
深入理解华为 CANN 中的 SPMD 模型与核函数:Ascend 算子并行编程实践(训练营深度实战篇)
在昇腾 AI 处理器的算子开发体系中,Ascend C 构建了一套完整的设备端编程模型,让开发者能够以接近传统 C/C++ 的形式,直接操控多核 AI Core 的执行。无论是高性能数学库、深度学习算子,还是自定义算子,都依托于一个核心思想:SPMD(Single Program, Multiple Data)并行模型。
深入理解华为 CANN 中的 SPMD 模型与核函数:Ascend 算子并行编程实践
在昇腾 AI 处理器的算子开发体系中,Ascend C 构建了一套完整的设备端编程模型,让开发者能够以接近传统 C/C++ 的形式,直接操控多核 AI Core 的执行。无论是高性能数学库、深度学习算子,还是自定义算子,都依托于一个核心思想:SPMD(Single Program, Multiple Data)并行模型。
本文将以开发者视角,深入拆解 CANN 中 SPMD 的执行机制、核函数的结构与设计规范,并结合示例分析多核计算是如何实现数据划分、同步与调度的。文章的目标不是单纯介绍 API,而是帮助你理解“为什么是这样设计的”。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、为什么 Ascend C 选择 SPMD 模型?
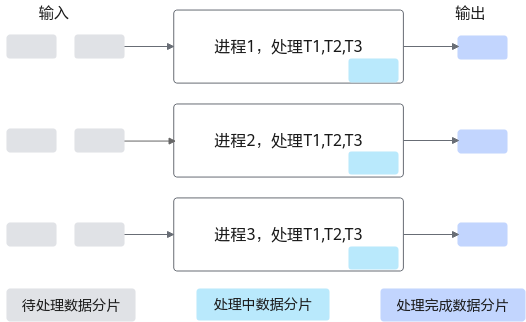
在 AI 算子计算中,性能通常由两个关键因素决定:
- 每个核心的计算能力
- 如何同时让更多 AI Core 参与计算
SPMD 模型很好地解决了第二点。
SPMD 最早用于高性能并行计算,它的核心思想很简单:
所有处理单元执行同一份代码,但处理不同的数据片段。
这意味着我们只需要编写一份算子实现,当算子被调用时,系统会自动启动多个核心实例,每个核心负责处理一部分数据。
在深度学习算子中,这种数据并行方式非常适用:
矩阵加法、卷积、激活函数、Softmax…
只要数据可以被切分,SPMD 就能让几十甚至上百个核心并行工作。
举个直观的例子:
如果一段输入数据需要经历 T1、T2、T3 三个阶段,那么在单核执行模式下就是一条线性 pipeline;而在 SPMD 下,几十个核心同时处理不同的数据片段,整个 pipeline 被完全并行化,吞吐大幅提升。
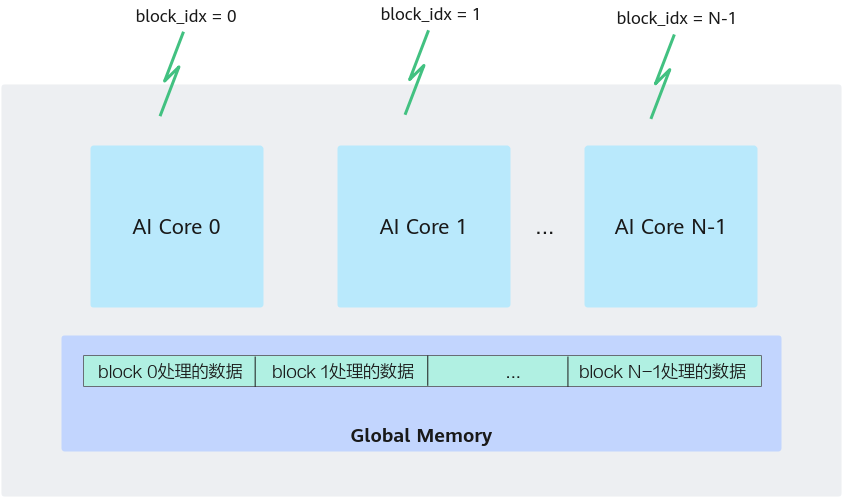
二、Ascend AI Core 中 SPMD 的具体落地方式
在 Ascend AI Core 中,“核心(Core)”就对应文档中提到的 SPMD 模型中的“进程”。区别在于:
- 每个核心共享同一份指令代码
- 每个核心通过 block_idx 区分身份
- block_idx 决定它应该处理哪段数据
从编程角度看,block_idx 就是“我是谁?”的答案。
Ascend C 提供了 GetBlockIdx() 接口来获取当前核心的逻辑 ID。
当算子启动 N 个核心(例:<<<N, ...>>>)时,系统会创建 N 个实例,每个实例在设备端运行同一份核函数代码,只是 block_idx 不同。
数据切片的本质:起始地址加偏移
在典型的算子(如 Add)中,不同核心通过偏移实现数据分片:
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
这行代码意味着:
- x 是整个输入数组
- BLOCK_LENGTH 是每个核心负责的数据长度
- GetBlockIdx() 决定当前核心负责第几个分片
数据切分不依赖框架,而是在算子内部进行,这也是 Ascend C 能非常灵活的原因。
三、核函数:Ascend C 算子的执行入口
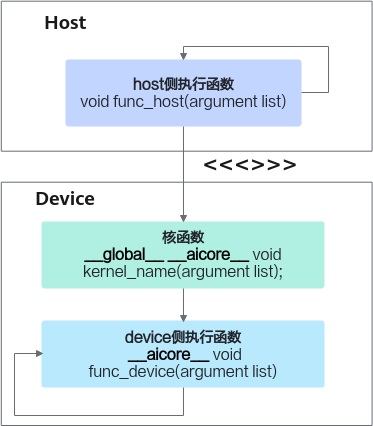
所有 Ascend C 设备端执行代码都以**核函数(Kernel Function)**为入口,类似于 CUDA 的 device kernel。
一个标准核函数需要满足以下条件:
1. 使用函数限定符
extern "C" __global__ __aicore__ void add_custom(...)
含义如下:
__global__: 表示该函数是核函数,可被主机用<<<>>>调用__aicore__: 该函数在设备的 AI Core 上执行extern "C": 禁止 C++ name mangling,方便符号查找
这三者构成了一个合法核函数的基本框架。
2. 入参与变量限定符
所有指向 Global Memory 的指针需要使用 __gm__ 或 GM_ADDR 修饰。
推荐使用 GM_ADDR:
#define GM_ADDR __gm__ uint8_t*
这样核函数声明更简洁:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
注意,“GM_ADDR 只是入口类型”,你仍然需要将其转换为实际的数据类型(如 half*)。
3. 必须是 void 返回值
核函数不允许返回值,一切输出都通过 Global Memory 传输。
四、核函数内部结构:对象式算子设计
Ascend C 通常推荐使用“算子类”封装计算与数据流逻辑,典型模式如下:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op; // 创建算子对象
op.Init(x, y, z); // 初始化,包括数据切片、queue 分配等
op.Process(); // 执行关键计算
}
这种写法有几个优势:
- 实现代码更模块化
- 可以为每个核心创建独立状态
- 算子逻辑更容易被工程化集成
例如,Init 中通常包含以下功能:
- 根据 block_idx 计算数据偏移
- 为每个核心分配 pipe、queue 缓冲区
- 初始化 Local Memory / Buffer
而 Process 则负责:
- Tile 分块循环
- GM → Local Memory 数据搬运
- Vector / Cube 计算指令
- Local Memory → GM 写回
五、如何在主机端调用核函数?
核函数采用扩展语法调用:
kernel<<<blockDim, l2ctrl, stream>>>(args...)
三个参数分别代表:
1. blockDim:启动多少个核心?
这是最重要的配置。它决定 SPMD 启动多少个实例。
不同处理器架构下规则不同,但经验上:
- Vector-only 算子设置为 AIV 核数
- Cube-only 算子设置为 AIC 核数
- Vector/Cube 混合算子根据“物理组合核数”配置
典型调用示例:
add_custom<<<8, nullptr, stream>>>(x, y, z);
表示:启动 8 个核心执行 add_custom。
2. l2ctrl(保留字段)
目前填 nullptr 即可。
3. stream:执行流
与 CUDA stream 类似,用于保证异步执行顺序。
调用结束后若需要等待,可调用:
aclrtSynchronizeStream(stream);
六、典型算子示例:并行 Add 的核心逻辑
下面是 Add 的简化示例,它展示了典型 SPMD 工作方式:
核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}
主机调用
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream,
uint8_t* x, uint8_t* y, uint8_t* z)
{
add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
只要 blockDim 设置20,那么就有20个 AI Core 并行执行,Auto load-balance 数据。
七、SPMD & 核函数的结合:为什么能做到高性能?
Ascend C 的高性能来自于以下几个因素:
1. 指令级一致性保证高效调度
所有核心执行同一份代码,硬件可做统一调度,不需要复杂的进程管理。
2. 数据切片完全在开发者掌控中
你可以根据算子特性灵活设计:
- 每个核心处理的数据量(BLOCK_LENGTH)
- 是否 tile 化
- 如何在 GM/UB 之间搬运
3. 多核 Pipeline 最大化吞吐
数据分片后,每个核心的计算完全独立,几乎没有同步开销。
4. 流式并行与指令流水结合
Pipe + queue 机制实现了:
- DMA 搬运与计算 overlap
- UB 分块交替执行
这进一步压榨了硬件性能。
结语:SPMD 是 Ascend 性能优化的基石
在昇腾算子开发中,SPMD 与核函数不是两个独立概念,而是一个整体:
- SPMD 负责“如何更快地并行处理数据”
- 核函数负责“如何在每个核心执行算子逻辑”
它们共同决定了一个 Ascend C 算子的性能天花板。
理解 block_idx 如何决定数据片段、Init 中如何分配 queue、Process 如何构建 tile pipeline,是迈向高性能算子开发的关键一步。
未来,当你需要编写更复杂的算子(如卷积、MatMul、LayerNorm)时,你会发现 SPMD 模型和核函数结构贯穿始终——从算子入口到最后一次写回,全靠这套机制支撑。


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)