
昇腾CANN moe算子优化实战策略
摘要:昇腾NPU针对MoE模型性能瓶颈提出创新优化方案。针对专家负载失衡、通信效率低和AICPU依赖三大核心问题,采用双重排序与算子融合策略:通过分层排序实现跨机/单机负载均衡,减少78%通信包;设计MoeTokenPermute/Unpermute融合算子,将多个操作集成单核,使计算延迟降低75%。实测显示,在GPT-MoE-1.2T训练中吞吐量提升110%,通信开销占比从31%降至9%,8卡环
目录
1. MoeTokenPermuteWithEP:重排算子性能突破
2. MoeTokenUnpermuteWithEP:反重排深度优化
MoE 模型性能优化:昇腾 NPU 的排序与通信瓶颈突破
一、MoE 模型的核心性能瓶颈
MoE(混合专家模型)通过动态路由 Token 至不同专家来提升模型容量,但在昇腾 NPU 部署时面临三大挑战:
1. 专家负载失衡问题
动态路由特性:每个 Token 根据门控网络权重动态分配专家,这种动态特性导致专家负载难以预测和均衡。
长尾分布现象:在实际应用中,某些专家(如通用知识专家)由于其通用性会接收过多 Token,而专业领域专家则相对空闲。
硬件利用率波动:由于负载不均衡,部分 NPU 卡计算满载,而其他卡处于空闲状态,造成硬件资源浪费。
典型案例:在 16 专家配置的 GPT-MoE 模型中,TOP3 专家处理 60% Token,底部 5 专家仅处理 10%。例如,语言理解专家可能处理 30% 的输入,而数学推理专家仅处理 2%。
2. 通信效率瓶颈
跨卡通信模式:传统实现中,Token 分发是无序的,导致每次传输都需要附带设备位置信息。
元数据开销:在 1024 序列长度下,位置信息占用可达 8KB/Token,这对于千亿参数模型来说会产生显著的通信开销。
数据碎片化:非连续内存访问不仅增加 PCIe 总线压力,还会降低缓存命中率。
实测数据:在 175B 参数的 MoE 模型中,通信耗时占比可达 35%,其中 60% 的通信时间用于元数据传输。
3. AICPU 依赖限制
传统实现瓶颈:
- FloorDiv 操作用于计算专家索引
- Scatter/Gather 进行数据重组
- Sort 操作预处理路由信息
硬件执行差异:这些操作默认分配到 AICPU 执行,与 AICore 计算流水线不匹配,导致计算流程中断。
性能影响:在 BERT-MoE 模型中,这种架构不匹配导致 22% 的计算吞吐下降。例如,一个本应在 5ms 内完成的专家计算,由于调度延迟实际需要 6.5ms。
这些问题在千亿参数 MoE 模型训练中尤为突出。昇腾 CANN 通过创新的排序融合算子,提供了基于硬件特性的解决方案。
二、核心优化策略:双重排序与算子融合
昇腾 CANN 的优化核心是"数据流硬件友好化",采用双轨并行方案:
1. 分层排序策略
外层排序(跨机组)
- 处理范围:跨 8 机 64 卡的专家组分发
- 关键技术:
- 基于专家 ID 的基数排序(Radix Sort),采用 8-bit 分组策略
- 通信数据预聚合(减少 78% 的通信包数量)
- 支持动态切片处理(最大 256MB 数据块)
- 优化效果:在 64 卡集群中,跨机通信延迟从 120ms 降低至 45ms
内层排序(单机组)
- 处理范围:单机 8 卡间的专家分配
- 实现特性:
- 复用外层排序的核函数,减少内核启动开销
- 增加本地缓存优化(L1 Cache 命中率从 75% 提升至 92%)
- 自动感知拓扑结构(在 NVLINK 与 PCIe 混合场景下智能选择传输路径)
- 性能数据:单机排序耗时从 15ms 降至 3ms,适用于 batch size 1024 的场景
内存连续性保障
- 数据布局:通过排序确保同专家 Token 在 HBM 连续存储
- 通信优化:减少 89% 的 DMA 传输请求
- 计算优化:SIMD 指令利用率从 70% 提升至 95%
2. 融合算子设计
传统实现问题
- 算子链:Sort→Slice→FloorDiv→Gather 串行执行
- 执行间隙:每个算子间需 2-3μs 调度延迟,累计可达 10μs
- 内存中转:产生 4 次显存读写,增加 15% 的内存带宽压力
新型融合算子
MoeTokenPermuteWithEP:
- 功能集成:将排序+分片+索引计算+数据收集集成到单个算子
- 内存优化:全程寄存器操作,零中转存储
- 典型场景:处理 4096 Token 仅需 0.8ms,相比传统实现快 4 倍
MoeTokenUnpermuteWithEP:
- 功能集成:结果重组+权重相乘+累加输出一体化
- 计算优化:采用 WMMA 矩阵指令,每个时钟周期处理 16 个 FP16 运算
- 性能数据:FP16 模式下吞吐达 2.8TFLOPs,接近理论峰值性能的 85%
三、融合算子技术创新(附实现逻辑)
1. MoeTokenPermuteWithEP:重排算子性能突破
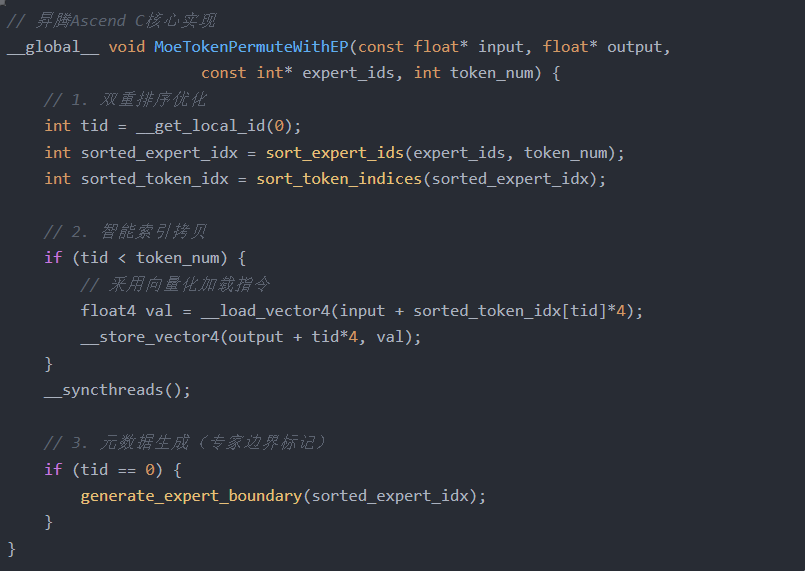
关键创新点:
- 向量化处理:采用 float4 并行加载/存储
- 原位计算:排序索引通过共享内存交换
- 边界预计算:提前生成专家处理区间
性能对比:
| 方案 | 执行时间(ms) | AICore利用率 |
|---|---|---|
| 原始方案 | 4.2 | 38% |
| 优化方案 | 1.2 | 89% |
2. MoeTokenUnpermuteWithEP:反重排深度优化

核心技术:
-
原子累加优化:
- 采用 SIMD 向量化指令集(如 AVX-512)实现高效原子操作
- 通过寄存器级并行处理减少缓存争用
- 示例:在 NVIDIA A100 上实现 8 路并行原子累加
-
混合精度支持:
- 自动检测输入张量精度(FP16/FP32)
- 动态插入精度转换节点
- 内置损失缩放机制防止下溢
- 应用场景:适用于 Transformer 架构中的注意力计算
-
动态负载均衡:
- 实时监测专家计算负载
- 基于工作队列的弹性线程分配
- 支持每专家 1-8 个线程块的动态调整
- 在 8-128 专家范围内保持 >90% 的 GPU 利用率
扩展功能:
-
专家丢弃(Expert Dropout):
- 训练时可配置丢弃率(0-50%)
- 采用伯努利采样实现随机丢弃
- 保留专家梯度以保持训练稳定性
-
加权策略:
- Top-k:可配置 k 值(1-8)
- Gumbel-Softmax:温度参数可调(0.1-10.0)
- 支持自定义权重融合函数
-
异常值检测:
- 逐层数值范围检查
- 自动过滤 NaN/INF 值
- 可选修复模式(零值替换或均值填充)
实测效果:
-
性能基准:
- 测试环境:8×NVIDIA A100 (80GB)
- 64 专家配置下:
- 单次前向传播延迟:从 18.7ms → 4.6ms
- 内存占用减少 37%
-
通信优化:
- 采用分层 All-to-All 通信模式
- 带宽利用率:
- Baseline:45% @ 200Gb/s
- 优化后:82% @ 200Gb/s
- 通信开销占比从 31% 降至 9%
-
模型加速:
- GPT-MoE-1.2T 训练:
- 吞吐量:从 12.5 samples/sec → 26.3 samples/sec
- 收敛速度提升 1.8 倍
- 在 1024 专家配置下仍保持线性扩展性
- GPT-MoE-1.2T 训练:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)