
【昇腾CANN训练营·第十四期】Ascend C进阶之路:攻克Cube算子Tiling切分难题
本文探讨了Cube矩阵运算中的Tiling策略优化问题。相比向量运算的一维切分,矩阵运算需要在M、N、K三个维度进行联合优化,并考虑GM→L1→L0A/L0B→L0C→GM的复杂内存层级。文章提出了基于AICore架构的三维切分模型,详细分析了16字节对齐、L1/L0C缓冲区容量等硬件约束条件,并给出了启发式搜索算法实现。重点讨论了K-Loop模式、贪心扩展策略和数据类型位宽差异等关键问题,指出最
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在 Vector 向量算子开发中,Tiling 策略通常表现为对输入数据的一维线性切分。然而,进入 Cube 矩阵运算领域后,Tiling 的复杂度呈指数级上升:我们需要在 M(左矩阵行)、N(右矩阵列)、K(公共维度) 三个维度上进行联合优化。
此外,Cube 单元引入了更为复杂的内存层级结构:数据流路径从简单的 GM -> UB 演变为 GM -> L1 -> L0A/L0B -> L0C -> GM。若 Tiling 参数设计不当,极易导致 L1/L0 缓冲区溢出或数据搬运(MTE)开销过大,从而严重制约算子性能。
本期文章将基于 AI Core 的硬件架构,构建一套科学的 Cube Tiling 计算模型,解析多维切分的底层逻辑。
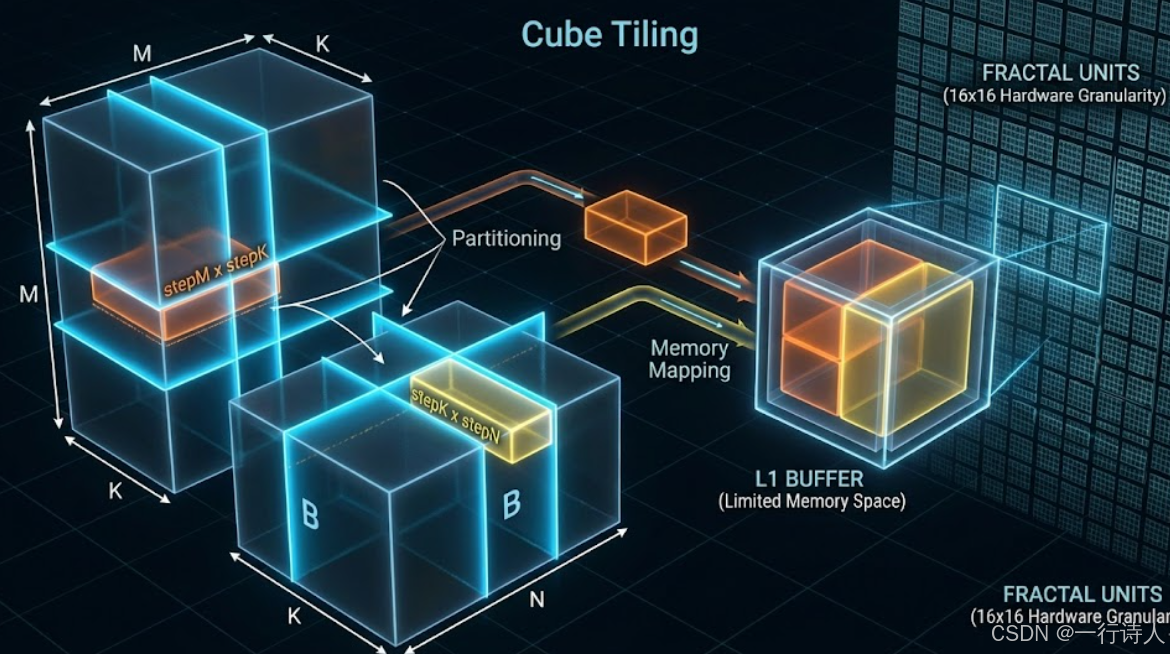
一、 核心模型:M-N-K 三维切分策略
假设矩阵乘法计算公式为 $C_{M \times N} = A_{M \times K} \times B_{K \times N}$。 为了适配 AI Core 的各级 Buffer 大小,我们需要定义三个关键的切分步长参数:
-
stepM:单次迭代处理的 C 矩阵行数。 -
stepN:单次迭代处理的 C 矩阵列数。 -
stepK:单次迭代加载的公共维度长度。
二、 硬件资源约束分析
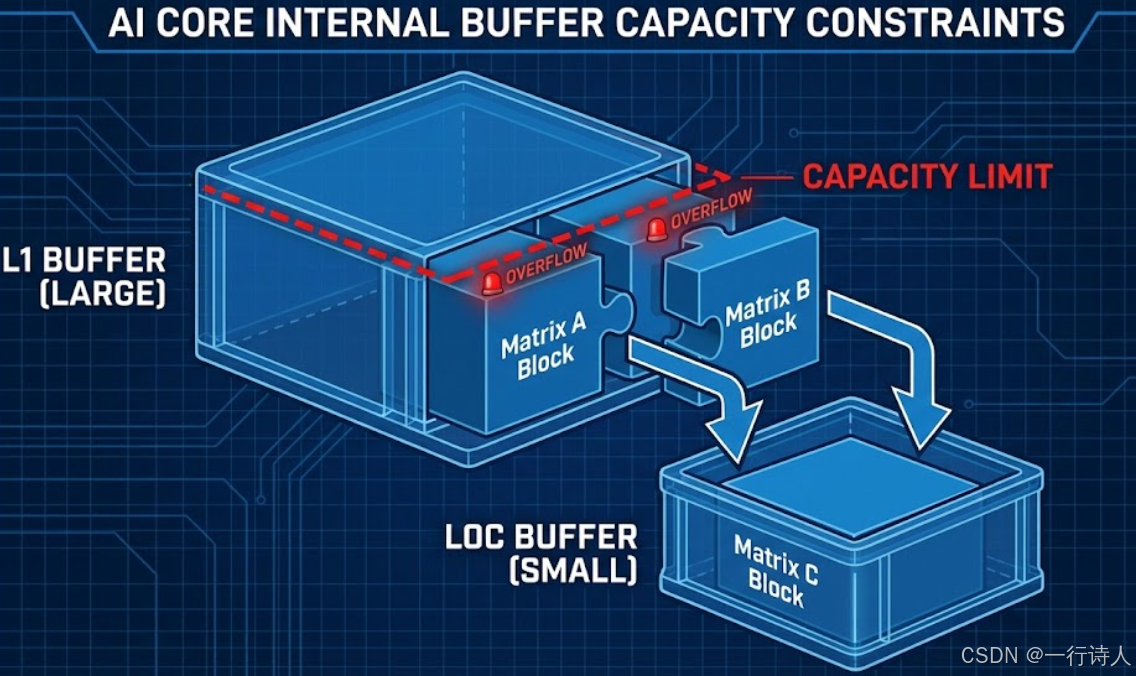
在设计 Tiling 算法时,必须严格遵循 AI Core 的硬件物理约束。这些约束构成了 Tiling 参数的解空间边界。
2.1 核心约束详解
-
分形(Fractal)对齐约束: AI Core 的 Cube 单元以 $16 \times 16$ 为基本计算粒度。 因此,
stepM和stepN必须向上对齐到 16。 -
L1 Buffer 容量约束: 单次迭代加载的左矩阵分块与右矩阵分块之和,必须小于 L1 Buffer 的有效容量(考虑双缓冲机制)。
$$(\text{stepM} \times \text{stepK} + \text{stepK} \times \text{stepN}) \times \text{sizeof(Type)} \le \frac{\text{L1\_Size}}{2}$$ -
L0C Buffer 容量约束: 计算结果矩阵分块必须能够容纳于 L0C Buffer(累加器)。
$$\text{stepM} \times \text{stepN} \times \text{sizeof(OutType)} \le \frac{\text{L0C\_Size}}{2}$$
三、 Tiling 策略推导与算法实现
优化目标:在满足上述约束的前提下,求解 stepM, stepN, stepK,使得数据搬运与计算的重叠率最高,计算密度最大。
3.1 策略分析:K-Loop 模式
由于 K 轴(输入通道)通常维度较大,无法一次性加载至片上内存,因此通常采用 K-Loop 策略:将 K 轴切分为多份,分批加载并累加。 在单次计算内部(Inner Loop),为了降低部分和(Partial Sum)在 L0C 与 GM 之间的搬运开销,原则上应优先最大化 stepM 和 stepN,而 stepK 则根据剩余 L1 容量进行适配。
3.2 启发式搜索算法
这是一个带约束的整数规划问题。在 Host 侧,我们通常采用启发式搜索算法来确定最优解:
-
初始化:设定 Base Block 为 16(FP16场景)。
-
固定 K 步长:预设
stepK为经验值(如 32 或 64),因为 K 轴对 L0C 容量无影响。 -
贪心扩展 M/N:
-
依据 L0C 约束检查:$\text{stepM} \times \text{stepN} \le \text{Max\_L0C\_Elements}$
-
依据 L1 约束检查:$(\text{stepM} + \text{stepN}) \times \text{stepK} \le \text{Max\_L1\_Elements}$
-
-
搜索策略:倾向于使
stepM和stepN接近正方形(如 128x128),此时数据加载量(周长)最小而计算量(面积)最大,算术强度(Arithmetic Intensity)最优。
3.3 Host 侧代码实现示例
// op_host/matmul_tiling.cpp
void ComputeTiling(uint32_t M, uint32_t N, uint32_t K, TilingData& tiling) {
// 1. 获取硬件平台存储参数
auto ascendcPlatform = platform_ascendc::PlatformAscendC(context->GetPlatformInfo());
uint32_t L1Size = 0;
uint32_t L0CSize = 0;
ascendcPlatform.GetCoreMemSize(platform_ascendc::CoreMemType::L1, L1Size);
ascendcPlatform.GetCoreMemSize(platform_ascendc::CoreMemType::L0C, L0CSize);
// 2. 计算双缓冲可用空间 (Double Buffer)
uint32_t maxL1 = L1Size / 2;
uint32_t maxL0C = L0CSize / 2;
// 3. 初始化 Step (需满足 16 对齐)
// 策略:优先保证 L0C 利用率
uint32_t stepM = 16;
uint32_t stepN = 16;
uint32_t stepK = 32; // 经验值初始化
// 4. 贪心算法扩展 M 和 N
// 逐步增加 stepM 和 stepN,直到触达硬件边界
while (true) {
bool grow = false;
// 尝试扩展 M 维度 (+16)
if ((stepM + 16) * stepN * 4 <= maxL0C && // L0C 容量检查 (假设输出为 float)
((stepM + 16) * stepK + stepN * stepK) * 2 <= maxL1) { // L1 容量检查 (假设输入为 half)
stepM += 16;
grow = true;
}
// 尝试扩展 N 维度 (+16)
if (stepM * (stepN + 16) * 4 <= maxL0C &&
(stepM * stepK + (stepN + 16) * stepK) * 2 <= maxL1) {
stepN += 16;
grow = true;
}
// 终止条件:无法继续扩展或已覆盖全量 Shape
if (!grow || stepM >= M || stepN >= N) break;
}
// 5. 边界修正:Step 不得超过原始 Shape
stepM = std::min(stepM, M);
stepN = std::min(stepN, N);
// 6. 序列化 TilingData
tiling.set_M(M); tiling.set_N(N); tiling.set_K(K);
tiling.set_stepM(stepM);
tiling.set_stepN(stepN);
tiling.set_stepK(stepK);
}
四、 常见问题与避坑指南
4.1 尾块(Tail Block)对齐处理
类似于 Vector 算子,Cube 运算同样存在尾块问题。 若 M=100,stepM=32,则最后一个分块大小为 4。然而 Cube 硬件强制要求 最小计算粒度为 16。 解决方案:必须在 Tiling 计算阶段执行向上对齐逻辑 ALIGN_UP(M, 16)。虽然物理上搬运和计算了 16 行,但需通过 Mask 或后续处理忽略无效数据。Matmul 高阶 API 内部处理了部分逻辑,但在 Host 侧 Tiling 时应始终基于对齐后的 Shape 进行规划。
4.2 数据类型位宽差异
输入矩阵通常为 FP16 (2 Bytes),而 Matmul 的累加结果(L0C)通常为 FP32 (4 Bytes)。 风险点:在计算 L0C 容量约束时,若未乘以 4,将导致 L0C 溢出,引发计算错误或死锁。
4.3 K 轴步长与流水线效率
-
若
stepK设置过小(如 16),虽然减轻了 L1 压力,但会导致 Inner Loop 迭代次数过多,指令发射与同步开销占比显著增加。 -
若
stepK设置过大,会挤压stepM/N的空间,降低计算并行度。 建议:通常将stepK维持在 32~256 之间,以平衡 IO 延迟与计算密度。
五、 总结
Cube 算子的性能优化核心在于 Tiling 策略的设计。一个优秀的 Tiling 算法应当具备以下特征:
-
最大化 L0C 利用率:使单次计算生成的 C 矩阵分块尽可能大,从而减少结果写回 GM 的频次。
-
M/N 维度平衡:倾向于生成接近正方形的分块,以获得最优的数据复用率。
-
严格遵循硬件约束:时刻关注 16 字节对齐与 Buffer 容量边界。
掌握了多维 Tiling 的设计方法,即掌握了释放 AI Core 极致算力的关键钥匙。
下期预告 算子开发不仅依赖代码实现,更依赖实验验证。如何量化评估 Tiling 策略的优劣?下一期,我们将引入 Ascend C 性能调优(下):使用 MSPROF 进行算子性能分析,通过微架构级的数据指标,精准定位性能瓶颈。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 27
27 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)