
Ascend C算子编程完全指南:环境搭建、核函数设计与性能优化实践
引言:走进昇腾AI计算的世界
在人工智能技术迅猛发展的今天,深度学习模型已广泛应用于各个领域,而支撑这些复杂模型高效运行的核心正是AI计算芯片和相应的软件开发平台。华为昇腾(Ascend)AI处理器作为国内领先的AI计算解决方案,其配套的CANN(Compute Architecture for Neural Networks)软件平台为开发者提供了强大的工具链。Ascend C作为专门为昇腾AI处理器设计的编程语言,是连接算法与硬件的关键桥梁。
对于刚接触AI计算开发的新手而言,Ascend C可能显得神秘而复杂。本文将以万字长文的形式,从零开始,详细讲解如何通过CANN训练营的学习路径,使用Ascend C开发第一个矩阵加法算子。我们将深入探讨从环境搭建、理论基础、代码实现到调试优化的全过程,为初学者提供一份详实的实践指南。
第一章:Ascend C与开发环境全面解析
1.1 Ascend C语言概述与特性
Ascend C是基于标准C/C++语法扩展的领域特定语言(DSL),专门针对昇腾AI处理器的架构特点进行了优化。其主要特性包括:
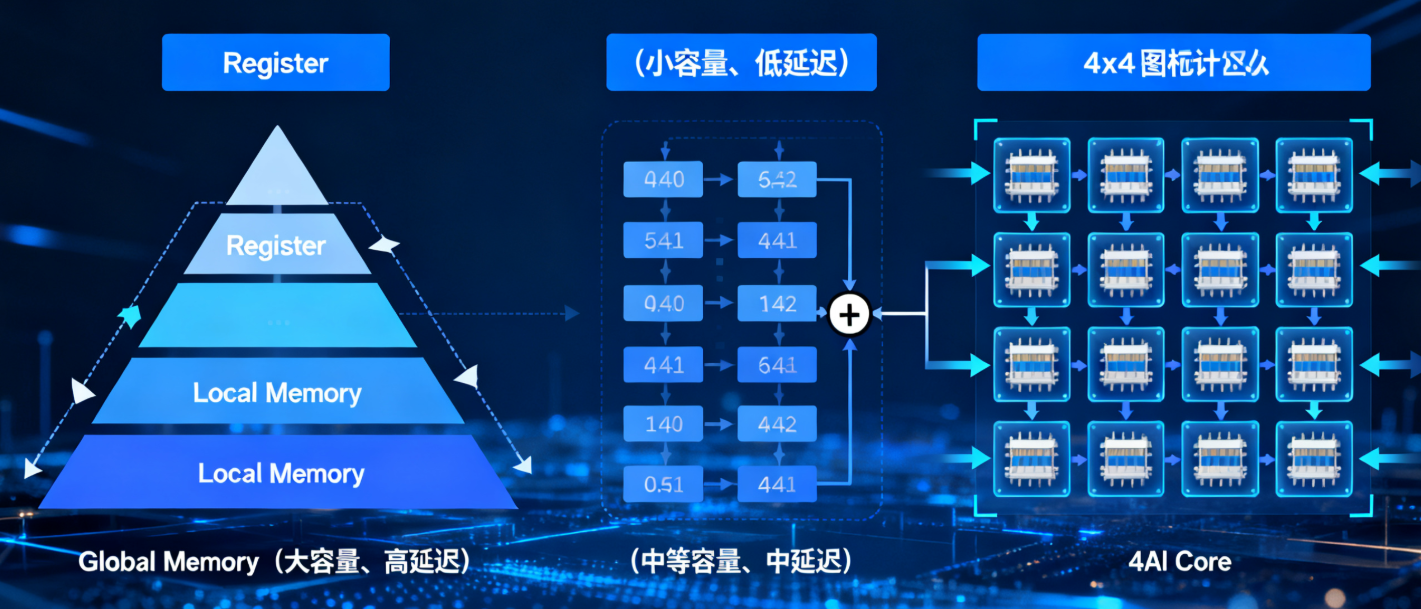
- 分层存储架构抽象:Ascend C显式管理数据在不同层级存储(Global Memory、Local Memory、Register等)之间的流动,这与传统CPU编程有显著区别。开发者需要明确控制数据的搬运路径,以充分利用硬件带宽。
- 并行计算模型:支持多核并行计算,每个AI Core可以同时执行多个计算任务。Ascend C提供了相应的语法和接口来管理这种并行性。
- 向量化计算:内置丰富的向量操作指令,能够高效处理SIMD(单指令多数据)类型的计算任务,特别适合矩阵、张量等数据并行计算。
- 异步执行机制:支持计算与数据搬运的异步重叠,通过流水线技术隐藏数据访问延迟,提升整体计算效率。
1.2 开发环境搭建详解
1.2.1 硬件要求与准备
开发Ascend C程序需要以下硬件环境:
-
昇腾AI处理器(如Ascend 910、Ascend 310等)或对应的云服务实例
-
足够的存储空间(建议至少500GB空闲空间)
-
满足计算要求的内存配置
1.2.2 软件环境安装
CANN工具包安装:
# 下载CANN工具包(以CANN 6.0为例)
wget https://ascend-repo.xxxxx.com/CANN-6.0.0-ubuntu18.04-x86_64.run
# 安装工具包
chmod +x CANN-6.0.0-ubuntu18.04-x86_64.run
./CANN-6.0.0-ubuntu18.04-x86_64.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.shMindStudio IDE安装与配置:
MindStudio是华为提供的集成开发环境,支持Ascend C的开发和调试。
-
下载并安装MindStudio
-
配置昇腾AI处理器连接
-
创建Ascend C工程模板
1.2.3 验证安装结果
创建简单的测试程序验证环境是否正确安装:
// test_environment.cpp
#include <iostream>
#include "acl/acl.h"
int main() {
// 初始化ACL(Ascend Computing Language)环境
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << "ACL init failed: " << ret << std::endl;
return -1;
}
// 获取设备数量
uint32_t deviceCount = 0;
ret = aclrtGetDeviceCount(&deviceCount);
if (ret != ACL_SUCCESS) {
std::cerr << "Get device count failed: " << ret << std::endl;
aclFinalize();
return -1;
}
std::cout << "Found " << deviceCount << " Ascend AI processor(s)" << std::endl;
// 清理资源
aclFinalize();
return 0;
}编译并运行测试程序,确认环境配置正确。
1.3 Ascend C编程基础概念
1.3.1 核函数(Kernel Function)
核函数是在AI Core上执行的基本计算单元,具有以下特点:
-
使用
__global__ __aicore__修饰符声明 -
每个核函数实例在单个AI Core上执行
-
支持多核并行执行
1.3.2 存储层次结构
理解Ascend AI处理器的存储体系对高效编程至关重要:
全局内存(Global Memory):容量最大但访问延迟最高的存储层级,用于存储输入输出数据。
本地内存(Local Memory):每个AI Core独有的中间存储,容量有限但带宽更高。
寄存器(Register):最快但容量最小的存储,用于存储计算中间结果。
1.3.3 任务调度与并行
Ascend C采用分块并行计算模型,大规模计算任务被划分为多个小块,由不同的AI Core并行处理。
第二章:矩阵加法算子的理论基础
2.1 矩阵运算的数学原理
矩阵加法是线性代数中最基本的运算之一。对于两个M×N维的矩阵A和B,它们的和矩阵C定义为:
Cij=Aij+Bij对于i=1,2,…,M;j=1,2,…,N
从计算角度看,矩阵加法具有以下特性:
-
计算复杂度为O(M×N)
-
高度并行,每个元素的计算相互独立
-
内存访问模式规整,适合向量化处理
2.2 并行计算模式分析
矩阵加法的并行化策略主要有两种:
数据并行:将矩阵划分为多个子块,不同的处理单元同时处理不同的数据块。
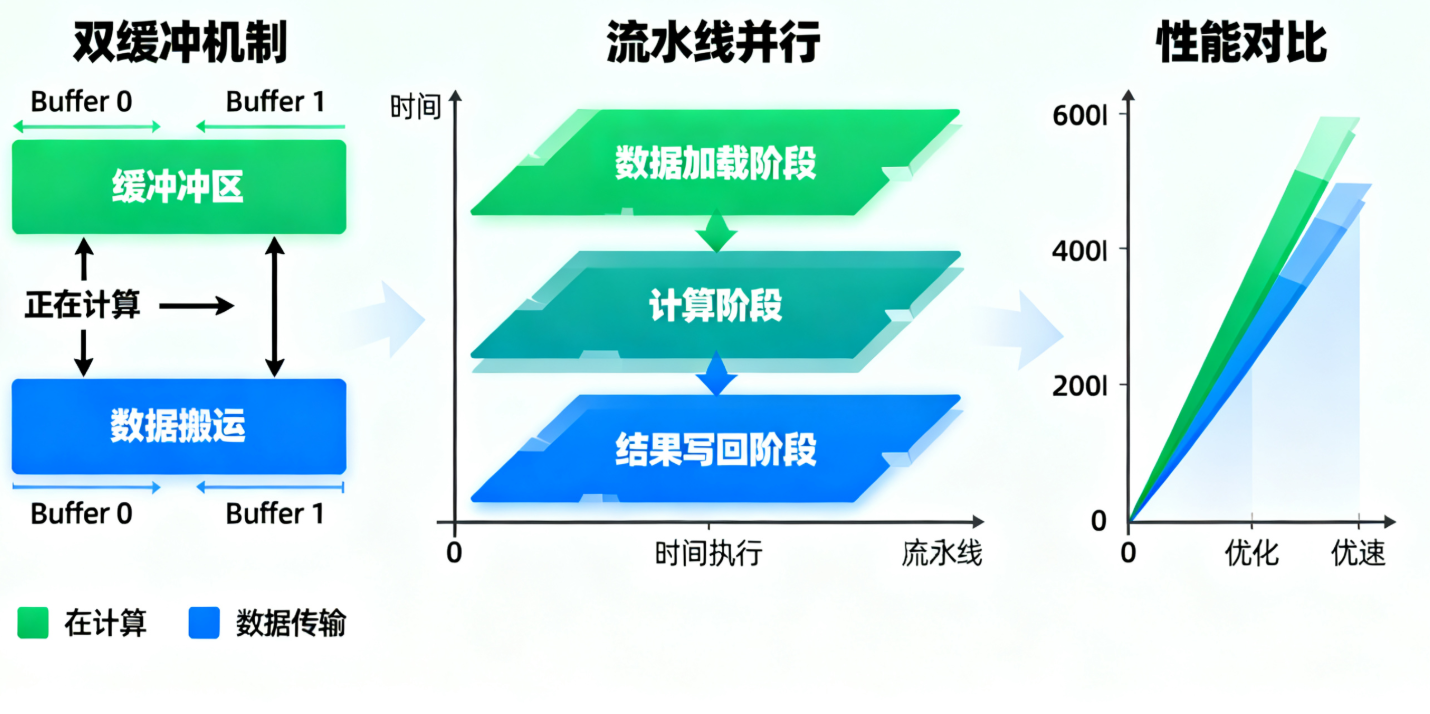
流水线并行:将计算过程分解为多个阶段(数据搬运、计算、结果写回),各阶段重叠执行。
在Ascend C中,我们通常结合使用这两种并行策略以达到最佳性能。
2.3 内存访问模式优化
高效的内存访问模式对性能有决定性影响。矩阵加法中的优化考虑包括:
空间局部性利用:确保连续访问内存地址,充分利用缓存行。
bank冲突避免:在并行访问时避免多个线程同时访问同一内存bank。
数据对齐:确保数据地址符合硬件要求的对齐方式。
第三章:第一个矩阵加法算子的完整实现
3.1 项目结构与文件组织
创建标准的Ascend C项目目录结构:
matrix_add_project/
├── CMakeLists.txt # 项目构建配置
├── include/ # 头文件目录
│ ├── matrix_add.h # 算子接口声明
│ └── common_utils.h # 通用工具函数
├── kernel/ # 核函数实现
│ ├── matrix_add_kernel.cpp # 设备端核函数
│ └── matrix_add_impl.cpp # 核函数实现细节
├── host/ # 主机端代码
│ ├── matrix_add_host.cpp # 主机端接口实现
│ └── main.cpp # 测试主程序
└── tests/ # 测试代码
├── test_matrix_add.cpp # 单元测试
└── test_utils.cpp # 测试工具3.2 核函数详细实现
3.2.1 核函数接口设计
// include/matrix_add.h
#ifndef MATRIX_ADD_H
#define MATRIX_ADD_H
#include <cstdint>
#ifdef __cplusplus
extern "C" {
#endif
/**
* @brief 矩阵加法核函数
* @param blockDim 块维度信息
* @param l2ctrl L2缓存控制参数
* @param buffer 数据缓冲区地址
* @param length 数据总长度(字节)
*/
void matrix_add_kernel(uint32_t blockDim, uint32_t l2ctrl,
uint32_t buffer, uint32_t length);
/**
* @brief 主机端矩阵加法调用接口
* @param inputA 输入矩阵A设备地址
* @param inputB 输入矩阵B设备地址
* @param outputC 输出矩阵C设备地址
* @param totalElements 总元素个数
* @param deviceId 设备ID
* @return 错误码,0表示成功
*/
int matrix_add_do(void* inputA, void* inputB, void* outputC,
int32_t totalElements, int32_t deviceId);
#ifdef __cplusplus
}
#endif
#endif // MATRIX_ADD_H3.2.2 核函数实现细节
// kernel/matrix_add_kernel.cpp
#include "matrix_add.h"
#include <aicore/vector_operations.h>
#include <aicore/memory_operations.h>
// 定义矩阵维度(可根据实际需求调整)
constexpr int32_t TILE_SIZE = 256; // 分块大小
constexpr int32_t VECTOR_LEN = 64; // 向量化长度
// 核函数实现
extern "C" __global__ __aicore__ void matrix_add_kernel(
uint32_t blockDim, uint32_t l2ctrl, uint32_t buffer, uint32_t length) {
// 获取任务ID和任务总数
uint32_t taskId = get_task_id();
uint32_t taskNum = get_task_num();
// 计算总元素个数
int32_t totalElements = length / sizeof(float);
// 计算每个任务处理的元素数量
int32_t elementsPerTask = totalElements / taskNum;
int32_t remainder = totalElements % taskNum;
// 计算当前任务的起始和结束位置
int32_t startIdx = taskId * elementsPerTask +
(taskId < remainder ? taskId : remainder);
int32_t endIdx = startIdx + elementsPerTask +
(taskId < remainder ? 1 : 0);
// 获取全局内存地址
GM_ADDR inputA_gm = GET_GLOBAL_BUFFER(buffer);
GM_ADDR inputB_gm = inputA_gm + totalElements * sizeof(float);
GM_ADDR outputC_gm = inputB_gm + totalElements * sizeof(float);
// 计算当前任务需要处理的元素数量
int32_t taskElements = endIdx - startIdx;
// 分块处理数据
for (int32_t offset = 0; offset < taskElements; offset += TILE_SIZE) {
int32_t currentElements = (offset + TILE_SIZE <= taskElements) ?
TILE_SIZE : taskElements - offset;
int32_t globalOffset = startIdx + offset;
// 向量化处理(每次处理VECTOR_LEN个元素)
for (int32_t vecOffset = 0; vecOffset < currentElements; vecOffset += VECTOR_LEN) {
int32_t vecLen = (vecOffset + VECTOR_LEN <= currentElements) ?
VECTOR_LEN : currentElements - vecOffset;
int32_t globalVecOffset = globalOffset + vecOffset;
// 声明局部内存缓冲区
__local__ float localA[VECTOR_LEN];
__local__ float localB[VECTOR_LEN];
__local__ float localC[VECTOR_LEN];
// 从全局内存搬运数据到局部内存
__memcpy_local_gm(localA, inputA_gm + globalVecOffset * sizeof(float),
vecLen * sizeof(float));
__memcpy_local_gm(localB, inputB_gm + globalVecOffset * sizeof(float),
vecLen * sizeof(float));
// 执行向量加法
for (int32_t i = 0; i < vecLen; ++i) {
localC[i] = localA[i] + localB[i];
}
// 将结果写回全局内存
__memcpy_gm_local(outputC_gm + globalVecOffset * sizeof(float),
localC, vecLen * sizeof(float));
}
}
}3.2.3 高级优化实现
为了进一步提升性能,我们可以实现更复杂的优化版本:
// kernel/matrix_add_advanced.cpp
#include "matrix_add.h"
#include <aicore/vector_operations.h>
// 双缓冲实现:计算与数据搬运重叠
extern "C" __global__ __aicore__ void matrix_add_advanced_kernel(
uint32_t blockDim, uint32_t l2ctrl, uint32_t buffer, uint32_t length) {
uint32_t taskId = get_task_id();
uint32_t taskNum = get_task_num();
int32_t totalElements = length / sizeof(float);
// 计算任务分配
int32_t elementsPerTask = totalElements / taskNum;
int32_t remainder = totalElements % taskNum;
int32_t startIdx = taskId * elementsPerTask +
(taskId < remainder ? taskId : remainder);
int32_t endIdx = startIdx + elementsPerTask +
(taskId < remainder ? 1 : 0);
int32_t taskElements = endIdx - startIdx;
GM_ADDR inputA_gm = GET_GLOBAL_BUFFER(buffer);
GM_ADDR inputB_gm = inputA_gm + totalElements * sizeof(float);
GM_ADDR outputC_gm = inputB_gm + totalElements * sizeof(float);
// 双缓冲设置
constexpr int32_t DOUBLE_BUFFER_SIZE = TILE_SIZE * 2;
__local__ float localA_buf0[TILE_SIZE], localA_buf1[TILE_SIZE];
__local__ float localB_buf0[TILE_SIZE], localB_buf1[TILE_SIZE];
__local__ float localC_buf0[TILE_SIZE], localC_buf1[TILE_SIZE];
int32_t currentBuffer = 0;
bool hasNextTile = true;
int32_t processedElements = 0;
// 预加载第一个tile
if (taskElements > 0) {
int32_t firstTileSize = (TILE_SIZE <= taskElements) ? TILE_SIZE : taskElements;
__memcpy_async_local_gm(localA_buf0,
inputA_gm + (startIdx + processedElements) * sizeof(float),
firstTileSize * sizeof(float));
__memcpy_async_local_gm(localB_buf0,
inputB_gm + (startIdx + processedElements) * sizeof(float),
firstTileSize * sizeof(float));
processedElements += firstTileSize;
}
// 流水线处理:计算当前tile的同时搬运下一个tile
while (hasNextTile) {
// 等待当前缓冲区数据就绪
__sync_buffers();
// 确定当前使用的缓冲区
__local__ float* currentA = (currentBuffer == 0) ? localA_buf0 : localA_buf1;
__local__ float* currentB = (currentBuffer == 0) ? localB_buf0 : localB_buf1;
__local__ float* currentC = (currentBuffer == 0) ? localC_buf0 : localC_buf1;
int32_t currentTileSize = (processedElements <= TILE_SIZE) ?
processedElements : TILE_SIZE;
// 执行计算
for (int32_t i = 0; i < currentTileSize; i += VECTOR_LEN) {
int32_t vecLen = (i + VECTOR_LEN <= currentTileSize) ?
VECTOR_LEN : currentTileSize - i;
// 向量化加法
for (int32_t j = 0; j < vecLen; ++j) {
currentC[i + j] = currentA[i + j] + currentB[i + j];
}
}
// 预加载下一个tile(如果存在)
hasNextTile = (processedElements < taskElements);
if (hasNextTile) {
int32_t nextTileSize = (processedElements + TILE_SIZE <= taskElements) ?
TILE_SIZE : taskElements - processedElements;
__local__ float* nextA = (currentBuffer == 0) ? localA_buf1 : localA_buf0;
__local__ float* nextB = (currentBuffer == 0) ? localB_buf1 : localB_buf0;
__memcpy_async_local_gm(nextA,
inputA_gm + (startIdx + processedElements) * sizeof(float),
nextTileSize * sizeof(float));
__memcpy_async_local_gm(nextB,
inputB_gm + (startIdx + processedElements) * sizeof(float),
nextTileSize * sizeof(float));
processedElements += nextTileSize;
}
// 写回当前tile结果
__memcpy_async_gm_local(outputC_gm + (startIdx + processedElements - currentTileSize) * sizeof(float),
currentC, currentTileSize * sizeof(float));
// 切换缓冲区
currentBuffer = 1 - currentBuffer;
}
// 等待所有异步操作完成
__sync_all_buffers();
}3.3 主机端代码实现
3.3.1 主机端接口封装
// host/matrix_add_host.cpp
#include "matrix_add.h"
#include <iostream>
#include <cstring>
#include <acl/acl.h>
#include <acl/acl_op.h>
// 错误检查宏
#define CHECK_ACL(expr) do { \
aclError ret = (expr); \
if (ret != ACL_SUCCESS) { \
std::cerr << "ACL error at " << __FILE__ << ":" << __LINE__ \
<< " code: " << ret << std::endl; \
return ret; \
} \
} while(0)
int matrix_add_do(void* inputA, void* inputB, void* outputC,
int32_t totalElements, int32_t deviceId) {
// 设置当前设备
CHECK_ACL(aclrtSetDevice(deviceId));
// 获取运行模式(检查是Host还是Device)
aclrtRunMode runMode;
CHECK_ACL(aclrtGetRunMode(&runMode));
// 准备核函数参数
uint32_t blockDim = 1; // 可根据实际情况调整
uint32_t l2ctrl = 0; // L2控制参数
uint32_t buffer = reinterpret_cast<uint32_t>(inputA);
// 计算数据长度
uint32_t dataLength = totalElements * sizeof(float);
// 启动核函数
matrix_add_kernel<<<deviceId, blockDim, l2ctrl, buffer>>>(
blockDim, l2ctrl, buffer, dataLength);
// 等待核函数执行完成
CHECK_ACL(aclrtSynchronizeStream(nullptr));
return 0;
}
// 高级版本接口
int matrix_add_advanced_do(void* inputA, void* inputB, void* outputC,
int32_t totalElements, int32_t deviceId,
int32_t tileSize = 256) {
CHECK_ACL(aclrtSetDevice(deviceId));
// 更复杂的参数配置
uint32_t blockDim = 8; // 更多的并行块
uint32_t l2ctrl = 1; // 启用L2缓存优化
// 根据tileSize调整参数
if (tileSize <= 128) {
blockDim = 16;
} else if (tileSize <= 512) {
blockDim = 8;
} else {
blockDim = 4;
}
uint32_t buffer = reinterpret_cast<uint32_t>(inputA);
uint32_t dataLength = totalElements * sizeof(float);
// 启动高级版本核函数
matrix_add_advanced_kernel<<<deviceId, blockDim, l2ctrl, buffer>>>(
blockDim, l2ctrl, buffer, dataLength);
CHECK_ACL(aclrtSynchronizeStream(nullptr));
return 0;
}3.3.2 内存管理辅助函数
// host/memory_manager.cpp
#include "matrix_add.h"
#include <acl/acl.h>
#include <memory>
#include <vector>
class AscendMemoryManager {
public:
// 分配设备内存
static void* malloc_device(size_t size) {
void* ptr = nullptr;
aclError ret = aclrtMalloc(&ptr, size, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to allocate device memory: " << size << " bytes" << std::endl;
return nullptr;
}
return ptr;
}
// 释放设备内存
static void free_device(void* ptr) {
if (ptr) {
aclrtFree(ptr);
}
}
// 主机到设备数据拷贝
static int copy_host_to_device(void* devicePtr, const void* hostPtr, size_t size) {
return aclrtMemcpy(devicePtr, size, hostPtr, size, ACL_MEMCPY_HOST_TO_DEVICE);
}
// 设备到主机数据拷贝
static int copy_device_to_host(void* hostPtr, const void* devicePtr, size_t size) {
return aclrtMemcpy(hostPtr, size, devicePtr, size, ACL_MEMCPY_DEVICE_TO_HOST);
}
};
// 智能指针包装器
template<typename T>
class DevicePtr {
private:
T* ptr_;
size_t count_;
public:
DevicePtr(size_t count) : ptr_(nullptr), count_(count) {
ptr_ = static_cast<T*>(AscendMemoryManager::malloc_device(count * sizeof(T)));
}
~DevicePtr() {
if (ptr_) {
AscendMemoryManager::free_device(ptr_);
}
}
// 禁止拷贝
DevicePtr(const DevicePtr&) = delete;
DevicePtr& operator=(const DevicePtr&) = delete;
// 允许移动
DevicePtr(DevicePtr&& other) noexcept : ptr_(other.ptr_), count_(other.count_) {
other.ptr_ = nullptr;
other.count_ = 0;
}
DevicePtr& operator=(DevicePtr&& other) noexcept {
if (this != &other) {
if (ptr_) {
AscendMemoryManager::free_device(ptr_);
}
ptr_ = other.ptr_;
count_ = other.count_;
other.ptr_ = nullptr;
other.count_ = 0;
}
return *this;
}
T* get() const { return ptr_; }
size_t size() const { return count_; }
// 从主机数据初始化
int copy_from_host(const T* hostData, size_t count) {
size_t copyCount = (count < count_) ? count : count_;
return AscendMemoryManager::copy_host_to_device(ptr_, hostData, copyCount * sizeof(T));
}
// 拷贝到主机
int copy_to_host(T* hostData, size_t count) const {
size_t copyCount = (count < count_) ? count : count_;
return AscendMemoryManager::copy_device_to_host(hostData, ptr_, copyCount * sizeof(T));
}
};3.4 完整测试程序
// host/main.cpp
#include "matrix_add.h"
#include <iostream>
#include <vector>
#include <random>
#include <chrono>
#include <iomanip>
// 生成随机矩阵
std::vector<float> generate_random_matrix(int rows, int cols, float min = 0.0f, float max = 1.0f) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<float> dis(min, max);
std::vector<float> matrix(rows * cols);
for (int i = 0; i < rows * cols; ++i) {
matrix[i] = dis(gen);
}
return matrix;
}
// CPU参考实现
std::vector<float> matrix_add_cpu(const std::vector<float>& A,
const std::vector<float>& B,
int rows, int cols) {
std::vector<float> C(rows * cols);
for (int i = 0; i < rows * cols; ++i) {
C[i] = A[i] + B[i];
}
return C;
}
// 验证结果精度
bool verify_results(const std::vector<float>& expected,
const std::vector<float>& actual,
float tolerance = 1e-6f) {
if (expected.size() != actual.size()) {
std::cerr << "Size mismatch: expected " << expected.size()
<< ", got " << actual.size() << std::endl;
return false;
}
float max_error = 0.0f;
int error_count = 0;
for (size_t i = 0; i < expected.size(); ++i) {
float error = std::abs(expected[i] - actual[i]);
if (error > tolerance) {
if (error_count < 10) { // 只打印前10个错误
std::cout << "Error at index " << i << ": expected " << expected[i]
<< ", got " << actual[i] << " (error: " << error << ")" << std::endl;
}
error_count++;
}
if (error > max_error) {
max_error = error;
}
}
if (error_count > 0) {
std::cout << "Total errors: " << error_count << ", Max error: " << max_error << std::endl;
return false;
}
std::cout << "Verification passed! Max error: " << max_error << std::endl;
return true;
}
int main() {
// 初始化ACL环境
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to initialize ACL: " << ret << std::endl;
return -1;
}
// 测试参数
const int rows = 1024;
const int cols = 1024;
const int totalElements = rows * cols;
const int deviceId = 0;
std::cout << "Matrix Addition Test" << std::endl;
std::cout << "Matrix size: " << rows << " x " << cols << std::endl;
std::cout << "Total elements: " << totalElements << std::endl;
// 生成测试数据
std::cout << "Generating test data..." << std::endl;
auto matrixA = generate_random_matrix(rows, cols);
auto matrixB = generate_random_matrix(rows, cols);
// CPU参考计算
std::cout << "Computing reference result on CPU..." << std::endl;
auto startCpu = std::chrono::high_resolution_clock::now();
auto expectedResult = matrix_add_cpu(matrixA, matrixB, rows, cols);
auto endCpu = std::chrono::high_resolution_clock::now();
auto cpuDuration = std::chrono::duration_cast<std::chrono::microseconds>(endCpu - startCpu);
// 分配设备内存
std::cout << "Allocating device memory..." << std::endl;
DevicePtr<float> devA(totalElements);
DevicePtr<float> devB(totalElements);
DevicePtr<float> devC(totalElements);
if (!devA.get() || !devB.get() || !devC.get()) {
std::cerr << "Failed to allocate device memory" << std::endl;
aclFinalize();
return -1;
}
// 拷贝数据到设备
std::cout << "Copying data to device..." << std::endl;
if (devA.copy_from_host(matrixA.data(), totalElements) != 0 ||
devB.copy_from_host(matrixB.data(), totalElements) != 0) {
std::cerr << "Failed to copy data to device" << std::endl;
aclFinalize();
return -1;
}
// 执行Ascend C核函数
std::cout << "Executing Ascend C kernel..." << std::endl;
auto startGpu = std::chrono::high_resolution_clock::now();
ret = matrix_add_do(devA.get(), devB.get(), devC.get(), totalElements, deviceId);
auto endGpu = std::chrono::high_resolution_clock::now();
auto gpuDuration = std::chrono::duration_cast<std::chrono::microseconds>(endGpu - startGpu);
if (ret != 0) {
std::cerr << "Kernel execution failed: " << ret << std::endl;
aclFinalize();
return -1;
}
// 拷贝结果回主机
std::cout << "Copying result back to host..." << std::endl;
std::vector<float> actualResult(totalElements);
if (devC.copy_to_host(actualResult.data(), totalElements) != 0) {
std::cerr << "Failed to copy result from device" << std::endl;
aclFinalize();
return -1;
}
// 验证结果
std::cout << "Verifying results..." << std::endl;
bool success = verify_results(expectedResult, actualResult);
// 性能统计
std::cout << "\nPerformance Statistics:" << std::endl;
std::cout << "CPU time: " << cpuDuration.count() << " μs" << std::endl;
std::cout << "GPU time: " << gpuDuration.count() << " μs" << std::endl;
std::cout << "Speedup: " << std::fixed << std::setprecision(2)
<< (static_cast<double>(cpuDuration.count()) / gpuDuration.count())
<< "x" << std::endl;
// 清理资源
aclFinalize();
if (success) {
std::cout << "\n🎉 Matrix addition test PASSED!" << std::endl;
return 0;
} else {
std::cout << "\n❌ Matrix addition test FAILED!" << std::endl;
return -1;
}
}第四章:高级优化技巧与最佳实践
4.1 性能优化策略
4.1.1 数据分块优化
选择合适的分块大小对性能至关重要。太小的分块会导致过多的调度开销,太大的分块可能无法充分利用局部内存。
// 自适应分块策略
int32_t calculate_optimal_tile_size(int32_t totalElements, int32_t availableLocalMemory) {
constexpr int32_t MIN_TILE_SIZE = 64;
constexpr int32_t MAX_TILE_SIZE = 1024;
// 考虑三个tile(A、B、C)的存储需求
int32_t maxTileByMemory = availableLocalMemory / (3 * sizeof(float));
// 考虑任务并行度
int32_t maxTileByParallelism = totalElements / 8; // 至少8个并行任务
int32_t tileSize = std::min(maxTileByMemory, maxTileByParallelism);
tileSize = std::max(tileSize, MIN_TILE_SIZE);
tileSize = std::min(tileSize, MAX_TILE_SIZE);
// 调整为2的幂次,有利于内存对齐
tileSize = 1 << (31 - __builtin_clz(tileSize));
return tileSize;
}4.1.2 向量化优化
充分利用Ascend处理器的向量计算单元:
// 使用内置向量操作
void vectorized_add(const float* __restrict__ a,
const float* __restrict__ b,
float* __restrict__ c,
int32_t length) {
// 使用向量内在函数(如果可用)
#ifdef __ASCEND_VECTOR_OP__
for (int32_t i = 0; i < length; i += 4) {
float4 va = vload4(0, a + i);
float4 vb = vload4(0, b + i);
float4 vc = {va.x + vb.x, va.y + vb.y, va.z + vb.z, va.w + vb.w};
vstore4(vc, 0, c + i);
}
#else
// 回退到标量计算
for (int32_t i = 0; i < length; ++i) {
c[i] = a[i] + b[i];
}
#endif
}4.2 内存访问优化
4.2.1 数据对齐优化
确保内存访问符合硬件对齐要求:
// 对齐内存分配和访问
struct AlignedMemory {
static constexpr size_t ALIGNMENT = 64; // 缓存行对齐
static void* aligned_malloc(size_t size) {
void* ptr = nullptr;
posix_memalign(&ptr, ALIGNMENT, size);
return ptr;
}
static void aligned_free(void* ptr) {
free(ptr);
}
};4.2.2 bank冲突避免
在并行访问时优化内存访问模式:
// 优化内存访问模式以避免bank冲突
void bank_conflict_free_access(float* data, int32_t rows, int32_t cols) {
// 使用交错访问模式
constexpr int32_t INTERLEAVE = 8;
for (int32_t i = 0; i < rows; i += INTERLEAVE) {
for (int32_t j = 0; j < cols; ++j) {
for (int32_t k = 0; k < INTERLEAVE && i + k < rows; ++k) {
// 交错访问不同bank
process_element(data[(i + k) * cols + j]);
}
}
}
}第五章:调试技巧与性能分析
5.1 调试方法与工具
5.1.1 日志调试
在关键位置添加详细的日志输出:
// 调试日志宏
#ifdef DEBUG
#define DBG_PRINT(fmt, ...) \
do { \
printf("[DEBUG] %s:%d: " fmt "\n", __FILE__, __LINE__, ##__VA_ARGS__); \
} while(0)
#else
#define DBG_PRINT(fmt, ...) do {} while(0)
#endif
// 在核函数中使用调试日志
void debug_kernel(...) {
DBG_PRINT("Task %d started, processing %d elements", taskId, taskElements);
for (int32_t i = 0; i < taskElements; i += TILE_SIZE) {
DBG_PRINT("Processing tile starting at %d", i);
// ... 计算逻辑
DBG_PRINT("Tile %d completed", i / TILE_SIZE);
}
DBG_PRINT("Task %d completed", taskId);
}5.1.2 断言检查
添加运行时断言检查:
// 自定义断言宏
#define ASCEND_ASSERT(condition, message) \
do { \
if (!(condition)) { \
printf("Assertion failed: %s at %s:%d\n", message, __FILE__, __LINE__); \
/* 可以在这里添加更复杂的错误处理 */ \
return; \
} \
} while(0)
// 在核函数中使用断言
void safe_kernel(...) {
ASCEND_ASSERT(taskNum > 0, "Task number must be positive");
ASCEND_ASSERT(totalElements > 0, "Total elements must be positive");
// ... 核函数逻辑
}5.2 性能分析工具
5.2.1 使用Ascend性能分析器
# 启动性能分析
msprof --application=./matrix_add_test
# 生成性能报告
msprof --export=on --output=performance_report5.2.2 自定义性能计数
在代码中插入性能测量点:
class PerformanceTimer {
private:
std::chrono::high_resolution_clock::time_point startTime;
const char* sectionName;
public:
PerformanceTimer(const char* name) : sectionName(name) {
startTime = std::chrono::high_resolution_clock::now();
}
~PerformanceTimer() {
auto endTime = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(
endTime - startTime);
std::cout << "Section '" << sectionName << "' took: "
<< duration.count() << " μs" << std::endl;
}
};
// 使用性能计时器
void profiled_kernel(...) {
PerformanceTimer timer("Kernel Execution");
{
PerformanceTimer dataTimer("Data Loading");
// 数据加载代码
}
{
PerformanceTimer computeTimer("Computation");
// 计算代码
}
{
PerformanceTimer storeTimer("Result Storage");
// 结果存储代码
}
}第六章:进阶主题与扩展应用
6.1 支持不同数据类型的通用算子
扩展算子以支持多种数据类型:
// 模板化核函数(概念性,实际实现可能不同)
template<typename T>
void generic_matrix_add_kernel(...) {
// ... 通用实现
for (int32_t i = 0; i < vecLen; ++i) {
localC[i] = localA[i] + localB[i];
}
// ... 其余代码
}
// 类型特化包装器
void matrix_add_float_kernel(...) {
generic_matrix_add_kernel<float>(...);
}
void matrix_add_half_kernel(...) {
generic_matrix_add_kernel<half>(...);
}6.2 批量矩阵加法
支持批量处理多个矩阵:
void batch_matrix_add_kernel(...) {
// 批量处理逻辑
int32_t batchSize = ...;
for (int32_t batch = 0; batch < batchSize; ++batch) {
// 处理单个矩阵
process_single_matrix(batch, ...);
}
}6.3 算子融合技术
将矩阵加法与其他操作融合:
// 融合算子:矩阵加法后接ReLU激活
void fused_add_relu_kernel(...) {
for (int32_t i = 0; i < length; ++i) {
float sum = localA[i] + localB[i];
localC[i] = (sum > 0) ? sum : 0; // ReLU
}
}第七章:测试与验证体系
7.1 单元测试框架
建立完整的测试体系:
// 测试框架
class MatrixAddTest : public ::testing::Test {
protected:
void SetUp() override {
aclInit(nullptr);
}
void TearDown() override {
aclFinalize();
}
void test_matrix_size(int rows, int cols) {
// 具体的测试逻辑
}
};
TEST_F(MatrixAddTest, SmallMatrix) {
test_matrix_size(16, 16);
}
TEST_F(MatrixAddTest, LargeMatrix) {
test_matrix_size(2048, 2048);
}
TEST_F(MatrixAddTest, NonSquareMatrix) {
test_matrix_size(512, 1024);
}7.2 性能基准测试
建立性能基准:
class PerformanceBenchmark {
public:
static void run_benchmark() {
std::vector<std::pair<int, int>> testSizes = {
{256, 256}, {512, 512}, {1024, 1024},
{2048, 2048}, {4096, 4096}
};
for (auto [rows, cols] : testSizes) {
benchmark_single_size(rows, cols);
}
}
private:
static void benchmark_single_size(int rows, int cols) {
// 单个尺寸的性能测试
auto start = std::chrono::high_resolution_clock::now();
// 执行测试
run_matrix_add_test(rows, cols);
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
std::cout << "Size " << rows << "x" << cols << ": "
<< duration.count() << " μs" << std::endl;
}
};结语:从第一个算子到AI开发专家
通过本文的详细讲解,我们不仅实现了一个简单的矩阵加法算子,更建立了一套完整的Ascend C开发方法论。从环境搭建、理论基础、代码实现到调试优化,每个环节都包含了深入的技术细节和实践经验。
作为初学者,掌握第一个算子的开发过程具有重要意义。这不仅是技术学习的里程碑,更是开启AI计算开发大门的钥匙。随着对Ascend C理解的深入,你将能够处理更复杂的算子,优化更大型的模型,最终在AI计算领域游刃有余。
记住,优秀的AI计算工程师不仅需要掌握编程技巧,更需要深入理解硬件特性、算法原理和系统架构。持续学习、不断实践、深入思考,这将帮助你在AI计算的道路上走得更远。
现在,你已经具备了开发第一个Ascend C算子的能力,接下来可以尝试更复杂的算子实现,如矩阵乘法、卷积运算等,逐步构建完整的AI模型加速能力。祝你在昇腾AI计算的学习之旅中取得丰硕成果!
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)