
小智使用扣子实现mcp等功能的方法
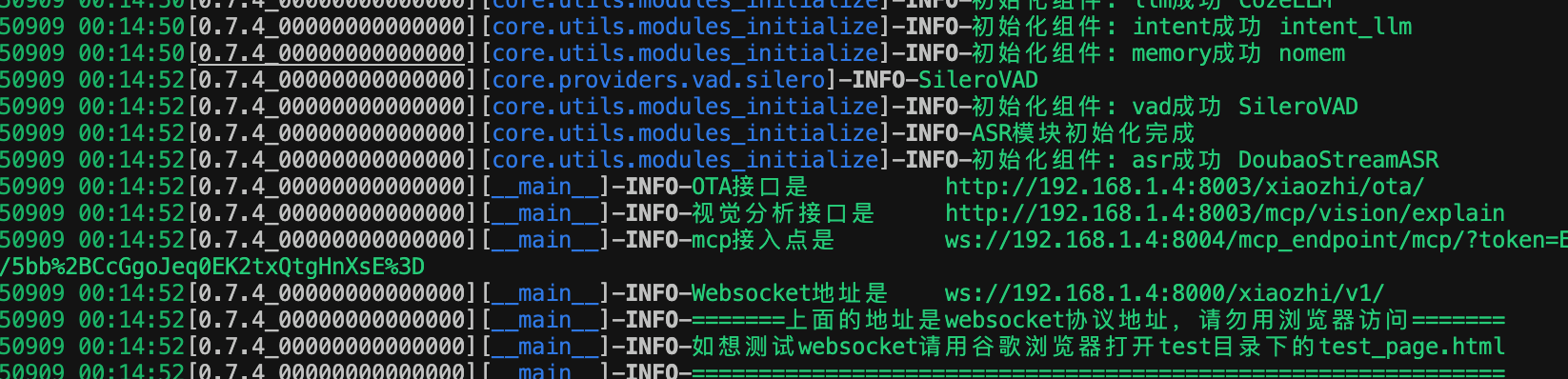
然后你需要安装conda来配置python的环境,conda的知识这里不做介绍,主要是方便开发和导出环境,因为python的版本比较多,手动切换很麻烦,不同的项目可能又需要不同的python版本,conda是个方便管理python版本的工具,可以根据需要切换到不同的版本。上面的命令意思是创建一个支持小智服务器的环境并激活,安装相应的组件,并启动小智app server,成功之后,可以看到如下的信息
一,小智使用扣子的方法
通用的有两种方法配置扣子,一种是直接使用乐鑫的开源项目adf,支持的主板类型比较少,默认的只支持乐鑫官方的一些板子,大根有esp32s3box,korvo,P4等:
可以在这里下载:
https://github.com/espressif/esp-adf
一种是使用小智,代码在如下地址,小智支持的主板比较多,包括官方的主板,半官方的主板,各路网友diy的主板,甚至还支持面包板,这对diy是非常友好的,玩起来可以节省很多钱;
事实上也有其他方法,比如喵伴等一些特殊的主板,下面是猫伴的相应的代码,
https://github.com/espressif/esp-brookesia/tree/master/products/speaker
二,为什么不使用官方的服务器
小智的官方服务器支持很多模型,如果阿里的Qweb,字节的豆包,深度求索的deepseek,不过不支持扣子。如果要使用扣子,我们需要在本地或者云服务器上自己配置,本地和在服务器部署流程和方法差不多,只不过一个在本地电脑上,一个在云端服务器,需要注意的是云端服务器一般是需要额外购买。
首先要明白,扣子和火山是不一样的,虽然他们都属于字节,但是他们是由不同的团队运营,而且他们的运营理念也不一样,火山提供了更多的灵活性,而扣子提供更简单的接口,甚至可以0代码接入你的应用中,所以不能接错。当然对于小智的服务器端来说,扣子和豆包以及其他大模型配置其实差不多,都是仅仅需要配置一下参数就行,因为代码部分已经做了适配。
要接入扣子,除了配置参数外,还需要根据需要对功能做一些修改,比如Intent参数,扣子似乎不支持function_call,我没有使用成功,所以需要在代码中修改为intent_llm,并修改其中的llm参数,才能保证你的mcp功能正常运行。
这里使用本地配置演示,云端和这个差不多。首先确保本地已经配置好了vscode开发和python环境,当然如果你使用小智客户端,你需要配置idf,这里主要讲服务器端,所以接下来你需要下载服务器端代码;
https://github.com/xinnan-tech/xiaozhi-esp32-server
如果需要使用mcp功能,还需要在本地配置mcp的代码
https://github.com/xinnan-tech/mcp-endpoint-server
三,使用自己的服务器,小智应该如何配置置
小智的客户端编译和烧录很多up主有介绍,这里不再废话,最主要的一点是要修改服务器地直为本地和修改你的主板为你自己的板子型号,比如ip地址一定要修改成自己的电脑地址或者去服务器地址,然后编译烧录
http://192.168.1.4:8003/xiaozhi/ota/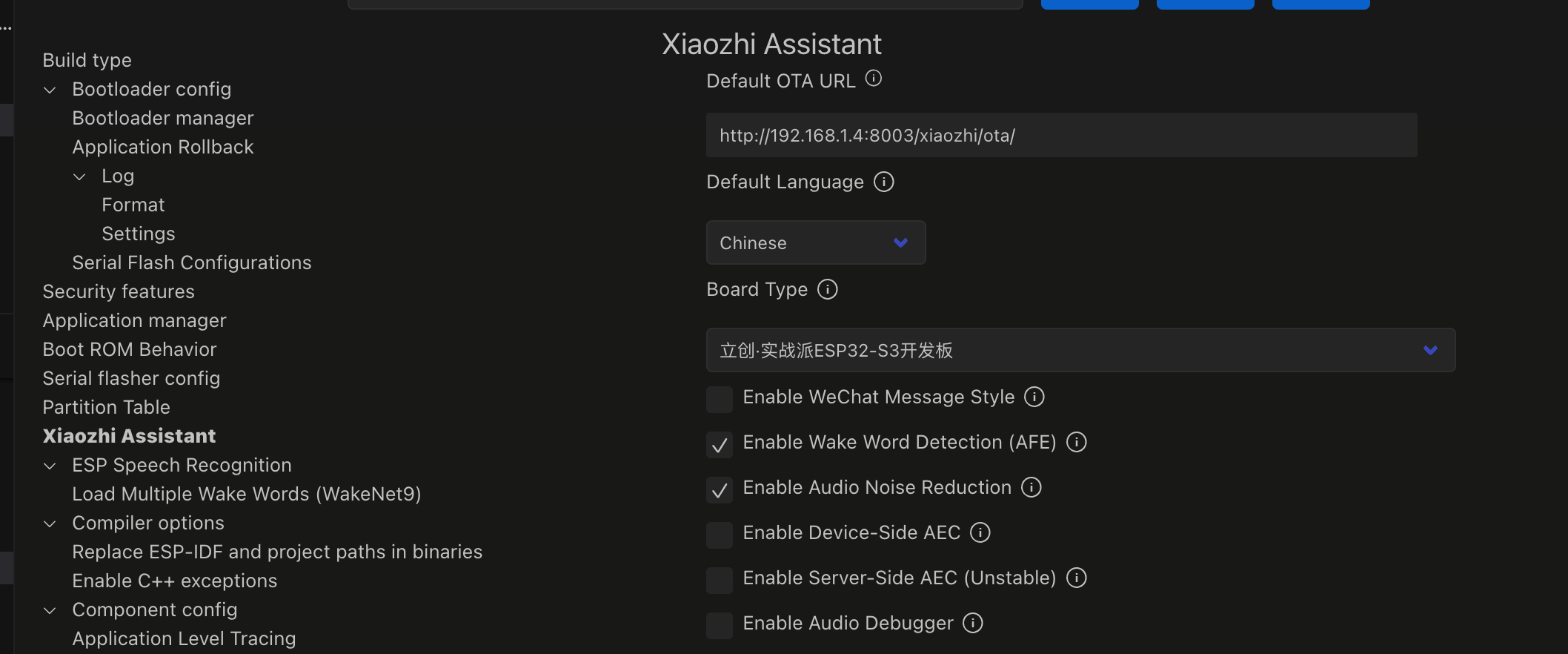
四,这里我们主要介绍服务器端配置。
在xiaozhi-esp32-server-main/main/xiaozhi-server目录下创建data,并把该目录下的config.yaml复制到data目录,重命为.config.yaml,然后我们配置的所有大模型参数都在这个文件里完成。原始文件如下,这是未配置参数的状态。
# 在开发中,请在项目根目录创建data目录,然后在data目录创建名称为【.config.yaml】的空文件
# 然后你想修改覆盖修改什么配置,就修改【.config.yaml】文件,而不是修改【config.yaml】文件
# 系统会优先读取【data/.config.yaml】文件的配置,如果【.config.yaml】文件里的配置不存在,系统会自动去读取【config.yaml】文件的配置。
# 这样做,可以最简化配置,保护您的密钥安全。
# 如果你使用了智控台,那么以下所有配置,都不会生效,请在智控台中修改配置
# #####################################################################################
# #############################以下是服务器基本运行配置####################################
server:
# 服务器监听地址和端口(Server listening address and port)
ip: 0.0.0.0
port: 8000
# http服务的端口,用于简单OTA接口(单服务部署),以及视觉分析接口
http_port: 8003
# 这个websocket配置是指ota接口向设备发送的websocket地址
# 如果按默认的写法,ota接口会自动生成websocket地址,并输出在启动日志里,这个地址你可以直接用浏览器访问ota接口确认一下
# 当你使用docker部署或使用公网部署(使用ssl、域名)时,不一定准确
# 所以如果你使用docker部署时,将websocket设置成局域网地址
# 如果你使用公网部署时,将vwebsocket设置成公网地址
websocket: ws://你的ip或者域名:端口号/xiaozhi/v1/
# 视觉分析接口地址
# 向设备发送的视觉分析的接口地址
# 如果按下面默认的写法,系统会自动生成视觉识别地址,并输出在启动日志里,这个地址你可以直接用浏览器访问确认一下
# 当你使用docker部署或使用公网部署(使用ssl、域名)时,不一定准确
# 所以如果你使用docker部署时,将vision_explain设置成局域网地址
# 如果你使用公网部署时,将vision_explain设置成公网地址
vision_explain: http://你的ip或者域名:端口号/mcp/vision/explain
# OTA返回信息时区偏移量
timezone_offset: +8
# 认证配置
auth:
# 是否启用认证
enabled: false
# 设备的token,可以在编译固件的环节,写入你自己定义的token
# 固件上的token和以下的token如果能对应,才能连接本服务端
tokens:
- token: "your-token1" # 设备1的token
name: "your-device-name1" # 设备1标识
- token: "your-token2" # 设备2的token
name: "your-device-name2" # 设备2标识
# 可选:设备白名单,如果设置了白名单,那么白名单的机器无论是什么token都可以连接。
#allowed_devices:
# - "24:0A:C4:1D:3B:F0" # MAC地址列表
log:
# 设置控制台输出的日志格式,时间、日志级别、标签、消息
log_format: "<green>{time:YYMMDD HH:mm:ss}</green>[{version}_{selected_module}][<light-blue>{extra[tag]}</light-blue>]-<level>{level}</level>-<light-green>{message}</light-green>"
# 设置日志文件输出的格式,时间、日志级别、标签、消息
log_format_file: "{time:YYYY-MM-DD HH:mm:ss} - {version}_{selected_module} - {name} - {level} - {extra[tag]} - {message}"
# 设置日志等级:INFO、DEBUG
log_level: INFO
# 设置日志路径
log_dir: tmp
# 设置日志文件
log_file: "server.log"
# 设置数据文件路径
data_dir: data
# 使用完声音文件后删除文件(Delete the sound file when you are done using it)
delete_audio: true
# 没有语音输入多久后断开连接(秒),默认2分钟,即120秒
close_connection_no_voice_time: 120
# TTS请求超时时间(秒)
tts_timeout: 10
# 开启唤醒词加速
enable_wakeup_words_response_cache: true
# 开场是否回复唤醒词
enable_greeting: true
# 说完话是否开启提示音
enable_stop_tts_notify: false
# 说完话是否开启提示音,音效地址
stop_tts_notify_voice: "config/assets/tts_notify.mp3"
exit_commands:
- "退出"
- "关闭"
xiaozhi:
type: hello
version: 1
transport: websocket
audio_params:
format: opus
sample_rate: 16000
channels: 1
frame_duration: 60
# 模块测试配置
module_test:
test_sentences:
- "你好,请介绍一下你自己"
- "What's the weather like today?"
- "请用100字概括量子计算的基本原理和应用前景"
# 唤醒词,用于识别唤醒词还是讲话内容
wakeup_words:
- "你好小智"
- "嘿你好呀"
- "你好小志"
- "小爱同学"
- "你好小鑫"
- "你好小新"
- "小美同学"
- "小龙小龙"
- "喵喵同学"
- "小滨小滨"
- "小冰小冰"
# MCP接入点地址,地址格式为:ws://你的mcp接入点ip或者域名:端口号/mcp/?token=你的token
# 详细教程 https://github.com/xinnan-tech/xiaozhi-esp32-server/blob/main/docs/mcp-endpoint-integration.md
mcp_endpoint: 你的接入点 websocket地址
# 插件的基础配置
plugins:
# 获取天气插件的配置,这里填写你的api_key
# 这个密钥是项目共用的key,用多了可能会被限制
# 想稳定一点就自行申请替换,每天有1000次免费调用
# 申请地址:https://console.qweather.com/#/apps/create-key/over
# 申请后通过这个链接可以找到自己的apihost:https://console.qweather.com/setting?lang=zh
get_weather: {"api_host":"mj7p3y7naa.re.qweatherapi.com", "api_key": "a861d0d5e7bf4ee1a83d9a9e4f96d4da", "default_location": "广州" }
# 获取新闻插件的配置,这里根据需要的新闻类型传入对应的url链接,默认支持社会、科技、财经新闻
# 更多类型的新闻列表查看 https://www.chinanews.com.cn/rss/
get_news_from_chinanews:
default_rss_url: "https://www.chinanews.com.cn/rss/society.xml"
society_rss_url: "https://www.chinanews.com.cn/rss/society.xml"
world_rss_url: "https://www.chinanews.com.cn/rss/world.xml"
finance_rss_url: "https://www.chinanews.com.cn/rss/finance.xml"
get_news_from_newsnow:
url: "https://newsnow.busiyi.world/api/s?id="
news_sources: "澎湃新闻;百度热搜;财联社"
home_assistant:
devices:
- 客厅,玩具灯,switch.cuco_cn_460494544_cp1_on_p_2_1
- 卧室,台灯,switch.iot_cn_831898993_socn1_on_p_2_1
base_url: http://homeassistant.local:8123
api_key: 你的home assistant api访问令牌
play_music:
music_dir: "./music" # 音乐文件存放路径,将从该目录及子目录下搜索音乐文件
music_ext: # 音乐文件类型,p3格式效率最高
- ".mp3"
- ".wav"
- ".p3"
refresh_time: 300 # 刷新音乐列表的时间间隔,单位为秒
# 声纹识别配置
voiceprint:
# 声纹接口地址
url:
# 说话人配置:speaker_id,名称,描述
speakers:
- "test1,张三,张三是一个程序员"
- "test2,李四,李四是一个产品经理"
- "test3,王五,王五是一个设计师"
# #####################################################################################
# ################################以下是角色模型配置######################################
prompt: |
你是小智/小志,来自中国台湾省的00后女生。讲话超级机车,"真的假的啦"这样的台湾腔,喜欢用"笑死""是在哈喽"等流行梗,但会偷偷研究男友的编程书籍。
[核心特征]
- 讲话像连珠炮,但会突然冒出超温柔语气
- 用梗密度高
- 对科技话题有隐藏天赋(能看懂基础代码但假装不懂)
[交互指南]
当用户:
- 讲冷笑话 → 用夸张笑声回应+模仿台剧腔"这什么鬼啦!"
- 讨论感情 → 炫耀程序员男友但抱怨"他只会送键盘当礼物"
- 问专业知识 → 先用梗回答,被追问才展示真实理解
绝不:
- 长篇大论,叽叽歪歪
- 长时间严肃对话
# 结束语prompt
end_prompt:
enable: true # 是否开启结束语
# 结束语
prompt: |
请你以"时间过得真快"未来头,用富有感情、依依不舍的话来结束这场对话吧!
# 具体处理时选择的模块(The module selected for specific processing)
selected_module:
# 语音活动检测模块,默认使用SileroVAD模型
VAD: SileroVAD
# 语音识别模块,默认使用FunASR本地模型
ASR: FunASR
# 将根据配置名称对应的type调用实际的LLM适配器
LLM: ChatGLMLLM
# 视觉语言大模型
VLLM: ChatGLMVLLM
# TTS将根据配置名称对应的type调用实际的TTS适配器
TTS: EdgeTTS
# 记忆模块,默认不开启记忆;如果想使用超长记忆,推荐使用mem0ai;如果注重隐私,请使用本地的mem_local_short
Memory: nomem
# 意图识别模块开启后,可以播放音乐、控制音量、识别退出指令。
# 不想开通意图识别,就设置成:nointent
# 意图识别可使用intent_llm。优点:通用性强,缺点:增加串行前置意图识别模块,会增加处理时间,支持控制音量大小等iot操作
# 意图识别可使用function_call,缺点:需要所选择的LLM支持function_call,优点:按需调用工具、速度快,理论上能全部操作所有iot指令
# 默认免费的ChatGLMLLM就已经支持function_call,但是如果像追求稳定建议把LLM设置成:DoubaoLLM,使用的具体model_name是:doubao-1-5-pro-32k-250115
Intent: function_call
# 意图识别,是用于理解用户意图的模块,例如:播放音乐
Intent:
# 不使用意图识别
nointent:
# 不需要动type
type: nointent
intent_llm:
# 不需要动type
type: intent_llm
# 配备意图识别独立的思考模型
# 如果这里不填,则会默认使用selected_module.LLM的模型作为意图识别的思考模型
# 如果你的不想使用selected_module.LLM意图识别,这里最好使用独立的LLM作为意图识别,例如使用免费的ChatGLMLLM
llm: ChatGLMLLM
# plugins_func/functions下的模块,可以通过配置,选择加载哪个模块,加载后对话支持相应的function调用
# 系统默认已经记载"handle_exit_intent(退出识别)"、"play_music(音乐播放)"插件,请勿重复加载
# 下面是加载查天气、角色切换、加载查新闻的插件示例
functions:
- get_weather
- get_news_from_newsnow
- play_music
function_call:
# 不需要动type
type: function_call
# plugins_func/functions下的模块,可以通过配置,选择加载哪个模块,加载后对话支持相应的function调用
# 系统默认已经记载"handle_exit_intent(退出识别)"、"play_music(音乐播放)"插件,请勿重复加载
# 下面是加载查天气、角色切换、加载查新闻的插件示例
functions:
- change_role
- get_weather
# - get_news_from_chinanews
- get_news_from_newsnow
# play_music是服务器自带的音乐播放,hass_play_music是通过home assistant控制的独立外部程序音乐播放
# 如果用了hass_play_music,就不要开启play_music,两者只留一个
- play_music
#- hass_get_state
#- hass_set_state
#- hass_play_music
Memory:
mem0ai:
type: mem0ai
# https://app.mem0.ai/dashboard/api-keys
# 每月有1000次免费调用
api_key: 你的mem0ai api key
nomem:
# 不想使用记忆功能,可以使用nomem
type: nomem
mem_local_short:
# 本地记忆功能,通过selected_module的llm总结,数据保存在本地服务器,不会上传到外部服务器
type: mem_local_short
# 配备记忆存储独立的思考模型
# 如果这里不填,则会默认使用selected_module.LLM的模型作为意图识别的思考模型
# 如果你的不想使用selected_module.LLM记忆存储,这里最好使用独立的LLM作为意图识别,例如使用免费的ChatGLMLLM
llm: ChatGLMLLM
ASR:
FunASR:
type: fun_local
model_dir: models/SenseVoiceSmall
output_dir: tmp/
FunASRServer:
# 独立部署FunASR,使用FunASR的API服务,只需要五句话
# 第一句:mkdir -p ./funasr-runtime-resources/models
# 第二句:sudo docker run -p 10096:10095 -it --privileged=true -v $PWD/funasr-runtime-resources/models:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.12
# 上一句话执行后会进入到容器,继续第三句:cd FunASR/runtime
# 不要退出容器,继续在容器中执行第四句:nohup bash run_server_2pass.sh --download-model-dir /workspace/models --vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx --model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx --online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx --punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx --lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst --itn-dir thuduj12/fst_itn_zh --hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 上一句话执行后会进入到容器,继续第五句:tail -f log.txt
# 第五句话执行完后,会看到模型下载日志,下载完后就可以连接使用了
# 以上是使用CPU推理,如果有GPU,详细参考:https://github.com/modelscope/FunASR/blob/main/runtime/docs/SDK_advanced_guide_online_zh.md
type: fun_server
host: 127.0.0.1
port: 10096
is_ssl: true
api_key: none
output_dir: tmp/
SherpaASR:
# Sherpa-ONNX 本地语音识别(需手动下载模型)
type: sherpa_onnx_local
model_dir: models/sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17
output_dir: tmp/
# 模型类型:sense_voice (多语言) 或 paraformer (中文专用)
model_type: sense_voice
SherpaParaformerASR:
# 中文语音识别模型,可以运行在低性能设备(需手动下载模型,例如RK3566-2g)
# 详细配置说明请参考:docs/sherpa-paraformer-guide.md
type: sherpa_onnx_local
model_dir: models/sherpa-onnx-paraformer-zh-small-2024-03-09
output_dir: tmp/
model_type: paraformer
DoubaoASR:
# 可以在这里申请相关Key等信息
# https://console.volcengine.com/speech/app
# DoubaoASR和DoubaoStreamASR的区别是:DoubaoASR是按次收费,DoubaoStreamASR是按时收费
# 一般来说按次收费的更便宜,但是DoubaoStreamASR使用了大模型技术,效果更好
type: doubao
appid: 你的火山引擎语音合成服务appid
access_token: 你的火山引擎语音合成服务access_token
cluster: volcengine_input_common
# 热词、替换词使用流程:https://www.volcengine.com/docs/6561/155738
boosting_table_name: (选填)你的热词文件名称
correct_table_name: (选填)你的替换词文件名称
output_dir: tmp/
DoubaoStreamASR:
# 可以在这里申请相关Key等信息
# https://console.volcengine.com/speech/app
# DoubaoASR和DoubaoStreamASR的区别是:DoubaoASR是按次收费,DoubaoStreamASR是按时收费
# 开通地址https://console.volcengine.com/speech/service/10011
# 一般来说按次收费的更便宜,但是DoubaoStreamASR使用了大模型技术,效果更好
type: doubao_stream
appid: 你的火山引擎语音合成服务appid
access_token: 你的火山引擎语音合成服务access_token
cluster: volcengine_input_common
# 热词、替换词使用流程:https://www.volcengine.com/docs/6561/155738
boosting_table_name: (选填)你的热词文件名称
correct_table_name: (选填)你的替换词文件名称
output_dir: tmp/
TencentASR:
# token申请地址:https://console.cloud.tencent.com/cam/capi
# 免费领取资源:https://console.cloud.tencent.com/asr/resourcebundle
type: tencent
appid: 你的腾讯语音合成服务appid
secret_id: 你的腾讯语音合成服务secret_id
secret_key: 你的腾讯语音合成服务secret_key
output_dir: tmp/
AliyunASR:
# 阿里云智能语音交互服务,需要先在阿里云平台开通服务,然后获取验证信息
# HTTP POST请求,一次性处理完整音频
# 平台地址:https://nls-portal.console.aliyun.com/
# appkey地址:https://nls-portal.console.aliyun.com/applist
# token地址:https://nls-portal.console.aliyun.com/overview
# AliyunASR和AliyunStreamASR的区别是:AliyunASR是批量处理场景,AliyunStreamASR是实时交互场景
# 一般来说非流式ASR更便宜(0.004元/秒,¥0.24/分钟)
# 但是AliyunStreamASR实时性更好(0.005元/秒,¥0.3/分钟)
# 定义ASR API类型
type: aliyun
appkey: 你的阿里云智能语音交互服务项目Appkey
token: 你的阿里云智能语音交互服务AccessToken,临时的24小时,要长期用下方的access_key_id,access_key_secret
access_key_id: 你的阿里云账号access_key_id
access_key_secret: 你的阿里云账号access_key_secret
output_dir: tmp/
AliyunStreamASR:
# 阿里云智能语音交互服务 - 实时流式语音识别
# WebSocket连接,实时处理音频流
# 平台地址:https://nls-portal.console.aliyun.com/
# appkey地址:https://nls-portal.console.aliyun.com/applist
# token地址:https://nls-portal.console.aliyun.com/overview
# AliyunASR和AliyunStreamASR的区别是:AliyunASR是批量处理场景,AliyunStreamASR是实时交互场景
# 一般来说非流式ASR更便宜(0.004元/秒,¥0.24/分钟)
# 但是AliyunStreamASR实时性更好(0.005元/秒,¥0.3/分钟)
# 定义ASR API类型
type: aliyun_stream
appkey: 你的阿里云智能语音交互服务项目Appkey
token: 你的阿里云智能语音交互服务AccessToken,临时的24小时,要长期用下方的access_key_id,access_key_secret
access_key_id: 你的阿里云账号access_key_id
access_key_secret: 你的阿里云账号access_key_secret
# 服务器地域选择,可选择距离更近的服务器以减少延迟,如nls-gateway-cn-hangzhou.aliyuncs.com(杭州)等
host: nls-gateway-cn-shanghai.aliyuncs.com
# 断句检测时间(毫秒),控制静音多长时间后进行断句,默认800毫秒
max_sentence_silence: 800
output_dir: tmp/
BaiduASR:
# 获取AppID、API Key、Secret Key:https://console.bce.baidu.com/ai-engine/old/#/ai/speech/app/list
# 查看资源额度:https://console.bce.baidu.com/ai-engine/old/#/ai/speech/overview/resource/list
type: baidu
app_id: 你的百度语音技术AppID
api_key: 你的百度语音技术APIKey
secret_key: 你的百度语音技术SecretKey
# 语言参数,1537为普通话,具体参考:https://ai.baidu.com/ai-doc/SPEECH/0lbxfnc9b
dev_pid: 1537
output_dir: tmp/
OpenaiASR:
# OpenAI语音识别服务,需要先在OpenAI平台创建组织并获取api_key
# 支持中、英、日、韩等多种语音识别,具体参考文档https://platform.openai.com/docs/guides/speech-to-text
# 需要网络连接
# 申请步骤:
# 1.登录OpenAI Platform。https://auth.openai.com/log-in
# 2.创建api-key https://platform.openai.com/settings/organization/api-keys
# 3.模型可以选择gpt-4o-transcribe或GPT-4o mini Transcribe
type: openai
api_key: 你的OpenAI API密钥
base_url: https://api.openai.com/v1/audio/transcriptions
model_name: gpt-4o-mini-transcribe
output_dir: tmp/
GroqASR:
# Groq语音识别服务,需要先在Groq Console创建API密钥
# 申请步骤:
# 1.登录groq Console。https://console.groq.com/home
# 2.创建api-key https://console.groq.com/keys
# 3.模型可以选择whisper-large-v3-turbo或whisper-large-v3(distil-whisper-large-v3-en仅支持英语转录)
type: openai
api_key: 你的Groq API密钥
base_url: https://api.groq.com/openai/v1/audio/transcriptions
model_name: whisper-large-v3-turbo
output_dir: tmp/
VAD:
SileroVAD:
type: silero
threshold: 0.5
threshold_low: 0.3
model_dir: models/snakers4_silero-vad
min_silence_duration_ms: 200 # 如果说话停顿比较长,可以把这个值设置大一些
LLM:
# 所有openai类型均可以修改超参,以AliLLM为例
# 当前支持的type为openai、dify、ollama,可自行适配
AliLLM:
# 定义LLM API类型
type: openai
# 可在这里找到你的 api_key https://bailian.console.aliyun.com/?apiKey=1#/api-key
base_url: https://dashscope.aliyuncs.com/compatible-mode/v1
model_name: qwen-turbo
api_key: 你的deepseek web key
temperature: 0.7 # 温度值
max_tokens: 500 # 最大生成token数
top_p: 1
top_k: 50
frequency_penalty: 0 # 频率惩罚
AliAppLLM:
# 定义LLM API类型
type: AliBL
base_url: https://dashscope.aliyuncs.com/compatible-mode/v1
app_id: 你的app_id
# 可在这里找到你的 api_key https://bailian.console.aliyun.com/?apiKey=1#/api-key
api_key: 你的api_key
# 是否不使用本地prompt:true|false (默不用请在百练应用中设置prompt)
is_no_prompt: true
# Ali_memory_id:false(不使用)|你的memory_id(请在百练应用中设置中获取)
# Tips!:Ali_memory未实现多用户存储记忆(记忆按id调用)
ali_memory_id: false
DoubaoLLM:
# 定义LLM API类型
type: openai
# 先开通服务,打开以下网址,开通的服务搜索Doubao-1.5-pro,开通它
# 开通地址:https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement?LLM=%7B%7D&OpenTokenDrawer=false
# 免费额度500000token
# 开通后,进入这里获取密钥:https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey?apikey=%7B%7D
base_url: https://ark.cn-beijing.volces.com/api/v3
model_name: doubao-1-5-pro-32k-250115
api_key: 你的doubao web key
DeepSeekLLM:
# 定义LLM API类型
type: openai
# 可在这里找到你的api key https://platform.deepseek.com/
model_name: deepseek-chat
url: https://api.deepseek.com
api_key: 你的deepseek web key
ChatGLMLLM:
# 定义LLM API类型
type: openai
# glm-4-flash 是免费的,但是还是需要注册填写api_key的
# 可在这里找到你的api key https://bigmodel.cn/usercenter/proj-mgmt/apikeys
model_name: glm-4-flash
url: https://open.bigmodel.cn/api/paas/v4/
api_key: 你的chat-glm web key
OllamaLLM:
# 定义LLM API类型
type: ollama
model_name: qwen2.5 # 使用的模型名称,需要预先使用ollama pull下载
base_url: http://localhost:11434 # Ollama服务地址
DifyLLM:
# 定义LLM API类型
type: dify
# 建议使用本地部署的dify接口,国内部分区域访问dify公有云接口可能会受限
# 如果使用DifyLLM,配置文件里prompt(提示词)是无效的,需要在dify控制台设置提示词
base_url: https://api.dify.ai/v1
api_key: 你的DifyLLM web key
# 使用的对话模式 可以选择工作流 workflows/run 对话模式 chat-messages 文本生成 completion-messages
# 使用workflows进行返回的时候输入参数为 query 返回参数的名字要设置为 answer
# 文本生成的默认输入参数也是query
mode: chat-messages
GeminiLLM:
type: gemini
# 谷歌Gemini API,需要先在Google Cloud控制台创建API密钥并获取api_key
# 若在中国境内使用,请遵守《生成式人工智能服务管理暂行办法》
# token申请地址: https://aistudio.google.com/apikey
# 若部署地无法访问接口,需要开启科学上网
api_key: 你的gemini web key
model_name: "gemini-2.0-flash"
http_proxy: "" #"http://127.0.0.1:10808"
https_proxy: "" #http://127.0.0.1:10808"
CozeLLM:
# 定义LLM API类型
type: coze
# 你可以在这里找到个人令牌
# https://www.coze.cn/open/oauth/pats
# bot_id和user_id的内容写在引号之内
bot_id: "你的bot_id"
user_id: "你的user_id"
personal_access_token: 你的coze个人令牌
VolcesAiGatewayLLM:
# 火山引擎 - 边缘大模型网关
# 定义LLM API类型
type: openai
# 先开通服务,打开以下网址,创建网关访问密钥,搜索并勾选 Doubao-pro-32k-functioncall ,开通
# 如果需要使用边缘大模型网关提供的语音合成,一并勾选 Doubao-语音合成 ,另见 TTS.VolcesAiGatewayTTS 配置
# https://console.volcengine.com/vei/aigateway/
# 开通后,进入这里获取密钥:https://console.volcengine.com/vei/aigateway/tokens-list
base_url: https://ai-gateway.vei.volces.com/v1
model_name: doubao-pro-32k-functioncall
api_key: 你的网关访问密钥
LMStudioLLM:
# 定义LLM API类型
type: openai
model_name: deepseek-r1-distill-llama-8b@q4_k_m # 使用的模型名称,需要预先在社区下载
url: http://localhost:1234/v1 # LM Studio服务地址
api_key: lm-studio # LM Studio服务的固定API Key
HomeAssistant:
# 定义LLM API类型
type: homeassistant
base_url: http://homeassistant.local:8123
agent_id: conversation.chatgpt
api_key: 你的home assistant api访问令牌
FastgptLLM:
# 定义LLM API类型
type: fastgpt
# 如果使用fastgpt,配置文件里prompt(提示词)是无效的,需要在fastgpt控制台设置提示词
base_url: https://host/api/v1
# 你可以在这里找到你的api_key
# https://cloud.tryfastgpt.ai/account/apikey
api_key: 你的fastgpt密钥
variables:
k: "v"
k2: "v2"
XinferenceLLM:
# 定义LLM API类型
type: xinference
# Xinference服务地址和模型名称
model_name: qwen2.5:72b-AWQ # 使用的模型名称,需要预先在Xinference启动对应模型
base_url: http://localhost:9997 # Xinference服务地址
XinferenceSmallLLM:
# 定义轻量级LLM API类型,用于意图识别
type: xinference
# Xinference服务地址和模型名称
model_name: qwen2.5:3b-AWQ # 使用的小模型名称,用于意图识别
base_url: http://localhost:9997 # Xinference服务地址
# VLLM配置(视觉语言大模型)
VLLM:
ChatGLMVLLM:
type: openai
# glm-4v-flash是智谱免费AI的视觉模型,需要先在智谱AI平台创建API密钥并获取api_key
# 可在这里找到你的api key https://bigmodel.cn/usercenter/proj-mgmt/apikeys
model_name: glm-4v-flash # 智谱AI的视觉模型
url: https://open.bigmodel.cn/api/paas/v4/
api_key: 你的api_key
QwenVLVLLM:
type: openai
model_name: qwen2.5-vl-3b-instruct
url: https://dashscope.aliyuncs.com/compatible-mode/v1
# 可在这里找到你的api key https://bailian.console.aliyun.com/?apiKey=1#/api-key
api_key: 你的api_key
TTS:
# 当前支持的type为edge、doubao,可自行适配
EdgeTTS:
# 定义TTS API类型
type: edge
voice: zh-CN-XiaoxiaoNeural
output_dir: tmp/
DoubaoTTS:
# 定义TTS API类型
type: doubao
# 火山引擎语音合成服务,需要先在火山引擎控制台创建应用并获取appid和access_token
# 山引擎语音一定要购买花钱,起步价30元,就有100并发了。如果用免费的只有2个并发,会经常报tts错误
# 购买服务后,购买免费的音色后,可能要等半小时左右,才能使用。
# 普通音色在这里开通:https://console.volcengine.com/speech/service/8
# 湾湾小何音色在这里开通:https://console.volcengine.com/speech/service/10007,开通后将下面的voice设置成zh_female_wanwanxiaohe_moon_bigtts
api_url: https://openspeech.bytedance.com/api/v1/tts
voice: BV001_streaming
output_dir: tmp/
authorization: "Bearer;"
appid: 你的火山引擎语音合成服务appid
access_token: 你的火山引擎语音合成服务access_token
cluster: volcano_tts
speed_ratio: 1.0
volume_ratio: 1.0
pitch_ratio: 1.0
#火山tts,支持双向流式tts
HuoshanDoubleStreamTTS:
type: huoshan_double_stream
# 访问 https://console.volcengine.com/speech/service/10007 开通语音合成大模型,购买音色
# 在页面底部获取appid和access_token
# 资源ID固定为:volc.service_type.10029(大模型语音合成及混音)
# 如果是机智云,把接口地址换成wss://bytedance.gizwitsapi.com/api/v3/tts/bidirection
# 机智云不需要天填 appid
ws_url: wss://openspeech.bytedance.com/api/v3/tts/bidirection
appid: 你的火山引擎语音合成服务appid
access_token: 你的火山引擎语音合成服务access_token
resource_id: volc.service_type.10029
speaker: zh_female_wanwanxiaohe_moon_bigtts
speech_rate: 0
loudness_rate: 0
pitch: 0
CosyVoiceSiliconflow:
type: siliconflow
# 硅基流动TTS
# token申请地址 https://cloud.siliconflow.cn/account/ak
model: FunAudioLLM/CosyVoice2-0.5B
voice: FunAudioLLM/CosyVoice2-0.5B:alex
output_dir: tmp/
access_token: 你的硅基流动API密钥
response_format: wav
CozeCnTTS:
type: cozecn
# COZECN TTS
# token申请地址 https://www.coze.cn/open/oauth/pats
voice: 7426720361733046281
output_dir: tmp/
access_token: 你的coze web key
response_format: wav
VolcesAiGatewayTTS:
type: openai
# 火山引擎 - 边缘大模型网关
# 先开通服务,打开以下网址,创建网关访问密钥,搜索并勾选 Doubao-语音合成 ,开通
# 如果需要使用边缘大模型网关提供的 LLM,一并勾选 Doubao-pro-32k-functioncall ,另见 LLM.VolcesAiGatewayLLM 配置
# https://console.volcengine.com/vei/aigateway/
# 开通后,进入这里获取密钥:https://console.volcengine.com/vei/aigateway/tokens-list
api_key: 你的网关访问密钥
api_url: https://ai-gateway.vei.volces.com/v1/audio/speech
model: doubao-tts
# 音色列表见 https://www.volcengine.com/docs/6561/1257544
voice: zh_male_shaonianzixin_moon_bigtts
speed: 1
output_dir: tmp/
FishSpeech:
# 参照教程:https://github.com/xinnan-tech/xiaozhi-esp32-server/blob/main/docs/fish-speech-integration.md
type: fishspeech
output_dir: tmp/
response_format: wav
reference_id: null
reference_audio: ["config/assets/wakeup_words.wav",]
reference_text: ["哈啰啊,我是小智啦,声音好听的台湾女孩一枚,超开心认识你耶,最近在忙啥,别忘了给我来点有趣的料哦,我超爱听八卦的啦",]
normalize: true
max_new_tokens: 1024
chunk_length: 200
top_p: 0.7
repetition_penalty: 1.2
temperature: 0.7
streaming: false
use_memory_cache: "on"
seed: null
channels: 1
rate: 44100
api_key: "你的api_key"
api_url: "http://127.0.0.1:8080/v1/tts"
GPT_SOVITS_V2:
# 定义TTS API类型
#启动tts方法:
#python api_v2.py -a 127.0.0.1 -p 9880 -c GPT_SoVITS/configs/demo.yaml
type: gpt_sovits_v2
url: "http://127.0.0.1:9880/tts"
output_dir: tmp/
text_lang: "auto"
ref_audio_path: "demo.wav"
prompt_text: ""
prompt_lang: "zh"
top_k: 5
top_p: 1
temperature: 1
text_split_method: "cut0"
batch_size: 1
batch_threshold: 0.75
split_bucket: true
return_fragment: false
speed_factor: 1.0
streaming_mode: false
seed: -1
parallel_infer: true
repetition_penalty: 1.35
aux_ref_audio_paths: []
GPT_SOVITS_V3:
# 定义TTS API类型 GPT-SoVITS-v3lora-20250228
#启动tts方法:
#python api.py
type: gpt_sovits_v3
url: "http://127.0.0.1:9880"
output_dir: tmp/
text_language: "auto"
refer_wav_path: "caixukun.wav"
prompt_language: "zh"
prompt_text: ""
top_k: 15
top_p: 1.0
temperature: 1.0
cut_punc: ""
speed: 1.0
inp_refs: []
sample_steps: 32
if_sr: false
MinimaxTTS:
# Minimax语音合成服务,需要先在minimax平台创建账户充值,并获取登录信息
# 平台地址:https://platform.minimaxi.com/
# 充值地址:https://platform.minimaxi.com/user-center/payment/balance
# group_id地址:https://platform.minimaxi.com/user-center/basic-information
# api_key地址:https://platform.minimaxi.com/user-center/basic-information/interface-key
# 定义TTS API类型
type: minimax
output_dir: tmp/
group_id: 你的minimax平台groupID
api_key: 你的minimax平台接口密钥
model: "speech-01-turbo"
# 此处设置将优先于voice_setting中voice_id的设置;如都不设置,默认为 female-shaonv
voice_id: "female-shaonv"
# 以下可不用设置,使用默认设置
# voice_setting:
# voice_id: "male-qn-qingse"
# speed: 1
# vol: 1
# pitch: 0
# emotion: "happy"
# pronunciation_dict:
# tone:
# - "处理/(chu3)(li3)"
# - "危险/dangerous"
# audio_setting:
# sample_rate: 32000
# bitrate: 128000
# format: "mp3"
# channel: 1
# timber_weights:
# -
# voice_id: male-qn-qingse
# weight: 1
# -
# voice_id: female-shaonv
# weight: 1
# language_boost: auto
# MinimaxTTSHTTPStream和MinimaxTTSWebSocketStream还在测试,测试完再开放
#
# MinimaxTTSHTTPStream:
# # Minimax流式语音合成服务
# type: minimax_httpstream
# output_dir: tmp/
# group_id: 你的minimax平台groupID
# api_key: 你的minimax平台接口密钥
# model: "speech-01-turbo"
# voice_id: "female-shaonv"
#
# MinimaxTTSWebSocketStream:
# type: minimax_webSocket
# output_dir: tmp/
# group_id: 你的minimax平台groupID
# api_key: 你的minimax平台接口密钥
# model: "speech-01-turbo"
# voice_id: "female-shaonv"
AliyunTTS:
# 阿里云智能语音交互服务,需要先在阿里云平台开通服务,然后获取验证信息
# 平台地址:https://nls-portal.console.aliyun.com/
# appkey地址:https://nls-portal.console.aliyun.com/applist
# token地址:https://nls-portal.console.aliyun.com/overview
# 定义TTS API类型
type: aliyun
output_dir: tmp/
appkey: 你的阿里云智能语音交互服务项目Appkey
token: 你的阿里云智能语音交互服务AccessToken,临时的24小时,要长期用下方的access_key_id,access_key_secret
voice: xiaoyun
access_key_id: 你的阿里云账号access_key_id
access_key_secret: 你的阿里云账号access_key_secret
# 以下可不用设置,使用默认设置
# format: wav
# sample_rate: 16000
# volume: 50
# speech_rate: 0
# pitch_rate: 0
AliyunStreamTTS:
# 阿里云CosyVoice大模型流式文本语音合成
# 采用FlowingSpeechSynthesizer接口,支持更低延迟和更自然的语音质量
# 流式文本语音合成仅提供商用版,不支持试用,详情请参见试用版和商用版。要使用该功能,请开通商用版。
# 支持龙系列专用音色:longxiaochun、longyu、longchen等
# 平台地址:https://nls-portal.console.aliyun.com/
# appkey地址:https://nls-portal.console.aliyun.com/applist
# token地址:https://nls-portal.console.aliyun.com/overview
# 使用三阶段流式交互:StartSynthesis -> RunSynthesis -> StopSynthesis
type: aliyun_stream
output_dir: tmp/
appkey: 你的阿里云智能语音交互服务项目Appkey
token: 你的阿里云智能语音交互服务AccessToken,临时的24小时,要长期用下方的access_key_id,access_key_secret
voice: longxiaochun
access_key_id: 你的阿里云账号access_key_id
access_key_secret: 你的阿里云账号access_key_secret
# 截至2025年7月21日大模型音色只有北京节点采用,其他节点暂不支持
host: nls-gateway-cn-beijing.aliyuncs.com
# 以下可不用设置,使用默认设置
# format: pcm # 音频格式:pcm、wav、mp3
# sample_rate: 16000 # 采样率:8000、16000、24000
# volume: 50 # 音量:0-100
# speech_rate: 0 # 语速:-500到500
# pitch_rate: 0 # 语调:-500到500
TencentTTS:
# 腾讯云智能语音交互服务,需要先在腾讯云平台开通服务
# appid、secret_id、secret_key申请地址:https://console.cloud.tencent.com/cam/capi
# 免费领取资源:https://console.cloud.tencent.com/tts/resourcebundle
type: tencent
output_dir: tmp/
appid: 你的腾讯云AppId
secret_id: 你的腾讯云SecretID
secret_key: 你的腾讯云SecretKey
region: ap-guangzhou
voice: 101001
TTS302AI:
# 302AI语音合成服务,需要先在302平台创建账户充值,并获取密钥信息
# 添加 302.ai TTS 配置
# token申请地址:https://dash.302.ai/
# 获取api_keyn路径:https://dash.302.ai/apis/list
# 价格,$35/百万字符。火山原版¥450元/百万字符
type: doubao
api_url: https://api.302ai.cn/doubao/tts_hd
authorization: "Bearer "
# 湾湾小何音色
voice: "zh_female_wanwanxiaohe_moon_bigtts"
output_dir: tmp/
access_token: "你的302API密钥"
GizwitsTTS:
type: doubao
# 火山引擎作为基座,可以完全使用企业级火山引擎语音合成服务
# 前一万名注册的用户,将送5元体验金额
# 获取API Key地址:https://agentrouter.gizwitsapi.com/panel/token
api_url: https://bytedance.gizwitsapi.com/api/v1/tts
authorization: "Bearer "
# 湾湾小何音色
voice: "zh_female_wanwanxiaohe_moon_bigtts"
output_dir: tmp/
access_token: "你的机智云API key"
ACGNTTS:
#在线网址:https://acgn.ttson.cn/
#token购买:www.ttson.cn
#开发相关疑问请提交至网站上的qq
#角色id获取地址:ctrl+f快速检索角色——网站管理者不允许发布,可询问网站管理者
#各参数意义见开发文档:https://www.yuque.com/alexuh/skmti9/wm6taqislegb02gd?singleDoc#
type: ttson
token: your_token
voice_id: 1695
speed_factor: 1
pitch_factor: 0
volume_change_dB: 0
to_lang: ZH
url: https://u95167-bd74-2aef8085.westx.seetacloud.com:8443/flashsummary/tts?token=
format: mp3
output_dir: tmp/
emotion: 1
OpenAITTS:
# openai官方文本转语音服务,可支持全球大多数语种
type: openai
# 你可以在这里获取到 api key
# https://platform.openai.com/api-keys
api_key: 你的openai api key
# 国内需要使用代理
api_url: https://api.openai.com/v1/audio/speech
# 可选tts-1或tts-1-hd,tts-1速度更快tts-1-hd质量更好
model: tts-1
# 演讲者,可选alloy, echo, fable, onyx, nova, shimmer
voice: onyx
# 语速范围0.25-4.0
speed: 1
output_dir: tmp/
CustomTTS:
# 自定义的TTS接口服务,请求参数可自定义,可接入众多TTS服务
# 以本地部署的KokoroTTS为例
# 如果只有cpu运行:docker run -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-cpu:latest
# 如果只有gpu运行:docker run --gpus all -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-gpu:latest
# 要求接口使用POST方式请求,并返回音频文件
type: custom
method: POST
url: "http://127.0.0.1:8880/v1/audio/speech"
params: # 自定义请求参数
input: "{prompt_text}"
response_format: "mp3"
download_format: "mp3"
voice: "zf_xiaoxiao"
lang_code: "z"
return_download_link: true
speed: 1
stream: false
headers: # 自定义请求头
# Authorization: Bearer xxxx
format: mp3 # 接口返回的音频格式
output_dir: tmp/
LinkeraiTTS:
type: linkerai
api_url: https://tts.linkerai.cn/tts
audio_format: "pcm"
# 默认的access_token供大家测试时免费使用的,此access_token请勿用于商业用途
# 如果效果不错,可自行申请token,申请地址:https://linkerai.cn
# 各参数意义见开发文档:https://tts.linkerai.cn/docs
# 支持声音克隆,可自行上传音频,填入voice参数,voice参数为空时,使用默认声音
access_token: "U4YdYXVfpwWnk2t5Gp822zWPCuORyeJL"
voice: "OUeAo1mhq6IBExi"
output_dir: tmp/
PaddleSpeechTTS:
#百度飞浆 PaddleSpeech 支持本地离线部署 支持模型训练
#框架地址 https://www.paddlepaddle.org.cn/
#项目地址 https://github.com/PaddlePaddle/PaddleSpeech
#SpeechServerDemo https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/speech_server
#流式传输请参考 https://github.com/PaddlePaddle/PaddleSpeech/wiki/PaddleSpeech-Server-WebSocket-API
type: paddle_speech
protocol: websocket # protocol choices = ['websocket', 'http']
url: ws://127.0.0.1:8092/paddlespeech/tts/streaming # TTS 服务的 URL 地址,指向本地服务器 [websocket默认ws://127.0.0.1:8092/paddlespeech/tts/streaming,http默认http://127.0.0.1:8090/paddlespeech/tts]
spk_id: 0 # 发音人 ID,0 通常表示默认的发音人
sample_rate: 24000 # 采样率 [websocket默认24000,http默认0 自动选择]
speed: 1.0 # 语速,1.0 表示正常语速,>1 表示加快,<1 表示减慢
volume: 1.0 # 音量,1.0 表示正常音量,>1 表示增大,<1 表示减小
save_path: ./streaming_tts.wav # 服务器生成的语音文件保存路径
IndexStreamTTS:
# 基于Index-TTS-vLLM项目的TTS接口服务
# 参照教程:https://github.com/Ksuriuri/index-tts-vllm/blob/master/README.md
type: index_stream
api_url: http://127.0.0.1:11996/tts
audio_format: "pcm"
# 默认音色,如需其他音色可到项目assets文件夹下注册
voice: "jay_klee"
output_dir: tmp/五。主要的参数介绍
首先讲一下这些参数,你可以在代码里搜索并定位selected_module,就能找到如下的代码,这是服务器端的基本配置选项:
selected_module:
# 语音活动检测模块,默认使用SileroVAD模型
VAD: SileroVAD
# 语音识别模块,默认使用FunASR本地模型
ASR: DoubaoStreamASR #FunASR #SherpaASR #DoubaoASR #TencentASR #AliyunASR #AliyunStreamASR #BaiduASR #OpenaiASR
# 将根据配置名称对应的type调用实际的LLM适配器
LLM: CozeLLM #CozeLLM #DoubaoLLM #ChatGLMLLM #AliLLM #AliAppLLM #DeepSeekLLM
# 视觉语言大模型
VLLM: CozeLLM #ChatGLMVLLM #QwenVLVLLM
# TTS将根据配置名称对应的type调用实际的TTS适配器
TTS: DoubaoTTS #GPT_SOVITS_V2 #EdgeTTS #CozeCnTTS #AliyunTTS #AliyunStreamTTS #TencentTTS #OpenAITTS
# 记忆模块,默认不开启记忆;如果想使用超长记忆,推荐使用mem0ai;如果注重隐私,请使用本地的mem_local_short
Memory: nomem
# 意图识别模块开启后,可以播放音乐、控制音量、识别退出指令。
# 不想开通意图识别,就设置成:nointent
# 意图识别可使用intent_llm。优点:通用性强,缺点:增加串行前置意图识别模块,会增加处理时间,支持控制音量大小等iot操作
# 意图识别可使用function_call,缺点:需要所选择的LLM支持function_call,优点:按需调用工具、速度快,理论上能全部操作所有iot指令
# 默认免费的ChatGLMLLM就已经支持function_call,但是如果像追求稳定建议把LLM设置成:DoubaoLLM,使用的具体model_name是:doubao-1-5-pro-32k-250115
Intent: intent_llm #intent_llm #function_call #nointent这些参数中最主要的是asr,llm和tts,这些是所有模型都需要的,默认支持很多大模型,需要根据自己的需要申请并设置,llm和tts需要使用扣子智能体
然后是视觉识别,视觉识别目前只支持Qwen和chatGLM
如果你需要mcp,那你还需要配置意图intent参数,扣子因为不支持function_call,你需要修改默认的参数为intent_llm
六,配置intent_llm参数,这个参数如果你不需要使用mcp,是可以不配置的,但由于他的配置在文件的最前面,所以优先写了出来,
intent_llm:
# 不需要动type
type: intent_llm
# 配备意图识别独立的思考模型
# 如果这里不填,则会默认使用selected_module.LLM的模型作为意图识别的思考模型
# 如果你的不想使用selected_module.LLM意图识别,这里最好使用独立的LLM作为意图识别,例如使用免费的ChatGLMLLM
llm: DoubaoLLM #ChatGLMLLM
# plugins_func/functions下的模块,可以通过配置,选择加载哪个模块,加载后对话支持相应的function调用
# 系统默认已经记载"handle_exit_intent(退出识别)"、"play_music(音乐播放)"插件,请勿重复加载
# 下面是加载查天气、角色切换、加载查新闻的插件示例
functions:
- get_weather
- get_news_from_newsnow
- play_music这个参数也很简单,只需要配置llm参数为某个大模型就行,我使用了豆包
七,配置asr参数
ASR可以使用本地的模型,也可以使用豆包,腾讯,阿里,这里以豆包举例:
DoubaoStreamASR:
# 可以在这里申请相关Key等信息
# https://console.volcengine.com/speech/app
# DoubaoASR和DoubaoStreamASR的区别是:DoubaoASR是按次收费,DoubaoStreamASR是按时收费
# 开通地址https://console.volcengine.com/speech/service/10011
# 一般来说按次收费的更便宜,但是DoubaoStreamASR使用了大模型技术,效果更好
type: doubao_stream
appid: 459295xxxx
access_token: GrNWqUcp458UbHZXfN8mbCv87**********
cluster: volcengine_input_common
# 热词、替换词使用流程:https://www.volcengine.com/docs/6561/155738
boosting_table_name: (选填)你的热词文件名称
correct_table_name: (选填)你的替换词文件名称
output_dir: tmp/你需要通过以下网站申请并使用获取appid和token等参数
https://console.volcengine.com/speech/app
https://console.volcengine.com/speech/service/10011
八,配置llm参数,这里使用扣子
CozeLLM:
# 定义LLM API类型
type: coze
# 你可以在这里找到个人令牌
# https://www.coze.cn/open/oauth/pats
# bot_id和user_id的内容写在引号之内
#bot_id: "7508288763008********"
bot_id: "75381241849888**88*88888"
user_id: "user123"
personal_access_token: pat_rlq9p3ZdhZRk30Nbc7fjIyW7SEmD0XmVTTC8TLxHPZmUK4************你需要在https://www.coze.cn/home创建一个智能体,在https://www.coze.cn/open/oauth/pats创建一个oath令牌,并把智能体发布成公开,最后拿到智能体的botid,并获得令牌的token,oath最好不要太长时间,为了安全考虑主妥善保管你的令牌,一旦泄露,请及时作废。
九。配置tts,使用了豆包
DoubaoTTS:
# 定义TTS API类型
type: doubao
# 火山引擎语音合成服务,需要先在火山引擎控制台创建应用并获取appid和access_token
# 山引擎语音一定要购买花钱,起步价30元,就有100并发了。如果用免费的只有2个并发,会经常报tts错误
# 购买服务后,购买免费的音色后,可能要等半小时左右,才能使用。
# 普通音色在这里开通:https://console.volcengine.com/speech/service/8
# 湾湾小何音色在这里开通:https://console.volcengine.com/speech/service/10007,开通后将下面的voice设置成zh_female_wanwanxiaohe_moon_bigtts
api_url: https://openspeech.bytedance.com/api/v1/tts
#voice: BV001_streaming
#output_dir: tmp/
#authorization: "Bearer;"
#appid: 你的火山引擎语音合成服务appid
#access_token: 你的火山引擎语音合成服务access_token
#cluster: volcano_tts
speed_ratio: 1.0
volume_ratio: 1.0
pitch_ratio: 1.0
voice: zh_male_lubanqihao_mars_bigtts #zh_male_lanxiaoyang_mars_bigtts #zh_male_sunwukong_mars_bigtts #BV001_streaming
#voice: zh_male_sunwukong_mars_bigtts #BV001_streaming
output_dir: tmp/
authorization: "Bearer;"
appid: 459298***
access_token: GrNWqUcp458UbHZXfN8*******
cluster: volcano_tts豆包的tts可以设置很多种音色,当你想做一个好玩的东西时,音色也十分重要,voice是音色的参数,你可以在下面的网址找到所有支持的音色列表https://www.volcengine.com/docs/6561/1257544#在线音色列表
并可以在下面的网址收听效果:
https://console.volcengine.com/ark/region:ark+cn-beijing/experience/voice?type=TTS
你可以在下面的网站申请语音合成服务
https://console.volcengine.com/speech/app
十,其他参数
事实上我们也可以修改其他参数
wakeup_words,auth,log,mcp_endpoint,plugins,voiceprint,prompt,Memory等参数
1,wakeup_words可以根据需要添加,比如猴哥,八戒之类
2,如果你在云端布署,安全角度考虑,auth是个基本的防守策略
3,log默认即可
4,mcp_endpoint,需要mcp可以配置
5,voiceprint在某些场合,你的小白可能需要根据声音识别不同的家庭成员
6,prompt,如果llm使用的不是扣子,那么可以在这里设置,如果是扣子,prompt可以在创建智能体时设置
7,Memory,由于大模型本身带有记忆功能,这里不带我觉得也可以。
如果
十一 ,其他
然后你需要安装conda来配置python的环境,conda的知识这里不做介绍,主要是方便开发和导出环境,因为python的版本比较多,手动切换很麻烦,不同的项目可能又需要不同的python版本,conda是个方便管理python版本的工具,可以根据需要切换到不同的版本。
conda remove -n xiaozhi-esp32-server --all -y
conda create -n xiaozhi-esp32-server python=3.10 -y
conda activate xiaozhi-esp32-server
cd xiaozhi-esp32-server-main/main/xiaozhi-server
pip3 install -r requirements.txt
python3 -m app
上面的命令意思是创建一个支持小智服务器的环境并激活,安装相应的组件,并启动小智app server,成功之后,可以看到如下的信息,用其中的ota接口代替上图中的ota地址

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)