)": [
"学习Ascend C (3-6个月)",
"掌握硬件架构 (2-3个月)",
"实践优化技巧 (6-12个月)",
"成为合格开发者 (1-2年)"
],
"新路径 (未来)": [
"学习Python Triton (1-2周)",
"编写第一个算子 (1天)",
"理解硬件约束 (1个月)",
"成为高效开发者 (2-3个月)"
],
"效率提升": "5-10倍"
}5.3 企业 adoption 时间线
# 企业采用预测
enterprise_adoption = {
"2024-2025 (探索期)": {
"采用率": "0-5%",
"典型用户": "研究机构、早期采用者",
"使用场景": "实验性项目、原型验证",
"关键障碍": ["生态不成熟", "性能差距", "工具链不完善"]
},
"2026-2027 (成长期)": {
"采用率": "10-30%",
"典型用户": "科技公司、AI初创公司",
"使用场景": "特定工作负载、补充现有方案",
"成功因素": ["性能达到90%", "主流模型支持", "社区活跃"]
},
"2028+ (成熟期)": {
"采用率": "50%+",
"典型用户": "广泛企业、云服务商",
"使用场景": "主流AI应用、生产系统",
"标志": ["成为默认选择", "生态繁荣", "人才充足"]
}
}🔮 第六章 技术挑战与解决方案
6.1 挑战一:硬件差异的抽象
问题:Triton为GPU设计,昇腾有Cube Unit、复杂存储层级等独特特性。
解决方案:多层抽象 + 智能映射
// 智能硬件抽象层
class AscendHardwareAbstraction {
public:
// 硬件特性描述
struct HardwareCapabilities {
// 计算单元
bool has_cube_unit = true;
int cube_mma_size = 16; // 16×16×16
// 存储层级
struct MemoryLevel {
string name;
size_t size;
int bandwidth; // GB/s
int latency; // cycles
};
vector<MemoryLevel> memory_hierarchy;
// 向量能力
int vector_width = 8; // 一次处理8个元素
};
// 自动模式匹配
enum ComputationPattern {
DENSE_MATMUL, // 密集矩阵乘 -> Cube Unit
SPARSE_MATMUL, // 稀疏矩阵乘 -> 特殊处理
VECTOR_OPS, // 向量运算 -> Vector Unit
ELEMENTWISE, // 逐元素运算 -> Vector Unit
REDUCTION, // 规约运算 -> 混合
};
ComputationPattern detect_pattern(const TritonIR& ir) {
// AI模型识别计算模式
if (is_dense_matmul(ir)) return DENSE_MATMUL;
if (is_sparse_matmul(ir)) return SPARSE_MATMUL;
if (is_vector_op(ir)) return VECTOR_OPS;
if (is_elementwise(ir)) return ELEMENTWISE;
return REDUCTION;
}
// 自动优化策略选择
OptimizationStrategy select_strategy(
ComputationPattern pattern,
const HardwareCapabilities& hw) {
switch (pattern) {
case DENSE_MATMUL:
return {
.compute_unit = "CUBE",
.tile_size = {128, 128, 64}, // M,N,K分块
.pipeline_depth = 2,
.memory_layout = "FRACTAL_NZ"
};
case VECTOR_OPS:
return {
.compute_unit = "VECTOR",
.vector_width = hw.vector_width,
.unroll_factor = 4,
.memory_layout = "NC1HWC0"
};
// ... 其他模式
}
}
};6.2 挑战二:性能调优的自动化
问题:手工优化需要大量经验,如何自动化?
解决方案:AI驱动的自动调优
# AI自动调优系统
class AIAutoTuner:
def __init__(self):
# 1. 性能模型
self.performance_model = PerformancePredictor()
# 2. 优化知识库
self.knowledge_base = OptimizationKnowledgeBase()
# 3. 强化学习调优器
self.rl_tuner = ReinforcementLearningTuner()
def auto_tune(self, kernel_ir, hardware_info):
"""自动调优内核"""
# 步骤1: 特征提取
features = extract_features(kernel_ir, hardware_info)
# 步骤2: 相似性搜索
similar_kernels = self.knowledge_base.find_similar(features)
if similar_kernels:
# 步骤3: 基于知识的优化
optimized = apply_known_optimizations(
kernel_ir, similar_kernels[0])
else:
# 步骤4: 探索性优化(强化学习)
optimized = self.rl_tuner.explore_optimizations(
kernel_ir, hardware_info)
# 步骤5: 记录到知识库
self.knowledge_base.record(
features, optimized, performance_metrics)
return optimized
def continuous_learning(self):
"""持续学习循环"""
while True:
# 收集生产环境性能数据
perf_data = collect_production_performance()
# 更新性能模型
self.performance_model.update(perf_data)
# 发现新的优化模式
new_patterns = discover_optimization_patterns(perf_data)
# 更新知识库
self.knowledge_base.add_patterns(new_patterns)
# 重新调优关键内核
retune_critical_kernels()6.3 挑战三:生态兼容性
问题:如何兼容现有模型和框架?
解决方案:多层兼容性架构

🚀 第七章 未来展望:2030年的算子开发
7.1 愿景一:完全声明式的算子开发
# 2030年的算子开发体验
# 在Jupyter Notebook中
# 1. 自然语言描述需求
idea = """
我需要一个高效的Transformer注意力层,
支持多查询注意力(MQA)和分组查询注意力(GQA)。
序列长度最多8192,头维度128。
需要Flash Attention优化,支持因果掩码。
"""
# 2. AI助手生成代码
from ai_developer import AscendAIAssistant
assistant = AscendAIAssistant()
spec = assistant.understand_requirement(idea)
# 3. 自动生成优化代码
kernel_code = assistant.generate_kernel(spec)
print(kernel_code)
# 输出自动生成的Triton-like代码
# 包含自动选择的优化策略
# 4. 一键编译部署
binary = assistant.compile_and_optimize(kernel_code)
# 5. 性能保证
perf_guarantee = assistant.performance_guarantee(binary)
print(f"性能保证: {perf_guarantee} TFLOPS")
print(f"硬件利用率: {perf_guarantee.utilization}%")7.2 愿景二:算法-硬件协同设计
未来的硬件将专门为Triton-like抽象优化:
// 下一代昇腾架构设想
class NextGenAscendArchitecture {
public:
// 专门为高级抽象优化的特性
struct ArchitecturalFeatures {
// 1. 可配置计算单元
bool reconfigurable_cube = true; // 可配置为不同形状
// 2. 智能存储层次
bool auto_caching = true; // 自动数据放置
// 3. 动态精度支持
bool dynamic_precision = true; // 运行时精度调整
// 4. 稀疏计算原生支持
bool native_sparse = true; // 硬件稀疏支持
// 5. 编译-运行时协同
bool compile_time_optimization = true; // 编译时优化
};
// Triton原语的硬件加速
map<string, HardwareAccelerator> triton_accelerators = {
{"tl.dot", CubeUnitAccelerator()},
{"tl.load", SmartLoadUnit()},
{"tl.store", SmartStoreUnit()},
{"tl.reduce", ReductionTree()},
};
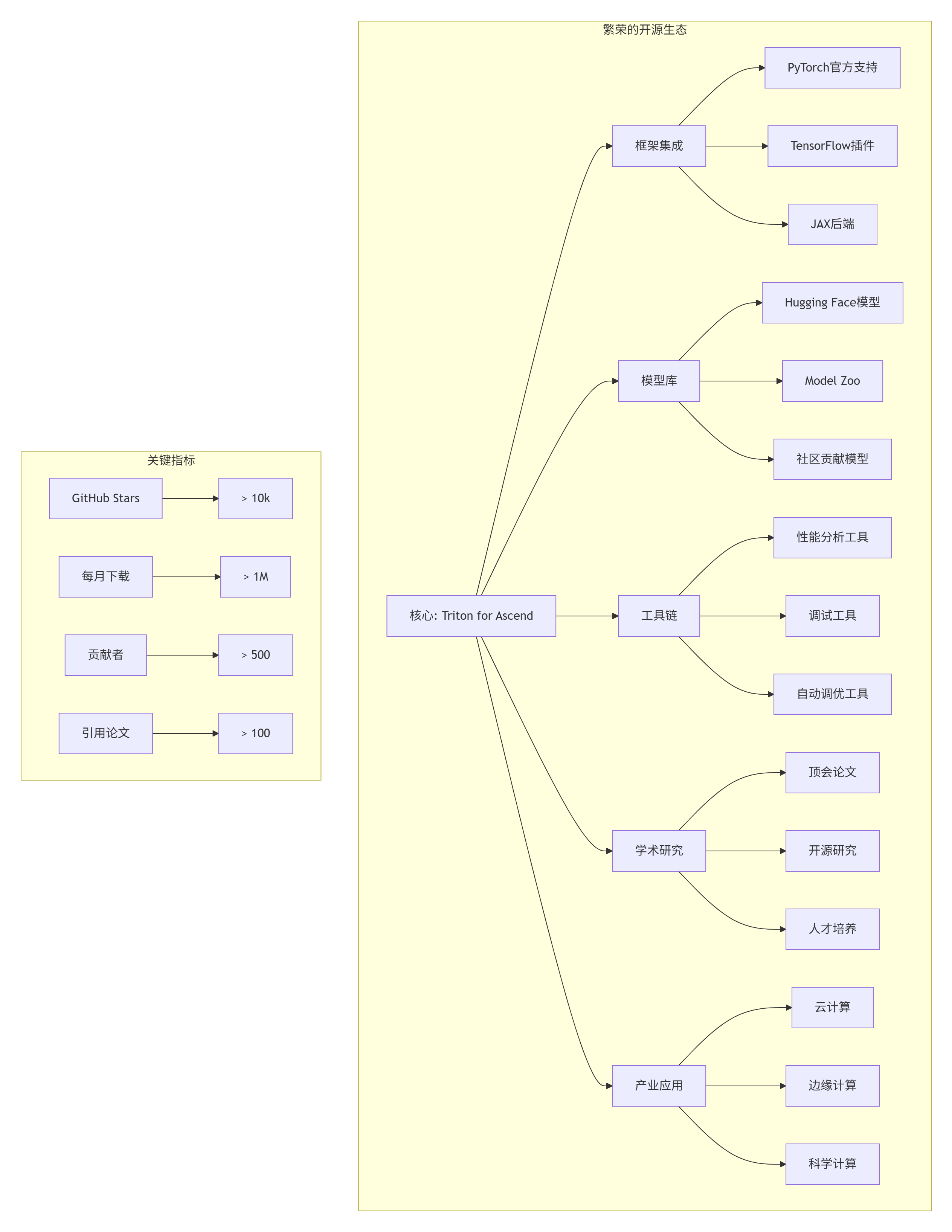
};7.3 愿景三:开源生态繁荣
2030年的昇腾开源生态:
📚 第八章 行动指南:开发者如何准备
8.1 学习路径建议
# 2024-2025年学习路线
learning_roadmap = {
"立即开始 (2024)": [
"掌握Python和PyTorch",
"学习Triton基础 (GPU版)",
"理解编译器基本原理",
"关注昇腾生态动态"
],
"中期准备 (2025)": [
"深入学习Triton架构",
"学习LLVM/MLIR编译器技术",
"参与开源项目贡献",
"建立昇腾硬件知识"
],
"长期投资 (2026+)": [
"成为Triton专家",
"深入编译器开发",
"参与标准制定",
"领导技术社区"
]
}
# 资源推荐
resources = {
"官方文档": [
"Triton官方文档: https://triton-lang.org",
"昇腾开发者社区: https://ascend.huawei.com",
"MLIR文档: https://mlir.llvm.org"
],
"学习课程": [
"Coursera: 编译器原理",
"Udacity: AI芯片设计",
"开源大学: Triton实战"
],
"社区参与": [
"GitHub: triton-lang/triton",
"Discord: Triton社区",
"论坛: 昇腾开发者论坛"
]
}8.2 企业技术战略
# 企业技术战略建议
enterprise_strategy = {
"技术选型": {
"短期 (1年内)": "继续使用Ascend C,但开始评估Triton",
"中期 (1-2年)": "试点Triton for Ascend,用于新项目",
"长期 (2-3年)": "逐步迁移到Triton生态"
},
"团队建设": {
"立即行动": "培训1-2名Triton/编译器专家",
"6个月内": "建立交叉技能团队 (算法+编译+硬件)",
"1年内": "具备Triton开发和优化能力"
},
"项目规划": {
"实验项目": "用Triton重写1-2个关键算子,评估效果",
"试点项目": "在一个新产品中使用Triton for Ascend",
"推广计划": "制定全公司迁移路线图"
},
"风险评估": {
"技术风险": "Triton for Ascend成熟度",
"生态风险": "开源社区发展速度",
"竞争风险": "竞争对手的生态建设"
}
}8.3 开源贡献指南
如果你想为Triton for Ascend贡献:
# 开源贡献路径
contribution_path = {
"入门贡献": [
"文档改进和翻译",
"示例代码和教程",
"问题复现和报告",
"社区问题解答"
],
"代码贡献": [
"算子实现 (从简单开始)",
"测试用例编写",
"性能基准测试",
"bug修复"
],
"核心贡献": [
"编译器后端开发",
"优化器实现",
"新特性设计",
"架构改进"
],
"领导贡献": [
"模块维护者",
"代码审查",
"路线图规划",
"社区建设"
]
}
# 获取帮助
get_help = {
"官方渠道": [
"GitHub Issues",
"Discord社区",
"邮件列表"
],
"华为资源": [
"昇腾开发者社区",
"技术大使计划",
"开源办公室"
],
"学习资源": [
"贡献者指南",
"代码风格指南",
"开发工作流"
]
}🎯 写在最后
看了13年昇腾生态的发展,我最大的感悟是:技术可以领先,但生态决定成败。Triton代表的不是一种技术,而是一种生态建设范式。
三个核心判断:
-
开放必胜封闭:历史证明,开放生态总能在长期战胜封闭系统
-
抽象决定普及:正确的抽象层级能吸引数量级的开发者
-
社区创造价值:最活跃的社区拥有最强的生命力
给华为/昇腾的话:现在是关键时刻。继续走Ascend C的封闭路线,可能赢得技术战斗但输掉生态战争。拥抱Triton,可能是以短期控制权换取长期生态繁荣的明智选择。
给开发者的话:无论你是Ascend C专家还是Python新手,Triton代表的范式演进都会影响你的职业生涯。早学习,早受益。编译器、AI系统、硬件软件协同,这些技能永远不会过时。
给行业的话:AI算力的竞争,正在从硬件算力竞争,转向开发者生态竞争。拥有最好开发体验的平台,将拥有最多的创新应用。
Triton for Ascend,这不仅是技术可能性,更是生态必要性。这条路不容易,但值得走。。
🚀 参考链接
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)