
Ascend C 算子开发全攻略:环境搭建、编程实战与性能调优
·
第一章:初识Ascend C——昇腾计算语言的核心概念与优势解析
1.1 什么是Ascend C?
Ascend C是华为昇腾AI处理器专用的编程语言,专门为AI计算场景设计。作为CANN(Compute Architecture for Neural Networks)计算架构的重要组成部分,Ascend C在保持C++语法兼容性的同时,针对AI计算特性进行了深度优化和扩展。
核心特性:
- 专为AI计算优化:内置张量数据类型和丰富的AI计算接口
- 高性能并行计算:支持多核并行、向量化计算和流水线并行
- 硬件亲和性:直接映射到昇腾AI处理器的硬件架构
- 开发效率高:提供丰富的库函数和调试工具
1.2 Ascend C与传统C++的差异
虽然Ascend C基于C++语法,但在以下几个方面有显著区别:
数据类型扩展:
// 传统C++的基本数据类型
int, float, double
// Ascend C扩展的AI专用数据类型
Tensor, Half, LocalTensor, GlobalTensor
内存管理差异:
- Ascend C采用统一内存架构,简化了主机与设备间的数据交互
- 提供专用的内存分配器和数据搬运接口
- 支持核间通信和共享内存访问
1.3 Ascend C在AI计算中的优势
性能优势:
- 通过核函数直接操作AI Core,减少中间层开销
- 支持混合精度计算,平衡精度与性能
- 内置优化指令,充分发挥硬件算力
开发优势:
- 统一的编程模型,降低学习成本
- 丰富的调试和分析工具
- 完善的文档和社区支持
第二章:Ascend C开发环境搭建——从零开始配置算子开发平台
2.1 环境要求与准备工作
硬件要求:
- 昇腾AI处理器(Ascend 310/910)
- 至少16GB内存
- 100GB可用磁盘空间
软件依赖:
- Ubuntu 18.04/20.04 LTS
- CANN软件包(版本5.0.RC2或更高)
- CMake 3.12+
- GCC 7.3+
2.2 详细安装步骤
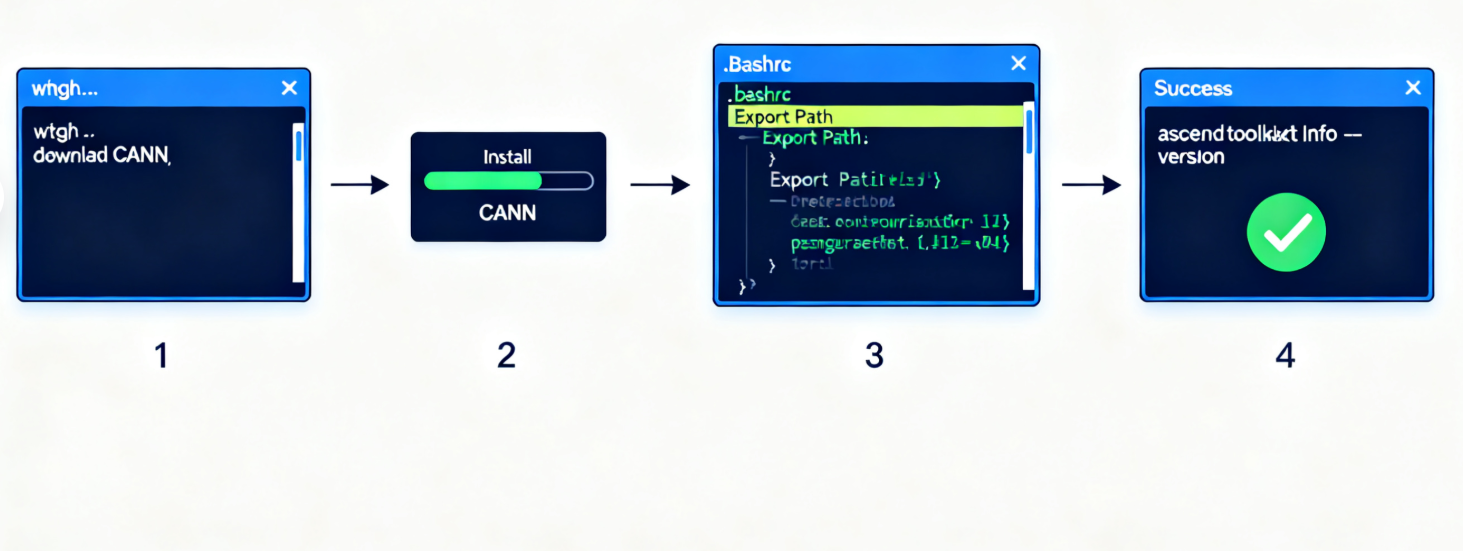
步骤1:下载并安装CANN工具包
# 下载CANN安装包
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/5.0.RC2/Ascend-cann-toolkit_5.0.RC2_linux-x86_64.run
# 安装CANN
chmod +x Ascend-cann-toolkit_5.0.RC2_linux-x86_64.run
./Ascend-cann-toolkit_5.0.RC2_linux-x86_64.run --install
步骤2:配置环境变量
# 编辑环境变量配置文件
vim ~/.bashrc
# 添加以下内容
export ASCEND_HOME=/usr/local/Ascend
export PATH=$ASCEND_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ASCEND_HOME/lib64:$LD_LIBRARY_PATH
# 使配置生效
source ~/.bashrc
步骤3:验证安装
# 检查CANN版本
ascend-toolkit-info --version
# 检查设备状态
npu-smi info
2.3 开发工具配置
IDE配置:
- 推荐使用VSCode + CANN插件
- 配置代码补全和语法高亮
- 集成调试工具链
项目管理:
- 使用CMake管理项目构建
- 配置编译选项和依赖关系
- 设置自动化测试流程
第三章:Ascend C算子编程实战——基础算子开发与调试技巧
3.1 第一个Ascend C算子:向量加法
让我们从一个简单的向量加法算子开始,了解Ascend C的基本编程模式。
算子定义:
#include "kernel_operator.h"
using namespace AscendC;
class VectorAddKernel {
public:
__aicore__ inline VectorAddKernel() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength) {
this->x = x;
this->y = y;
this->z = z;
this->totalLength = totalLength;
}
__aicore__ inline void Process() {
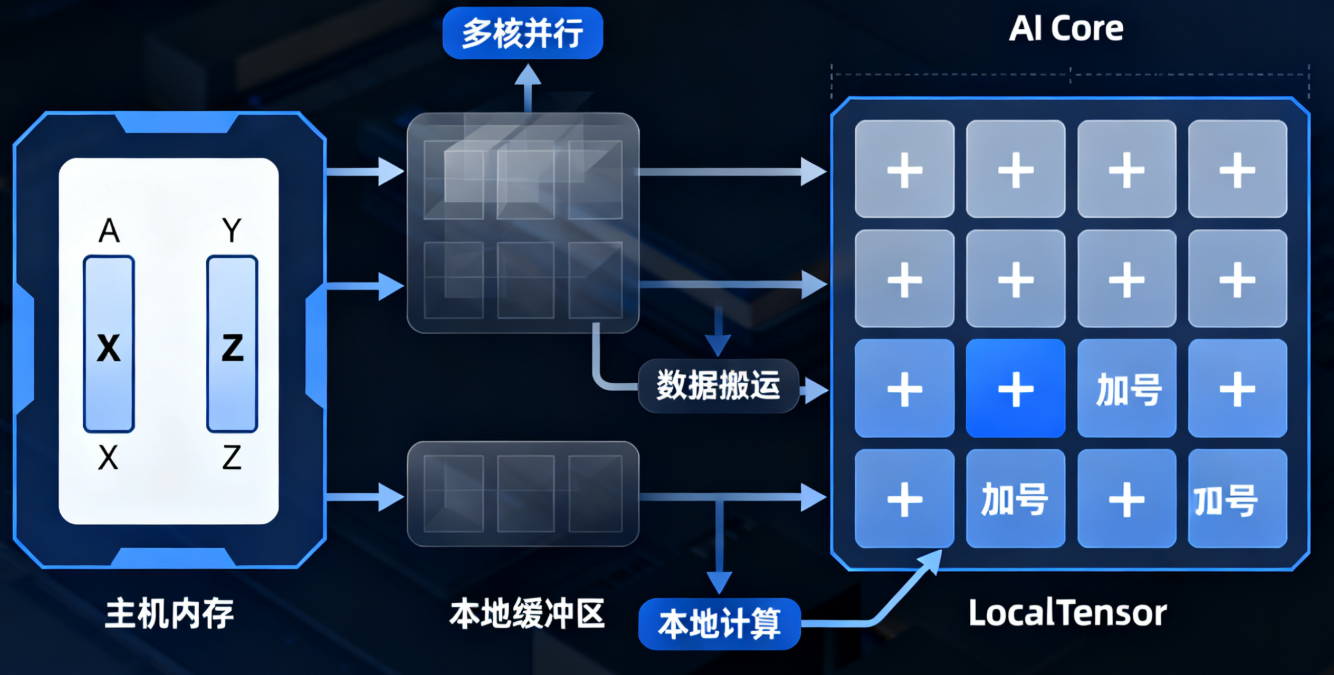
// 计算每个核需要处理的元素数量
uint32_t blockLength = totalLength / GetBlockNum();
uint32_t tileLength = blockLength / BUFFER_NUM;
// 本地张量缓冲区
LocalTensor<float> xLocal = outQueueX.AllocTensor<float>();
LocalTensor<float> yLocal = outQueueY.AllocTensor<float>();
LocalTensor<float> zLocal = outQueueZ.AllocTensor<float>();
// 数据搬运和计算流水线
for (uint32_t i = 0; i < TILE_NUM; i++) {
// 从全局内存加载数据
DataCopy(xLocal, x, tileLength);
DataCopy(yLocal, y, tileLength);
// 向量加法计算
Add(zLocal, xLocal, yLocal, tileLength);
// 结果写回全局内存
DataCopy(z, zLocal, tileLength);
// 更新指针位置
x += tileLength * sizeof(float);
y += tileLength * sizeof(float);
z += tileLength * sizeof(float);
}
}
private:
GM_ADDR x, y, z;
uint32_t totalLength;
};
// 核函数入口
extern "C" __global__ __aicore__ void vector_add(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength) {
VectorAddKernel op;
op.Init(x, y, z, totalLength);
op.Process();
}
3.2 矩阵乘法算子开发
矩阵乘法是深度学习中的核心操作,下面展示如何在Ascend C中实现高效的矩阵乘法。
核心实现:
class MatMulKernel {
public:
__aicore__ inline void Init(uint32_t M, uint32_t N, uint32_t K,
GM_ADDR A, GM_ADDR B, GM_ADDR C) {
this->M = M; this->N = N; this->K = K;
this->A = A; this->B = B; this->C = C;
// 初始化流水线
pipe.InitBuffer(inQueueA, BUFFER_SIZE);
pipe.InitBuffer(inQueueB, BUFFER_SIZE);
pipe.InitBuffer(outQueueC, BUFFER_SIZE);
}
__aicore__ inline void Process() {
// 分块矩阵乘法
uint32_t blockM = M / GetBlockDim();
uint32_t blockN = N / GetBlockNum();
for (uint32_t m = 0; m < blockM; m++) {
for (uint32_t n = 0; n < blockN; n++) {
// 加载A的分块
LocalTensor<float> aLocal = inQueueA.AllocTensor<float>();
DataCopy(aLocal, A + m * K, K);
// 加载B的分块
LocalTensor<float> bLocal = inQueueB.AllocTensor<float>();
DataCopy(bLocal, B + n, N);
// 矩阵乘法计算
LocalTensor<float> cLocal = outQueueC.AllocTensor<float>();
MatMul(cLocal, aLocal, bLocal, K, N);
// 结果写回
DataCopy(C + m * N + n, cLocal, 1);
}
}
}
};
3.3 调试技巧与最佳实践
调试工具使用:
# 使用msprof进行性能分析
msprof --application=./vector_add
# 使用gdb调试
ascend-gdb ./vector_add
# 内存访问检查
ascend-memcheck ./vector_add
常见问题排查:
- 核函数编译错误:检查语法和数据类型匹配
- 内存访问越界:使用边界检查工具验证
- 性能瓶颈:通过profiler分析计算和访存比例
第四章:性能优化与最佳实践——提升Ascend C算子效率的关键策略
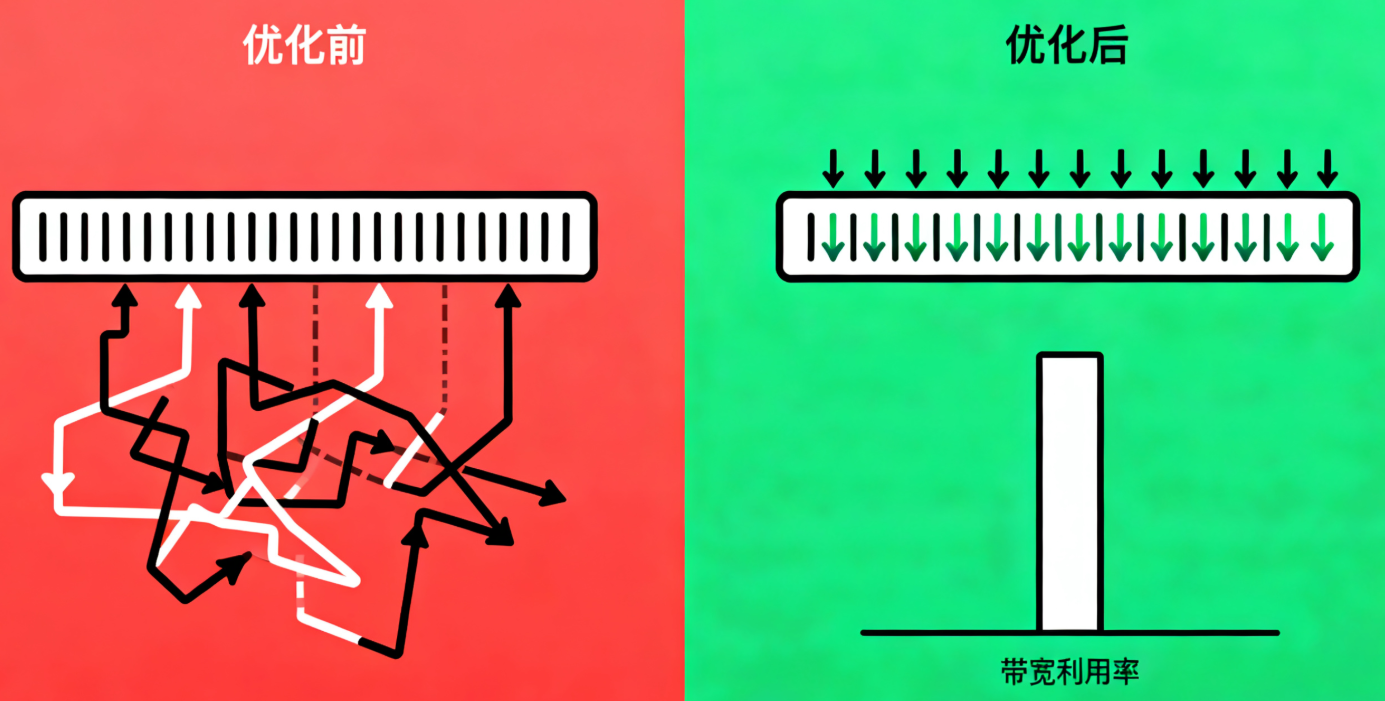
4.1 内存访问优化
数据局部性优化:
// 不好的做法:随机访问
for (int i = 0; i < N; i++) {
result[i] = input[random_index[i]];
}
// 优化做法:顺序访问
for (int i = 0; i < N; i++) {
result[i] = input[i];
}
内存对齐:
// 确保数据对齐到硬件最优边界
__attribute__((aligned(64))) float data[1024];
4.2 计算优化策略
向量化计算:
// 使用向量指令
Vector<float, 8> vecA, vecB, vecC;
vecC = vecA + vecB;
// 循环展开
#pragma unroll(4)
for (int i = 0; i < 256; i++) {
// 计算逻辑
}
4.3 并行化设计
多核并行:
// 核间任务划分
uint32_t blockSize = totalSize / GetBlockNum();
uint32_t startIdx = GetBlockIdx() * blockSize;
uint32_t endIdx = startIdx + blockSize;
流水线并行:
// 双缓冲流水线
Pipe pipe;
pipe.InitBuffer(inQueue, 2 * BUFFER_SIZE);
pipe.InitBuffer(outQueue, 2 * BUFFER_SIZE);
第五章:总结与展望——Ascend C在AI计算生态中的未来发展
5.1 学习收获总结
通过本系列学习,我们掌握了:
- Ascend C的基本语法和编程模型
- 算子开发的全流程:从环境搭建到调试优化
- 性能调优的关键技术和工具使用
- 实际项目中的最佳实践
5.2 进阶学习路径
推荐学习方向:
- 复杂算子开发:注意力机制、卷积神经网络算子
- 混合精度训练:FP16、INT8量化技术
- 分布式训练:多卡并行、模型并行
- 自定义硬件指令:充分发挥昇腾硬件特性
5.3 生态发展趋势
技术演进方向:
- 更智能的编译优化
- 自动算子生成技术
- 与主流深度学习框架的深度集成
- 跨平台兼容性提升
5.4 实践建议
项目实践:
- 从简单的向量操作开始,逐步过渡到复杂算子
- 重视性能分析和调优
- 参与开源社区,学习优秀实践
- 关注官方文档和版本更新
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)