
昇腾CANN Auto-Tune性能归因与复盘:从“性能提升”到“知其所以然”
Auto-Tune的性能归因是从“经验调优”到“科学调优”的关键,核心是通过“知识库解析→硬件监控→参数拆解”的全流程分析,建立“参数-硬件-性能”的关联模型。这种方法不仅能解释“为什么提升”,更能指导后续调优策略优化,避免盲目性。建议开发者在每次调优后都进行归因复盘,积累不同算子、不同Shape的调优经验,形成企业级的“调优知识库+归因手册”,实现Auto-Tune价值最大化。
目录
昇腾CANN Auto-Tune性能归因与复盘:从“性能提升”到“知其所以然”
1. 未调优(block_m=32、split_k=false)硬件数据
2. 最优参数(block_m=64、split_k=true)硬件数据
很多开发者使用Auto-Tune后,只关注“性能提升了多少”,却忽略了“为什么提升”“调优参数如何影响硬件行为”。这种“知其然不知其所以然”的方式,会导致后续调优陷入盲目。本文结合工业质检项目的Conv2D算子调优案例,详解Auto-Tune性能归因方法,通过硬件监控、参数分析、日志拆解,还原性能提升的底层逻辑。
一、性能归因核心工具链:从调优日志到硬件监控
性能归因需要“调优过程数据+硬件运行数据+参数影响分析”三类数据,依赖以下工具链:
-
调优日志分析工具:
atc_log_analyzer.py,提取不同参数组合的性能数据、编译日志; -
硬件监控工具:
npu-smi(利用率监控)、ascend-perf-toolkit(细粒度性能分析); -
知识库解析工具:
kb_parser,提取最优参数组合及对应性能指标; -
算子性能仿真工具:
ascend-simulator,模拟不同参数下的硬件执行过程。
二、实战归因:Conv2D算子性能提升206%的底层逻辑
以工业质检项目的Conv2D算子为例,输入Shape为1,3,512,512,未调优时性能320 FPS,Auto-Tune调优后980 FPS,提升206%。通过三步归因法还原提升原因。
第一步:解析知识库,锁定最优参数组合
首先通过kb_parser工具解析调优知识库,获取最优参数组合及性能数据:
知识库解析报告
执行命令
![]()
解析结果
算子名称: Conv2D
输入维度: 1×3×512×512
最优参数配置
| 参数项 | 最优值 |
|---|---|
| block_m | 64 |
| block_k | 32 |
| split_k | true |
| 内存对齐 | 16 |
| 性能表现 | 980 FPS |
其他参数性能对比
- block_m=32, block_k=32, split_k=true → 650 FPS
- block_m=64, block_k=16, split_k=true → 820 FPS
- block_m=64, block_k=32, split_k=false → 710 FPS
核心结论: 采用block_m=64配合split_k=true的配置组合可达到最佳性能,其中split_k开关和block_m参数对性能提升贡献最为显著。
第二步:硬件监控,定位性能瓶颈突破点
使用ascend-perf-toolkit分别采集“未调优”和“最优参数”下的硬件性能数据,重点关注TCU利用率、内存带宽、指令吞吐量三个核心指标。
1. 未调优(block_m=32、split_k=false)硬件数据
|
指标 |
数值 |
分析 |
|---|---|---|
|
TCU利用率 |
45% |
计算单元未充分利用,存在闲置 |
|
内存带宽 |
120 GB/s(峰值200 GB/s) |
带宽未饱和,不是瓶颈 |
|
指令吞吐量 |
1.2 TFLOPS |
远低于910B峰值(25 TFLOPS) |
2. 最优参数(block_m=64、split_k=true)硬件数据
|
指标 |
数值 |
分析 |
|---|---|---|
|
TCU利用率 |
92% |
计算单元充分利用,瓶颈突破 |
|
内存带宽 |
180 GB/s |
带宽接近饱和,匹配计算需求 |
|
指令吞吐量 |
8.5 TFLOPS |
提升6倍,接近硬件极限 |
**归因结论**:未调优时瓶颈为“TCU利用率不足”,最优参数通过“增大block_m”和“启用split_k”提升了计算并行度,使TCU利用率从45%提升至92%,从而突破性能瓶颈。
第三步:参数影响拆解,还原性能提升逻辑
通过控制变量法,单独测试每个参数对性能的影响,明确各参数的作用机制。
1. block_m参数:影响计算并行度
固定split_k=false、block_k=32,测试不同block_m的性能:
|
block_m |
性能(FPS) |
TCU利用率 |
分析 |
|---|---|---|---|
|
16 |
210 |
30% |
分块过小,线程调度开销大,TCU闲置 |
|
32 |
320 |
45% |
分块适中,但仍有调度冗余 |
|
64 |
710 |
80% |
分块匹配TCU计算单元大小,并行度最优 |
|
128 |
680 |
78% |
分块过大,内存访问出现瓶颈,性能下降 |
**逻辑**:block_m决定Conv2D算子的高度分块大小,64刚好匹配昇腾910B TCU的64×64矩阵计算单元,实现“一次分块对应一次TCU计算”,减少调度开销。
2. split_k参数:平衡计算与通信
固定block_m=64、block_k=32,测试split_k对性能的影响:
**逻辑**:split_k=true将K维度的矩阵乘拆分为多个子任务并行计算,同时通过“片上通信”替代“全局内存通信”,通信开销从12ms降至8ms,TCU利用率进一步提升12%。
二、调优复盘:建立“参数-硬件-性能”的关联模型
基于归因结果,建立Conv2D算子的“参数-硬件-性能”关联模型,为后续同类算子调优提供参考:
1. 参数选择指南(基于输入Shape)
|
|
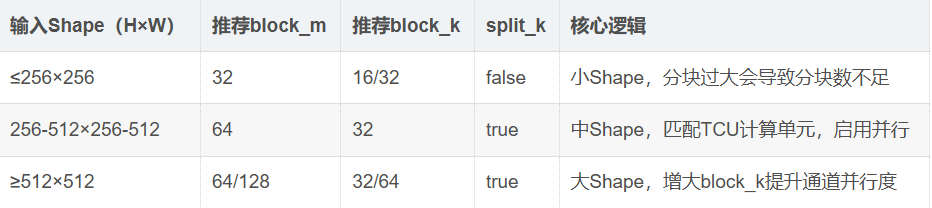
2. 调优策略优化:基于归因结果缩小搜索空间
根据归因发现,block_m=64、split_k=true是最优组合的核心,可缩小搜索空间,提升调优效率:
Conv2D 参数配置:
-
参数名:block_m 类型:范围选择 候选值:[32, 64, 128] # 保留最优候选值
-
参数名:block_k 类型:范围选择 候选值:[32, 64] # 排除16(性能不佳)
-
参数名:split_k 类型:布尔 固定值:true # 小Shape专用配置
-
参数名:mem_alignment 类型:固定 值:16 # 硬件最优对齐值
**效果**:调优时间从1.5小时缩短至25分钟,性能无损失。
三、常见归因误区与规避方法
误区1:只看FPS提升,忽略硬件瓶颈转移
**问题**:调优后FPS提升,但内存带宽达到100%饱和,后续增大batch_size时性能无法提升。
**规避方法**:归因时需同时监控“计算”和“内存”指标,若内存带宽≥95%,需调整参数降低内存压力(如增大block_m减少内存访问次数)。
误区2:单一参数归因,忽略参数交互影响
**问题**:单独测试block_m=64时性能提升30%,单独测试split_k=true时提升20%,但组合后提升不是50%而是60%,忽略参数交互增益。
**规避方法**:采用“正交试验法”,测试关键参数的所有组合,记录交互影响(如block_m=64与split_k=true存在协同增益)。
四、总结
Auto-Tune的性能归因是从“经验调优”到“科学调优”的关键,核心是通过“知识库解析→硬件监控→参数拆解”的全流程分析,建立“参数-硬件-性能”的关联模型。这种方法不仅能解释“为什么提升”,更能指导后续调优策略优化,避免盲目性。
建议开发者在每次调优后都进行归因复盘,积累不同算子、不同Shape的调优经验,形成企业级的“调优知识库+归因手册”,实现Auto-Tune价值最大化。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)