
Graph Engine (GE) 深度编程:构建图算融合的高性能流水线
GE 是昇腾软件栈中的“总指挥”。抽象层级:Ascend C 关注点(算子内部),GE 关注面(算子之间)。性能收益:通过图编译,消除 Host 调度开销,实现算子间的无缝衔接。开发模式:定义 IR -> 构建 Graph -> Session 运行。掌握了 GE 编程,你就具备了构建高性能推理引擎(如类似于 TensorRT 的应用)的能力。
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在高性能计算中,控制流与计算流的分离是提升效率的关键。
-
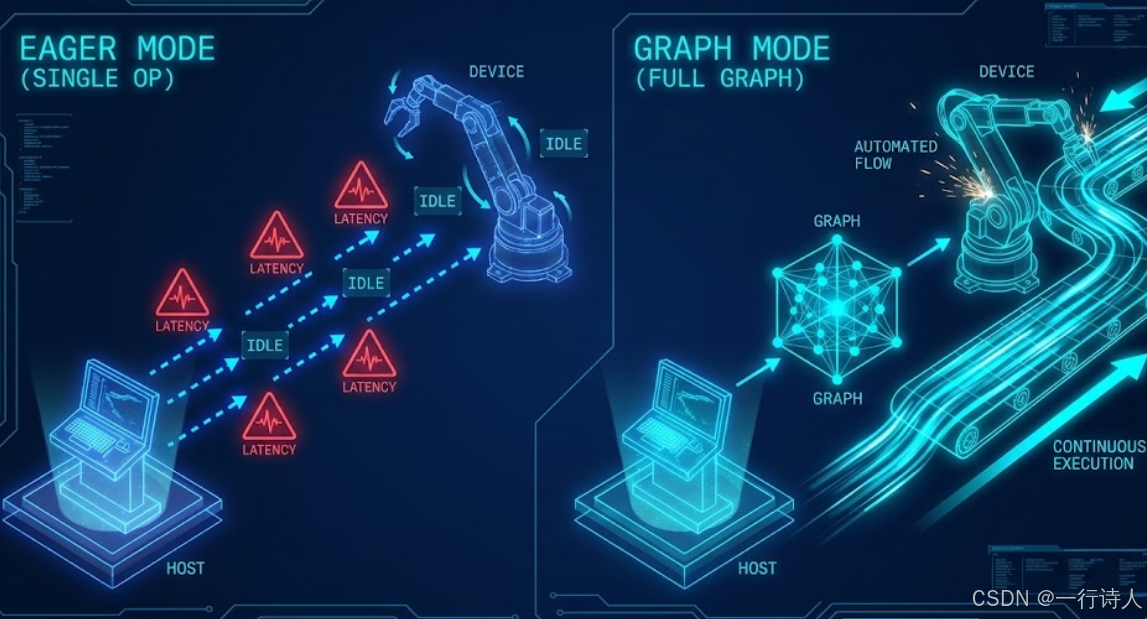
单算子模式 (Eager Mode): Host: "NPU, 算个 Add" -> NPU 算 -> Host 等待 -> Host: "NPU, 算个 Relu" -> NPU 算。 缺陷:Host 侧的调度开销(Dispatch Overhead)往往比小算子的计算时间还长。
-
图模式 (Graph Mode): Host: "NPU, 这是整个任务清单(Graph),你自己看着办。" -> NPU 内部自动流转数据,算完通知 Host。 优势:零 Host 交互,最大化 Device 利用率。
昇腾的 Graph Engine (GE) 就是负责接管这张图的大管家。本期我们将学习如何脱离深度学习框架,直接使用 GE 的 C++ 接口构建和运行一张计算图。
一、 核心图解:从“接力跑”到“自动流水线”
GE 的本质是将 Host 侧的控制权下沉到 Device 侧。
二、 GE 编程的核心对象:IR (Intermediate Representation)
要构建一张图,我们不能直接写 C++ 代码逻辑,而是要定义 IR(中间表示)。 在昇腾中,IR 对应的类是 ge::op::xxx。
2.1 定义节点 (Node)
每一个算子(比如我们写的 AddCustom)在 GE 图中都是一个节点。
#include "all_ops.h" // 包含所有标准算子定义
void BuildGraph() {
// 1. 定义输入节点 (Data)
auto input_x = ge::op::Data("InputX");
auto input_y = ge::op::Data("InputY");
// 2. 定义计算节点 (Add)
auto add_node = ge::op::Add("MyAddNode");
// 3. 定义连接关系 (Edge)
// 将 input_x 的输出连到 add_node 的 x 输入端口
add_node.set_input_x1(input_x);
add_node.set_input_x2(input_y);
// 4. 定义输出节点 (NetOutput)
// 这一点很重要,图必须有终点
// 某些场景下也可以直接把 add_node 设为输出
}
2.2 构建图 (Graph)
节点定义好后,要把它们装进一个 ge::Graph 对象中。
ge::Graph graph("MyFirstGraph");
// 设置图的输入和输出
std::vector<ge::Operator> inputs = {input_x, input_y};
std::vector<ge::Operator> outputs = {add_node};
graph.SetInputs(inputs).SetOutputs(outputs);
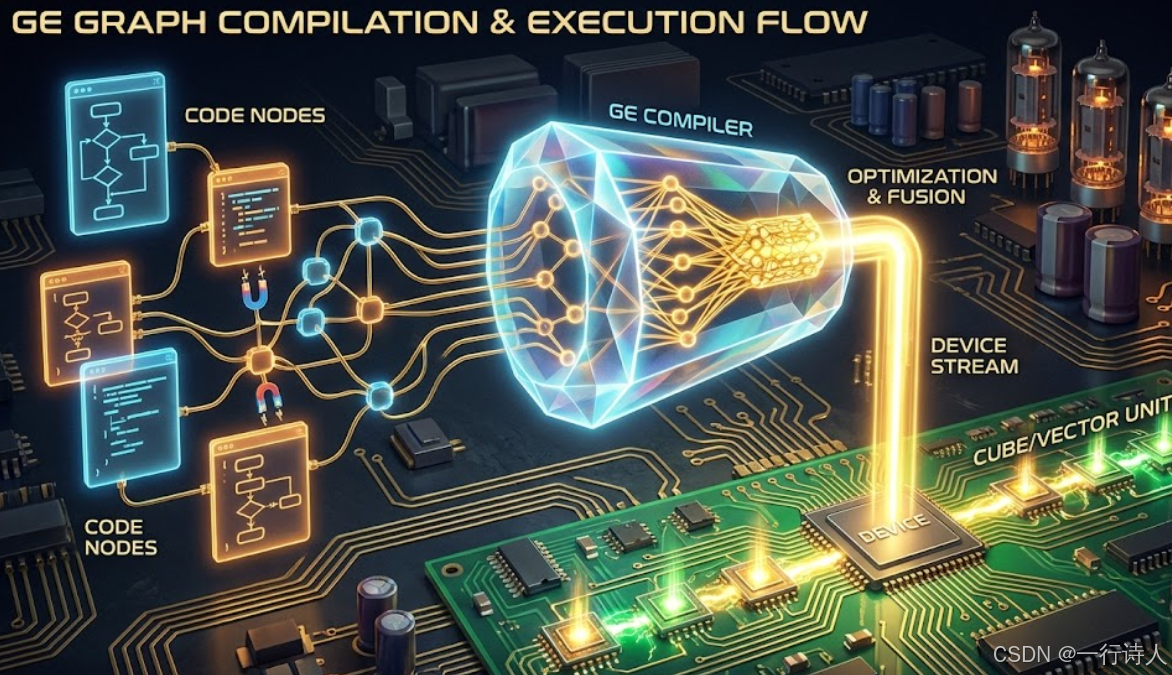
三、 运行图:Session 与 Model
图构建好只是第一步,要让它跑起来,需要经过 编译 (Compile) 和 加载 (Load)。
-
Initialize: 初始化 GE 系统。
-
Session: 创建一个会话(Session),它是图运行的上下文。
-
AddGraph: 将构建好的
ge::Graph添加到 Session 中。此时 GE 会进行图编译(算子融合、内存分配、流分配),生成离线模型。 -
RunGraph: 喂入数据,执行图。
四、 实战:端到端的 GE 流程
下面是一个极简的 GE 运行代码框架(伪代码):
#include "ge_api/ge_api.h"
int main() {
// 1. 系统初始化
std::map<std::string, std::string> options;
ge::GEInitialize(options);
// 2. 建图
ge::Graph graph("AddGraph");
// ... (参考上文 BuildGraph 逻辑) ...
// 3. 创建 Session 并添加图
ge::Session* session = new ge::Session(options);
session->AddGraph(0, graph); // Graph ID = 0
// 4. 准备数据 (Tensor)
std::vector<ge::Tensor> input_tensors;
std::vector<ge::Tensor> output_tensors;
// ... 填充 input_tensors 数据 ...
// 5. 执行图
session->RunGraph(0, input_tensors, output_tensors);
// 6. 获取结果
// 从 output_tensors 读取数据
// 7. 销毁
delete session;
ge::GEFinalize();
return 0;
}
五、 GE 的高级特性:Auto-Pipeline
GE 最强大的地方在于它会自动帮我们做流水线编排。 如果你定义了一个 Data -> A -> B -> C -> NetOutput 的图。 GE 会自动分析:
-
如果 A 和 B 没有依赖关系,GE 会把它们调度到不同的 Stream 上并行执行。
-
如果 B 的输入依赖 A 的输出,GE 会自动插入 Event 同步指令。
-
GE 还会自动复用内存(Memory Reuse),让 B 的输出直接覆盖 A 的输入(如果不再使用),极大降低显存占用。
六、 总结
GE 是昇腾软件栈中的“总指挥”。
-
抽象层级:Ascend C 关注点(算子内部),GE 关注面(算子之间)。
-
性能收益:通过图编译,消除 Host 调度开销,实现算子间的无缝衔接。
-
开发模式:定义 IR -> 构建 Graph -> Session 运行。
掌握了 GE 编程,你就具备了构建高性能推理引擎(如类似于 TensorRT 的应用)的能力。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 22
22 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)