
CANN算子:一次完整的端到端自定义算子开发实战(以动态 Shape AddCustom 为例)
通过本文对 AddCustom 动态 Shape 算子的端到端开发流程解析,可以看到 CANN 在算子生态上的体系化设计:从 msopgen 自动工程化生成、Ascend C 的 AI Core 编程范式,到 Host 侧的 Tiling 决策与原型注册,再到最终的算子包部署与 ST 测试,每一个环节都形成了清晰、可复用的标准路径。开发者不仅能够快速实现一个简单算子,也能在这一过程中理解昇腾 AI
CANN:一次完整的端到端自定义算子开发实战(以动态 Shape AddCustom 为例)
在昇腾 AI 全栈软件体系中,CANN(Compute Architecture for Neural Networks)承担着连接芯片能力与上层 AI 框架的重要角色。对于开发者而言,理解并掌握自定义算子的开发流程,不仅意味着能够扩展模型能力,更意味着可以直接控制 AI Core 的执行模式、内存调度策略和流水线并行,从而最大化硬件潜能。
本文将以一个典型的 动态 Shape AddCustom 算子 为例,从工程创建、Kernel 实现、Host 侧 Tiling、工程编译与部署,到最终的 ST 测试,完整展示 CANN 端到端算子开发的全流程。文章力求从整体视角解释每一步背后的工程逻辑与设计原则,而非简单介绍使用步骤。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、为什么需要自定义算子?
现有算子库往往能覆盖主流深度学习模型的常用算子,但实际业务中常会遇到:
- 针对特定场景优化的融合算子
- 业务特定的前处理后处理算子
- 性能瓶颈点需要替换核心原子算子
- 需要扩展现有算子的动态 shape 能力
这时,自定义算子就成为连接框架与 AI Core 的关键工具。自定义算子的完整实现同时涉及:
- Host 侧(Tiling、Shape 推导、Op 注册)
- AI Core 侧(Kernel)
- 工程构建与包部署
- 自动化算子 ST 测试
本文展示的 AddCustom 算子实现了最常见的矢量逐元素计算,也是大多数自定义算子的基础模板,因此非常适合作为入门级工程的教学示例。
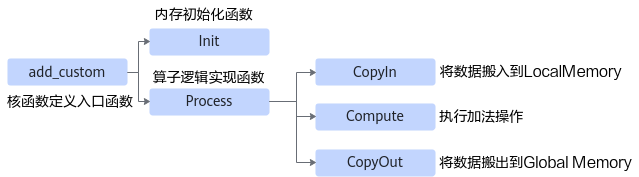
二、工程搭建:从原型文件到可编译工程
CANN 提供的 msopgen 工具是创建算子工程的一站式入口。开发者只需写好算子原型定义 JSON 文件,即可自动生成算子工程的基础模板。
1. 设计 AddCustom 的算子定义
AddCustom 接受两路 FP16 输入,输出同 shape 的 FP16 张量。原型文件的核心内容是:
- 输入 / 输出名称
- 支持格式
- 支持的数据类型
- 动态 shape 的支持方式
这一步的定义决定了后续 Host 侧的 Infra 如何自动解析算子请求,因此需要谨慎而清晰的结构。
2. 使用 msopgen 自动生成工程
msopgen 会自动生成:
build.sh / CMakePresets.json
host 代码模板(tiling、InferShape、注册代码)
kernel 代码模板
脚本工具与 CMake 工程文件
生成的工程结构完整、规整,足以作为后续所有 Ascend C 算子开发的标准起点。
三、Kernel 实现:理解 AI Core 的流水线计算模型
算子开发的核心落在 AI Core 的 Kernel 实现中。而 Ascend C 编程框架的设计理念是:强约束下的高性能流水化编程模型。
1. Ascend C 的核心执行结构
AI Core 的执行模型可抽象为:
Global Memory (GM) ↔ Local Memory (UB) ↔ Vector Units / Scalar Units
算子执行通常遵循三个阶段:
- CopyIn:从 GM 搬入到 UB
- Compute:矢量或标量计算
- CopyOut:从 UB 搬出到 GM
而 Ascend C 通过 TPipe + TQue 对本地缓冲进行管理,让开发者几乎无需手动处理 bank、对齐等细节。
2. Kernel 类结构设计:AddCustom 的三阶段流水线
AddCustom 的 Kernel 类整体结构可以概括为:
Init() // 内存初始化、队列初始化、分块信息计算
Process() // 执行循环流水
├── CopyIn()
├── Compute()
└── CopyOut()
技术要点包括:
(1)分块逻辑(Tiling)由 Host 下发
包括:
- 单核计算数据量
- tile 分块数量
- 每 tile 长度
- buffer 深度
Kernel 侧仅负责“按 Host 命令执行”。
(2)通过 GlobalTensor/LocalTensor 管理内存
开发者无需直接操作地址,只需声明:
GlobalTensor<DTYPE> xGm;
LocalTensor<DTYPE> xLocal;
即可完成搬运。
(3)使用 Add 接口执行矢量逐元素计算
Add(zLocal, xLocal, yLocal, tileLength);
这也是 CANN 为矢量原语封装的高性能接口。
四、Host 侧 Tiling:让 Kernel 获得恰当的执行策略
Kernel 负责执行,而如何执行、分多少块、每块大小多少则由 Host 侧的 Tiling 决定。
这一步是算子性能优化的关键点。
1. 定义 TilingData
Tiling 文件通常包括:
- 总数据量
- tile 份数
- BlockDim 配置
- Workspace 需求
- TilingKey
TilingData 会序列化传递给 Kernel,指导其按照策略执行。
2. TilingFunc:决定算子的执行策略
TilingFunc 的职责包括:
- 解析输入 Tensor 的 shape 信息
- 计算总元素数
- 选择 tileNum、blockDim
- 保存 TilingData
- 设置 TilingKey
例如:
tiling.set_totalLength(totalLength);
tiling.set_tileNum(TILE_NUM);
context->SetBlockDim(BLOCK_DIM);
context->SetTilingKey(1);
Tiling 是每个算子最具个性化的一环,决定算子最终能否跑到最佳状态。
五、算子注册:让 AddCustom 成为框架可识别的 Op
Host 侧注册代码主要完成:
- 输入 / 输出 / dtype / format 注册
- InferShape 绑定
- TilingFunc 注册
- 配置芯片型号
- 完成最终的 OP_ADD 注册
注册内容决定模型框架如何调用算子,因此必须结构化、清晰且符合规范。
六、工程编译与部署:打包成可加载的 OPP 插件
自定义算子的最终形态是一个 .run 安装包。
1. 配置 CMakePresets.json
主要是设置:
ASCEND_CANN_PACKAGE_PATH="/usr/local/Ascend/latest"
2. 执行 build.sh 完成编译
成功后会生成:
custom_opp_<os>_<arch>.run
3. 部署到系统 OPP 库
执行:
./custom_opp_ubuntu_x86_64.run
算子会被部署到:
vendors/customize/
必要时需要执行:
source <path>/vendors/<vendor>/bin/set_env.bash
使当前环境可以加载自定义算子。
七、ST 测试:验证算子行为是否正确
CANN 提供 msopst 作为统一的单算子测试框架。
核心流程包括:
- 编写测试用例 JSON
- 生成随机输入
- 调用算子执行
- 核对输出结果
- 自动化测试回归
这种方式保证算子部署后可在不同环境和不同芯片上稳定运行。
八、总结:自定义算子开发的内功心法
通过 AddCustom 的端到端实践,我们能够看到 CANN 自定义算子体系的关键特性:
1. Host + Kernel 的双端分工明确
- Kernel 专注搬运与计算
- Host 负责策略控制(Tiling、Shape)
2. Ascend C 框架让开发者无需深度接触硬件细节
LocalTensor、TPipe/TQue 让开发者专注算子逻辑本身。
3. msopgen 提供标准工程模板
保证统一规范与可维护性。
4. 完整 ST 测试体系确保算子可靠性
符合工业级工程体系要求。
5. 自定义算子开发的关键瓶颈在于 Tiling 策略
高性能算子的核心不在 Kernel,而在于:
- 如何分块
- 如何提升 UB 复用率
- 如何减少 GM IO
AddCustom 算子只是一个起点,更复杂的算子如卷积、融合算子、动态 shape 算子,都可以沿着同样的工程骨架进行扩展。

通过本文对 AddCustom 动态 Shape 算子的端到端开发流程解析,可以看到 CANN 在算子生态上的体系化设计:从 msopgen 自动工程化生成、Ascend C 的 AI Core 编程范式,到 Host 侧的 Tiling 决策与原型注册,再到最终的算子包部署与 ST 测试,每一个环节都形成了清晰、可复用的标准路径。开发者不仅能够快速实现一个简单算子,也能在这一过程中理解昇腾 AI Core 硬件的数据流模型、流水线执行机制以及 CANN 工具链的协同方式。随着算子复杂度增加,同样的流程依然适用,只需要在 Kernel、Tiling 和 ShapeInfer 上持续扩展逻辑即可。掌握这一整套方法,不仅能够提升开发效率,更能在性能调优与定制算子创新上打下坚实基础,让算子真正做到“可定义、可扩展、可优化”,也让昇腾 AI 的算力价值能够最大化地释放。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 40
40 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)