
昇腾社区任务实战指南:从报名到PR提交的全流程协作开发
🌟昇腾AI开发实战指南摘要🌟 本文系统介绍昇腾社区开发全流程,聚焦CANN架构与AscendC编程模型,通过AddCustom算子案例详解AI加速器开发: 1️⃣ 开发基础 昇腾社区提供文档、工具链及ModelZoo资源 CANN作为软件枢纽连接框架与达芬奇架构硬件 2️⃣ 核心编程 采用异构计算与流水线并行设计 AscendC实现双缓冲优化,隐藏内存延迟 3️⃣ 实战案例 分步实现Host/
目录
🌟 摘要
本文为开发者提供一份详尽的昇腾社区任务实战指南,涵盖从活动报名、环境搭建、代码开发到PR(Pull Request)提交的全流程。文章将深入解析昇腾社区生态、CANN(Compute Architecture for Neural Networks)基础架构,并通过一个完整的AddCustom算子开发案例,展示如何在昇腾AI处理器上实现高性能算子。同时,文章将分享高效协作、性能优化及避坑技巧,帮助开发者快速融入昇腾社区,并完成高质量的代码贡献。关键技术点包括:昇腾社区资源利用、CANN与Ascend C核心开发模式、算子实现实战、PR提交规范以及性能调优方法论。
🏗️ 1. 昇腾社区与CANN架构概览
1.1 昇腾社区:生态入口与资源宝库
昇腾社区(hiascend.com)是华为昇腾计算产业的官方开发者平台,为开发者提供了从芯片到应用的全栈资源。
-
核心资源:
-
📚 文档与工具:提供芯片文档、CANN软件栈、MindSpore/Ascend C开发框架、MindStudio开发工具链等。
-
🤖 ModelZoo:包含大量预训练模型,覆盖计算机视觉、自然语言处理等领域,是学习与开发的重要参考。
-
🎓 培训与活动:如“CANN训练营”,为不同阶段的开发者提供学习路径和实战机会。
-
-
众智计划:华为推出的“昇腾众智计划”通过项目合作方式,吸引开发者共同丰富昇腾软件生态,是参与社区贡献的重要途径。
1.2 CANN:昇腾AI的软件基石
CANN是连接上层AI框架(如TensorFlow, PyTorch, MindSpore)和底层昇腾硬件的桥梁,其核心价值在于软硬件协同优化,充分发挥达芬奇架构的计算能力。
-
AscendCL(Ascend Computing Language):是CANN提供的底层C/C++ API,是开发者直接调用昇腾硬件能力的接口。
// 示例:AscendCL 环境初始化的核心代码片段 (C++) #include <acl/acl.h> int main() { aclInit(nullptr); // 初始化ACL运行环境 int deviceId = 0; aclError ret = aclrtSetDevice(deviceId); // 设置计算设备 // ... 后续的Context创建、内存分配等操作 aclFinalize(); // 最终化ACL return 0; }这段代码是昇腾开发的“Hello World”,正确执行意味着基础环境无误。
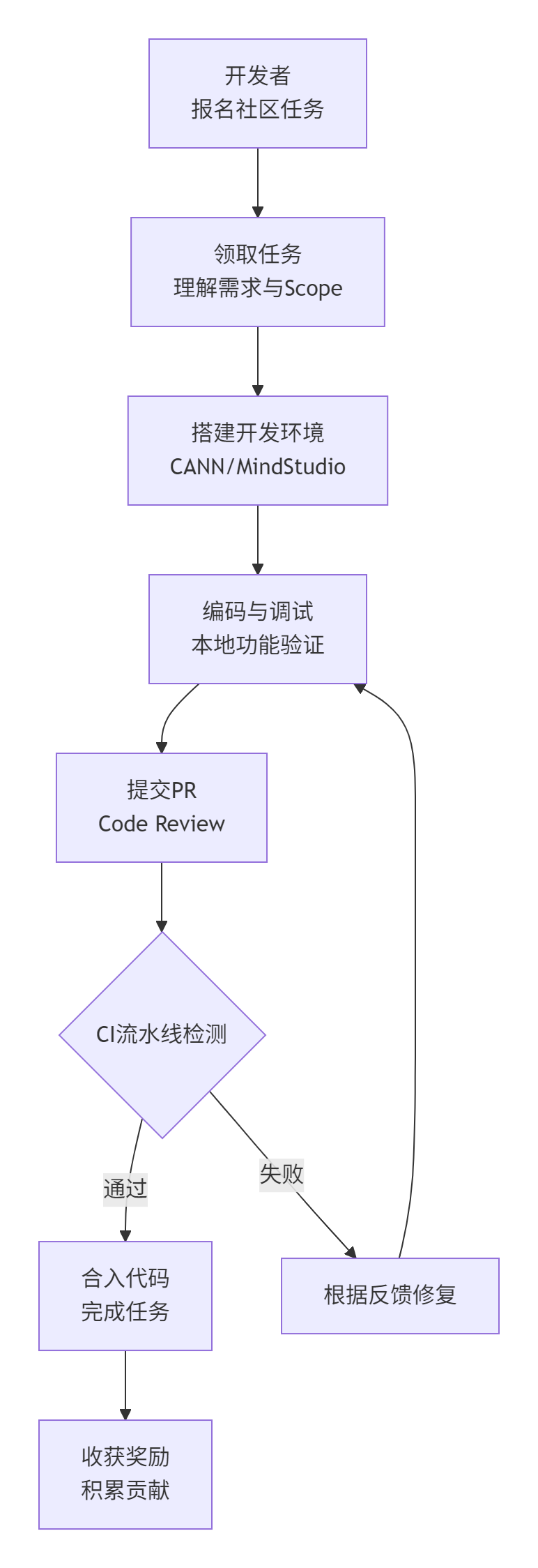
下面的Mermaid流程图概括了从报名到代码合入的完整旅程。
⚙️ 2. 核心开发理念与Ascend C编程模型
2.1 异构计算与“大规模并行”理念
昇腾AI处理器(如Ascend 910/310)专为AI计算的高并行性设计。理解其达芬奇架构(内置Cube、Vector等计算单元)和“主机-设备”分离的执行模型至关重要。编程时,需将计算密集型任务(Kernel)高效地映射到AI Core上。
2.2 Ascend C核函数与流水线
Ascend C是专为昇腾芯片设计的高性能编程语言,其核函数(Kernel)通常遵循以下范式:
// 示例:Ascend C 核函数的基本结构(以VectorAdd为例)
#include <kernel_operator.h>
using namespace AscendC;
class VectorAddKernel {
public:
__aicore__ void Init(GlobalTensor<half>& x, GlobalTensor<half>& y, GlobalTensor<half>& z, const AddTilingData& tiling) {
// 1. 初始化:分配管道(Pipe)内存,绑定队列,设置Tiling参数
pipe.InitBuffer(inQueueX, BUFFER_NUM, tiling.blockLength * sizeof(half));
// ... 其他初始化
}
__aicore__ void Process() {
// 2. 核心处理循环:通常实现多级流水线(如CopyIn,Compute,CopyOut)
for (int32_t i = 0; i < totalIterations; ++i) {
PipelineStage_DataLoad(i); // 数据搬运
if (i > 0) {
PipelineStage_Compute(i-1); // 计算(与数据搬运重叠)
}
// ... 其他阶段
}
// 处理流水线尾部
}
private:
TPipe pipe;
// ... 其他成员变量
};关键设计思想:通过双缓冲(Double Buffering) 和流水线并行,将数据搬运与计算操作最大程度地重叠,以隐藏内存访问延迟,提升硬件利用率。
🚀 3. 实战:AddCustom算子开发全流程
本章节将带领你完整实现一个AddCustom算子,并提交至昇腾社区。
3.1 任务领取与环境准备
-
📍 报名与任务选择:关注昇腾社区官网或“昇腾AI开发者”公众号,找到“众智计划”或“训练营”任务列表。选择一个适合入门的任务,例如“为昇腾ModelZoo贡献一个AddCustom算子”。
-
🛠️ 环境搭建:
-
方案一(推荐):云端开发。申请华为云ECS弹性云服务器,选择预装CANN和MindStudio的镜像,省去本地环境配置的麻烦。
-
方案二:本地开发。根据官方文档安装CANN Toolkit和MindStudio。确保可以通过
aclInit等基础API测试。
-
3.2 AddCustom算子代码实现
一个完整的算子通常包含Host侧代码(运行在CPU,负责任务调度、内存管理)和Device侧代码(Kernel,运行在AI Core)。
(1)Device侧Kernel实现(add_custom_kernel.cpp)
// Ascend C (CANN 7.0+)
// 实现向量加法: z = x + y
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2; // 双缓冲深度
constexpr int32_t VEC_SIZE = 8; // 向量化长度
class AddCustomKernel {
public:
__aicore__ void Init(GlobalTensor<half>& x, GlobalTensor<half>& y,
GlobalTensor<half>& z, const AddTilingData& tiling) {
// 初始化管道和队列
pipe.InitBuffer(inQueueX, BUFFER_NUM, tiling.blockLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, tiling.blockLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, tiling.blockLength * sizeof(half));
// ... 保存tiling参数和全局内存指针
}
__aicore__ void Process() {
int32_t totalTiles = ... // 计算总迭代次数
// 主流水线循环
for (int32_t i = 0; i < totalTiles + BUFFER_NUM - 1; ++i) {
if (i < totalTiles) {
PipelineStage_DataLoad(i); // 异步加载第i个数据块
}
if (i >= 1 && i < totalTiles + 1) {
PipelineStage_Compute(i-1); // 计算第i-1个数据块
}
if (i >= 2) {
PipelineStage_DataStore(i-2); // 写回第i-2个结果
}
}
}
private:
__aicore__ void PipelineStage_DataLoad(int32_t tileIndex) {
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
// 使用DMA进行数据搬运(CopyIn)
DataCopy(xLocal, globalX_[tileIndex * blockLength_], blockLength_);
inQueueX.EnQue(xLocal);
// ... 对y进行类似操作
}
__aicore__ void PipelineStage_Compute(int32_t tileIndex) {
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 核心计算:向量化加法
for (int32_t i = 0; i < blockLength_; i += VEC_SIZE) {
// 使用VecLoad/VecAdd/VecStore进行高效向量运算
Vec<half, VEC_SIZE> vecX = VecLoad<half, VEC_SIZE>(xLocal, i);
Vec<half, VEC_SIZE> vecY = VecLoad<half, VEC_SIZE>(yLocal, i);
Vec<half, VEC_SIZE> vecZ = VecAdd(vecX, vecY);
VecStore(zLocal, i, vecZ);
}
outQueueZ.EnQue(zLocal);
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ void PipelineStage_DataStore(int32_t tileIndex) {
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// 将结果从Local Memory拷贝回Global Memory(CopyOut)
DataCopy(globalZ_[tileIndex * blockLength_], zLocal, blockLength_);
outQueueZ.FreeTensor(zLocal);
}
TPipe pipe;
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
// ... 其他成员变量
};
// Kernel调用入口
extern "C" __global__ __aicore__ void add_custom(__gm__ half* x, __gm__ half* y, __gm__ half* z, __gm__ uint8_t* tiling) {
AddTilingData tilingData;
tilingData.Deserialize(reinterpret_cast<const char*>(tiling));
// ... 实例化并运行Kernel
}(2)Host侧代码与注册(add_custom.cc)
Host侧负责算子原型注册、形状推导、Tiling策略制定以及调用Device侧Kernel。
// C++代码 (基于AscendCL)
#include "acl/acl.h"
#include "add_custom_kernel.h"
// 算子原型注册
ACL_REGISTER_OP("AddCustom")
.Input("x", "float16")
.Input("y", "float16")
.Output("z", "float16")
.SetShapeFn([](ShapeContext* ctx) { // 形状推导函数
// 输出形状与输入相同
const auto& x_shape = ctx->GetInputShape(0);
ctx->SetOutputShape(0, x_shape);
return;
})
.SetTilingFn([](TilingContext* ctx) { // Tiling策略函数
AddTilingData tiling;
int32_t totalLength = ctx->GetInputTensor(0)->GetSize();
tiling.totalLength = totalLength;
// 计算最优分块大小,考虑内存、对齐等因素
tiling.blockLength = CalculateOptimalBlockLength(totalLength);
// ... 序列化tiling数据并传递给Kernel
});
// Kernel启动函数
void LaunchAddCustomKernel(aclStream stream, void* x, void* y, void* z, const AddTilingData& tiling) {
// 使用aclLaunchKernel启动在Device侧定义的add_custom Kernel
// ...
}3.3 本地验证与性能分析
-
功能验证:使用AscendCL或MindX SDK提供的测试框架,编写用例验证算子计算的正确性。
-
性能分析:利用MindStudio的Profiling工具分析算子性能。重点关注:
-
流水线利用率:是否达到80%以上?
-
内存带宽:是否存在瓶颈?
-
根据分析结果,调整Tiling策略、向量化长度等参数进行优化。
-
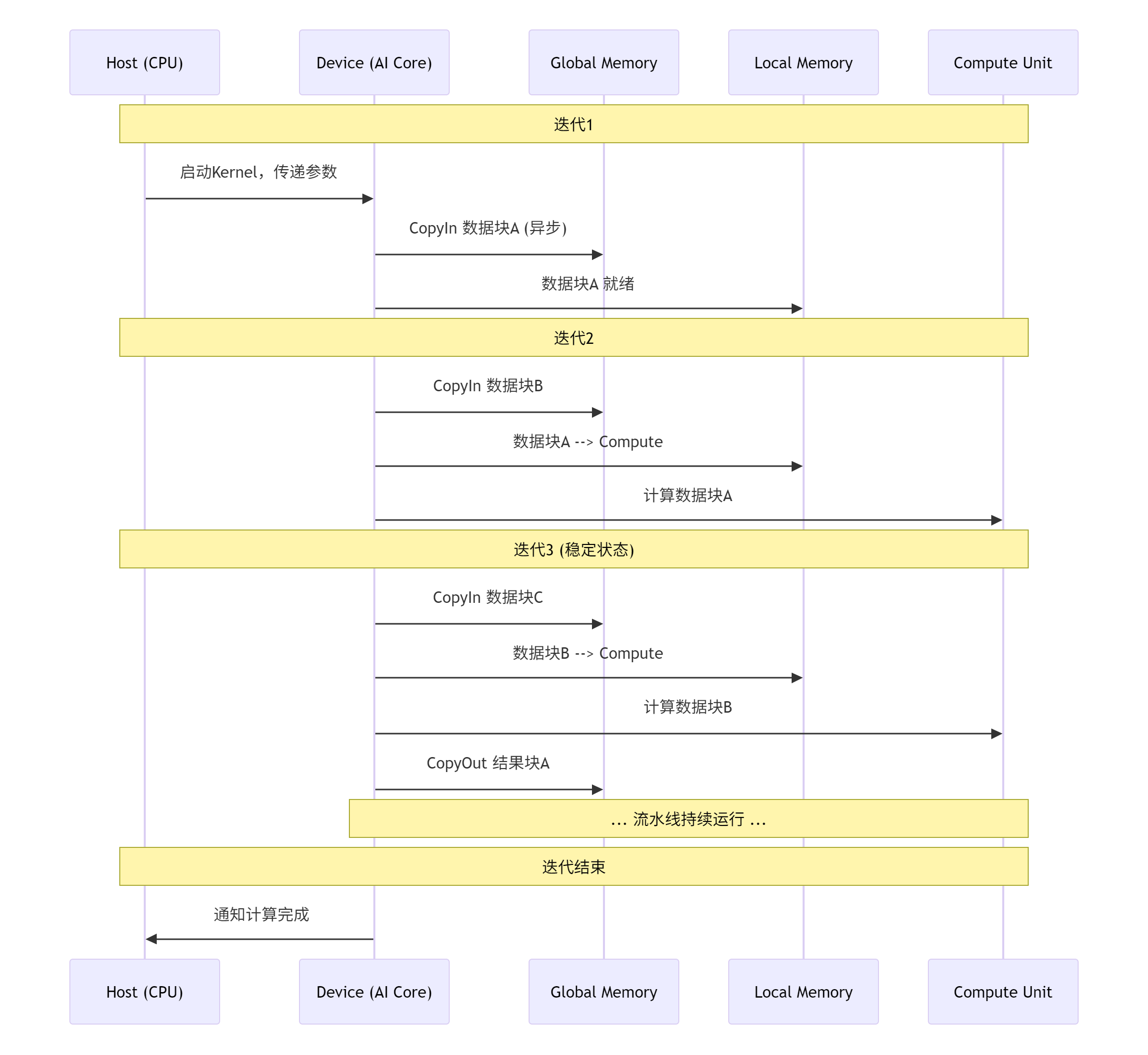
下面的Mermaid序列图清晰地展示了AddCustom算子在昇腾芯片上的执行时序,特别是计算与数据搬运的流水线重叠。
📮 4. PR提交、协作与代码合入
4.1 Fork、Clone与分支管理
-
Fork项目仓库:在Gitee或GitHub上找到目标仓库(如
ascend/samples),点击Fork到自己的账户下。 -
Clone到本地:
git clone https://gitee.com/your-username/samples.git -
创建特性分支:务必为新功能创建独立分支,这是规范协作的基础。
git checkout -b dev/add-custom-operator。
4.2 提交代码与Pull Request
-
代码与提交信息:将写好的算子代码放入项目指定目录。使用
git add和git commit提交。提交信息(Commit Message)务必清晰,例如:feat: add AddCustom operator for Ascend C。正文部分简要说明修改内容和动机。 -
推送到远程:
git push origin dev/add-custom-operator -
创建Pull Request:在你的Fork仓库页面,选择新建PR,目标仓库为原始项目,源分支是你的特性分支。PR描述应详细,包括:
-
动机:为何要增加这个算子?
-
实现方案:简要说明代码结构和关键设计。
-
测试结果:附上本地功能与性能测试的截图或数据。
-
关联Issue:如果对应社区任务,请关联相关Issue ID。
-
4.3 Code Review与CI
提交PR后,社区维护者(Maintainer)会进行代码审查(Code Review)。同时,CI/CD流水线(如门禁) 会自动触发,编译代码并运行基础测试。
-
应对Review评论:积极与维护者沟通,根据反馈修改代码,然后再次推送至同一分支,PR会自动更新。
-
处理CI失败:仔细查看CI报错日志,修复编译错误或测试失败问题。
🧠 5. 高级应用与优化技巧
5.1 企业级实践:性能优化深水区
-
自适应Tiling策略:根据输入数据规模动态调整分块大小,平衡不同形状下的性能。
-
算子融合:将连续的小算子(如Convolution + BatchNorm + ReLU)融合成一个大的复合算子,极大减少内核启动开销和数据搬运次数。这是企业级优化常见手段。
-
混合精度训练:在保证精度的前提下,在算子中使用FP16或BF16格式,提升计算吞吐量和减少内存占用。
5.2 故障排查指南(“踩坑”记录)
-
问题1:核函数编译失败,提示语法错误。
-
排查:检查Ascend C语法,特别是
__aicore__修饰符、GlobalTensor等用法是否正确。确保CANN版本与文档示例匹配。
-
-
问题2:运行结果不正确或出现NaN。
-
排查:首先在CPU侧用相同输入验证计算逻辑。在Device侧,可尝试使用
printf(有限支持)或通过将中间结果写回Host进行调试。检查数据搬运的偏移和长度计算。
-
-
问题3:性能不达预期。
-
排查:使用Profiling工具定位瓶颈。是计算单元空闲(计算瓶颈)还是频繁等待数据(内存瓶颈)?优化Tiling大小,确保内存访问连续和对齐,加深流水线深度。
-
💎 总结
通过本文的阐述,我们完成了从了解昇腾社区到实现并提交一个完整算子的全流程。关键在于:熟练掌握Ascend C编程模型与硬件特性,善用社区资源与工具,遵循规范的协作流程。希望这份指南能助你在昇腾开发之路上披荆斩棘,成为社区的活跃贡献者。
🔗 官方文档与参考链接
-
昇腾社区首页- 获取最新资讯、文档和软件下载的入口。
-
Ascend C 官方文档- 最权威的编程指南和API参考。
-
昇腾样例仓库- 包含大量算子开发示例代码,是学习的最佳实践库。
-
MindStudio 工具介绍- 集成开发环境,提供调试、性能分析等功能。
-
昇腾CANN训练营往期课程回顾- 在B站上观看往期训练营课程视频,直观学习。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)