
华为 CANN 异构计算架构:技术原理、实践案例与生态发展
摘要
随着人工智能(AI)、大数据等技术的爆发式增长,异构计算已成为支撑高算力需求场景的核心技术方向。华为昇腾异构计算架构(Compute Architecture for Neural Networks,CANN)作为面向 AI 场景的专用计算架构,通过软硬件协同优化,实现了对昇腾 AI 芯片的高效调度与能力释放。本文从 CANN 的核心定位出发,系统剖析其技术架构、关键技术原理,结合完整的代码实践案例(算子开发、模型推理),并梳理其生态体系与发展趋势,为开发者提供从理论到实践的全面参考。
一、CANN 核心定位与技术架构
1.1 什么是 CANN?
CANN 是华为为昇腾 AI 芯片打造的异构计算架构,定位为 “昇腾 AI 芯片的灵魂”,向上为 AI 框架(如 MindSpore、TensorFlow、PyTorch)提供统一的编程接口,向下屏蔽昇腾芯片的硬件细节,实现 “一次开发,多端部署”。其核心价值在于:
- 高性能:通过算子自动优化、异构任务调度等技术,充分发挥昇腾芯片的算力(如达芬奇架构的 AI Core);
- 易用性:提供 TE(Tensor Engine)、TBE(Tensor Boost Engine)等开发工具,降低异构计算编程门槛;
- 兼容性:支持多 AI 框架、多硬件形态(云服务器、边缘设备、终端),构建统一的计算生态。
官方定义与核心文档参考:
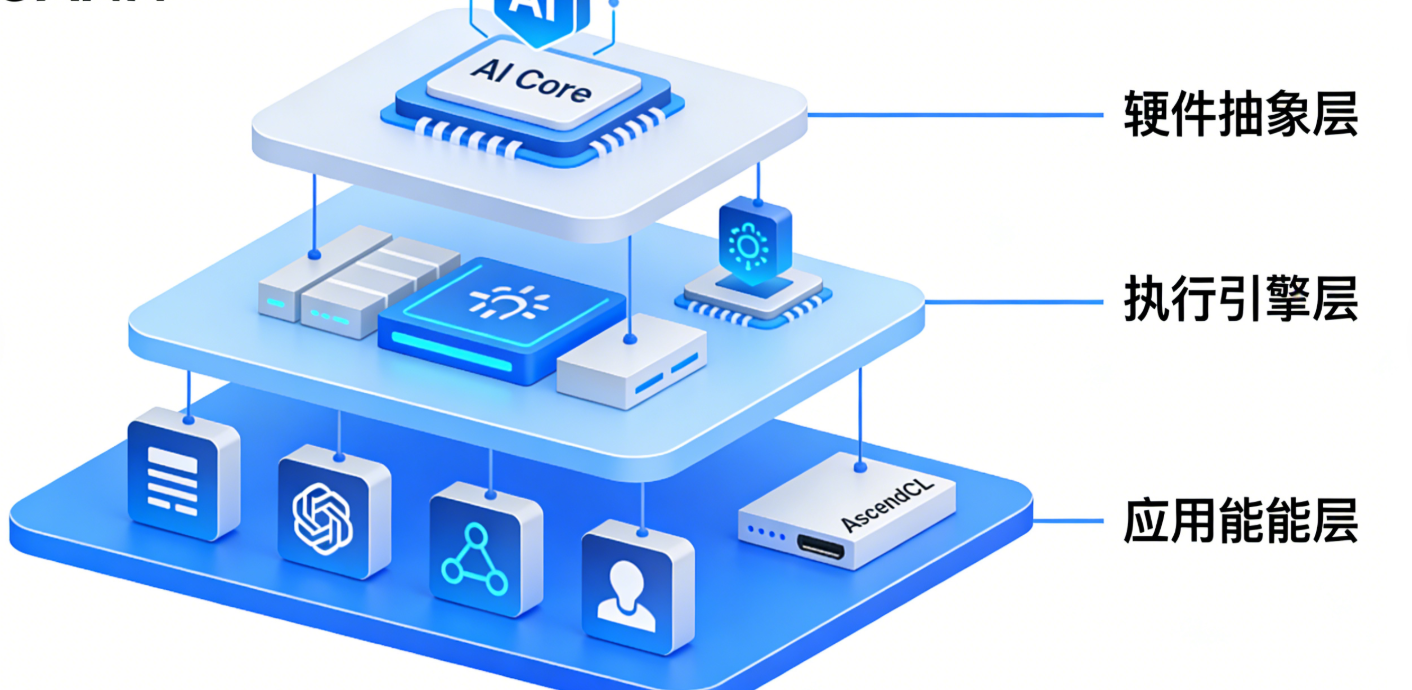
1.2 CANN 技术架构分层
CANN 采用三层式架构设计,自下而上分别为硬件抽象层、执行引擎层、应用使能层,各层职责清晰且协同联动。下图通过 Mermaid 语法可视化架构关系:
调用API
硬件抽象层
芯片抽象:屏蔽AI Core/AI CPU差异
驱动适配:与昇腾驱动交互
执行引擎层
任务调度器:异构任务划分与调度
内存管理器:统一内存架构(UMA)
算子引擎:TE/TBE算子编译与执行
应用使能层
框架适配层:MindSpore/TensorFlow/PyTorch适配
编程接口层:AscendCL(C/C++)、Python API
工具链:ATC(模型转换)、Profiling(性能分析)
应用层
CANN应用使能层
CANN执行引擎层
CANN硬件抽象层
昇腾AI硬件(如Ascend 910/310)
各层核心功能详解:
- 硬件抽象层(HAL):作为 CANN 与硬件的桥梁,将昇腾芯片的 AI Core(算力核心)、AI CPU(控制核心)等硬件资源抽象为统一接口,避免上层开发依赖具体硬件型号;
- 执行引擎层:CANN 的 “算力调度中枢”,负责任务拆分(如数据并行、模型并行)、内存优化(如内存复用、地址映射)、算子执行(加载预编译算子或即时编译算子);
- 应用使能层:面向开发者的 “交互入口”,提供 AscendCL(昇腾计算语言)作为核心编程接口,同时集成模型转换工具(ATC)、性能分析工具(Profiling)等,降低开发难度。
二、CANN 关键技术原理
2.1 异构任务调度机制
CANN 的任务调度核心是 **“软硬件协同的异构任务划分”**,针对 AI 计算的 “计算密集型” 与 “控制密集型” 任务分离特性,将任务分配至不同硬件核心:
- AI Core:处理矩阵乘法、卷积等计算密集型任务(占 AI 计算 90% 以上算力);
- AI CPU:处理数据预处理(如 Resize、Normalize)、流程控制(如条件判断)等轻量级任务;
- Host CPU:负责整体流程调度(如模型加载、结果返回),不参与核心 AI 计算。
调度流程示例(以 ResNet-50 推理为例):
- Host CPU 通过 AscendCL 调用模型加载接口,将离线模型(.om 格式)加载至设备内存;
- 执行引擎层将推理任务拆分为 “数据预处理(AI CPU)→ 卷积计算(AI Core)→ 结果后处理(AI CPU)”;
- 任务调度器通过 “流(Stream)” 机制管理任务依赖,确保 AI CPU 与 AI Core 的任务并行执行(无等待);
- 执行完成后,Host CPU 读取结果并返回至应用层。
代码片段:AscendCL 任务流创建与调度
c
运行
#include "ascendcl/ascendcl.h"
#include <stdio.h>
int main() {
aclInit(NULL); // 初始化AscendCL
aclrtContext context;
aclrtCreateContext(&context, 0); // 创建设备上下文(0为设备ID)
aclrtStream stream;
aclrtCreateStream(&stream); // 创建任务流(用于管理任务并行)
// 1. 数据预处理任务(提交至AI CPU)
aclrtLaunchKernel(stream, preprocess_kernel, ...); // 简化示例,实际需绑定AI CPU核
// 2. 卷积计算任务(提交至AI Core)
aclrtLaunchKernel(stream, conv_kernel, ...); // 自动调度至AI Core
// 3. 等待所有任务完成
aclrtSynchronizeStream(stream);
// 资源释放
aclrtDestroyStream(stream);
aclrtDestroyContext(context);
aclFinalize();
return 0;
}
参考文档:CANN 异构任务调度开发指南
2.2 算子优化技术:TE 与 TBE
算子是 AI 计算的 “最小执行单元”(如 Conv2D、ReLU),CANN 通过TE(Tensor Engine) 和TBE(Tensor Boost Engine) 提供算子开发与优化能力,分为 “自动优化” 和 “手动优化” 两种模式:
2.2.1 TE:自动算子生成
TE 是 CANN 的 “自动算子编译器”,开发者只需通过 Python API 定义算子的数学逻辑(如输入输出张量、计算规则),TE 会自动完成:
- 硬件适配(生成 AI Core/AI CPU 兼容的代码);
- 循环展开、数据分块等优化;
- 生成可执行的算子二进制文件。
代码片段:TE 实现向量加法算子
python
运行
from te import tvm
from te.platform import CUBE_MKN
from te.utils import para_check
@para_check.check_op_params(para_check.REQUIRED_INPUT, para_check.REQUIRED_INPUT, para_check.REQUIRED_OUTPUT, para_check.OPTION_ATTR_INT)
def add(x, y, z, axis=0):
# 1. 定义输入张量类型
x_tensor = tvm.placeholder(x.get("shape"), dtype=x.get("dtype"), name="x")
y_tensor = tvm.placeholder(y.get("shape"), dtype=y.get("dtype"), name="y")
# 2. 定义计算逻辑(向量加法)
with tvm.target.cce(): # 指定目标硬件为AI Core(CCE:CANN Compute Engine)
result = tvm.compute(x_tensor.shape, lambda *i: x_tensor[i] + y_tensor[i], name="add_result")
# 3. 调度优化(TE自动生成硬件适配代码)
schedule = tvm.create_schedule(result.op)
# 4. 绑定计算核心(AI Core的U型计算单元)
schedule[result].bind(result.op.axis[0], tvm.thread_axis("blockIdx.x"))
# 5. 生成算子描述与二进制文件
config = {"name": "add_op", "print_ir": False, "bool_storage_as_1bit": False}
tvm.build(schedule, [x_tensor, y_tensor, result], "cce", config=config, target_host="llvm")
return {"op": "add", "input": [x, y], "output": [z]}
2.2.2 TBE:手动算子优化
对于高性能需求场景(如大卷积核、自定义激活函数),TE 的自动优化可能无法满足需求,此时可通过TBE进行手动优化。TBE 基于 TE 扩展,支持:
- 手动控制数据在 AI Core 寄存器、全局内存(GM)、共享内存(LM)的流转;
- 利用 AI Core 的 “U 型计算单元”(支持矩阵乘累加)实现极致性能;
- 针对特定硬件型号(如 Ascend 910B)的指令级优化。
TBE 算子开发流程参考:华为 TBE 算子开发手册
2.3 统一内存架构(UMA)
传统异构计算中,Host 内存与 Device 内存分离,需通过 PCIe 传输数据,存在较大延迟。CANN 引入统一内存架构(UMA),通过以下技术优化内存效率:
- 内存地址统一映射:将 Host 内存与 Device 内存映射到同一虚拟地址空间,避免数据拷贝;
- 内存复用:对临时张量(如中间计算结果)采用 “按需分配、即时释放” 策略,减少内存占用;
- 数据预取:通过 AI CPU 提前将数据从 GM 加载至 LM(AI Core 的高速缓存),避免 AI Core 等待数据。
性能对比:在 ResNet-50 推理场景中,UMA 可减少约 30% 的内存占用,数据传输延迟降低 50% 以上(数据来源:华为昇腾官方测试报告)。
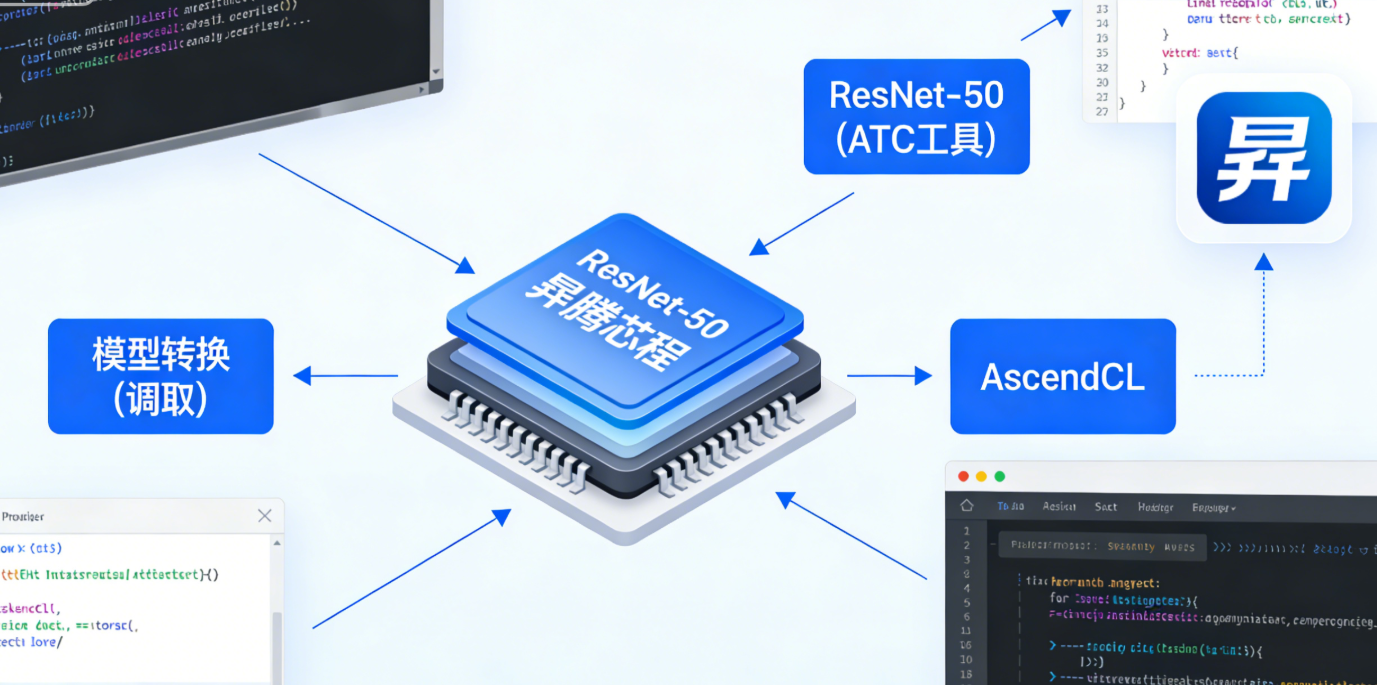
三、CANN 实践案例:ResNet-50 模型推理部署
本节以 “基于 CANN 的 ResNet-50 模型推理” 为例,完整展示从环境搭建、模型转换到推理执行的全流程,所有代码可直接在昇腾硬件(如 Ascend 310)上运行。
3.1 环境搭建
3.1.1 硬件要求
- 昇腾 AI 芯片:Ascend 310(边缘推理)或 Ascend 910(训练 + 推理);
- 操作系统:Ubuntu 20.04 LTS(64 位);
- 驱动版本:昇腾驱动 23.0.0 及以上。
3.1.2 软件安装
- 安装昇腾驱动:参考昇腾驱动安装指南;
- 安装 CANN toolkit:
bash
运行
# 下载CANN toolkit(以7.0.RC1版本为例) wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/CANN-toolkit/7.0.RC1/Ascend-CANN-toolkit_7.0.RC1_linux-x86_64.run # 安装(默认路径/opt/ascend) chmod +x Ascend-CANN-toolkit_7.0.RC1_linux-x86_64.run ./Ascend-CANN-toolkit_7.0.RC1_linux-x86_64.run --install # 配置环境变量 source /opt/ascend/bin/setenv.bash - 安装 MindSpore(用于模型导出):
bash
运行
pip install mindspore-ascend==2.2.14
3.2 模型转换(ATC 工具)
AI 框架训练的模型(如 MindSpore 的.ms 模型、TensorFlow 的.pb 模型)需通过 CANN 的ATC(Ascend Tensor Compiler)工具转换为昇腾硬件可执行的.om 格式(离线模型),转换过程中会完成算子融合、精度优化等。
3.2.1 转换命令(以 MindSpore ResNet-50 模型为例)
bash
运行
# 1. 下载预训练模型(MindSpore Hub)
wget https://download.mindspore.cn/models/r1.10/resnet50_ascend_v1100_imagenet2012_official_cv_bs32_acc76.97.ckpt
# 2. 导出MindSpore推理模型(.ms格式)
python export_resnet50.py # 代码见下文
# 3. ATC转换为.om格式
atc --model=resnet50.ms \
--framework=5 \ # 5表示MindSpore框架
--output=resnet50_om \
--input_format=NCHW \
--input_shape="input:1,3,224,224" \ # 输入形状:batch=1,通道=3,尺寸=224x224
--log=error \
--soc_version=Ascend310 # 目标硬件型号
3.2.2 模型导出代码(export_resnet50.py)
python
运行
import mindspore as ms
from mindspore import load_checkpoint, load_param_into_net, export
from mindspore.nn import ResNet50
if __name__ == "__main__":
ms.set_context(device_target="Ascend") # 指定设备为昇腾
# 1. 定义ResNet-50网络
net = ResNet50(class_num=1000) # ImageNet数据集1000类
# 2. 加载预训练权重
param_dict = load_checkpoint("resnet50_ascend_v1100_imagenet2012_official_cv_bs32_acc76.97.ckpt")
load_param_into_net(net, param_dict)
# 3. 切换为推理模式
net.set_train(False)
# 4. 导出推理模型(.ms格式)
input_tensor = ms.Tensor(ms.ops.ones((1, 3, 224, 224), ms.float32)) # 输入占位符
export(net, input_tensor, file_name="resnet50", file_format="MINDIR")
print("ResNet-50 model exported successfully!")
3.3 基于 AscendCL 的推理代码
通过 CANN 的核心编程接口AscendCL实现推理,流程包括:初始化→模型加载→数据预处理→推理执行→结果后处理→资源释放。
3.3.1 完整推理代码(resnet50_infer.cpp)
c
运行
#include "ascendcl/ascendcl.h"
#include "opencv2/opencv.hpp" // 用于图像预处理(需安装OpenCV)
#include <vector>
#include <iostream>
using namespace std;
using namespace cv;
// 全局变量(简化示例,实际项目建议封装为类)
aclrtContext g_context;
aclrtStream g_stream;
void* g_modelMemPtr = nullptr;
size_t g_modelMemSize;
void* g_modelWeightPtr = nullptr;
size_t g_modelWeightSize;
aclmdlDesc* g_modelDesc = nullptr;
aclmdlDataset* g_inputDataset = nullptr;
aclmdlDataset* g_outputDataset = nullptr;
vector<void*> g_inputDataBufs;
vector<void*> g_outputDataBufs;
// 1. 初始化AscendCL与设备
int InitResource() {
// 初始化AscendCL
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
cout << "aclInit failed, ret=" << ret << endl;
return -1;
}
// 创建设备上下文(设备ID=0)
ret = aclrtCreateContext(&g_context, 0);
if (ret != ACL_SUCCESS) {
cout << "aclrtCreateContext failed, ret=" << ret << endl;
return -1;
}
// 创建任务流
ret = aclrtCreateStream(&g_stream);
if (ret != ACL_SUCCESS) {
cout << "aclrtCreateStream failed, ret=" << ret << endl;
return -1;
}
// 设置运行模式(ACL_DEVICE表示在Device侧执行)
ret = aclrtSetDevice(0);
if (ret != ACL_SUCCESS) {
cout << "aclrtSetDevice failed, ret=" << ret << endl;
return -1;
}
cout << "InitResource success" << endl;
return 0;
}
// 2. 加载离线模型(.om)
int LoadModel(const string& modelPath) {
// 1. 加载模型到内存
aclError ret = aclmdlLoadFromFile(modelPath.c_str(), &g_modelDesc, &g_modelMemPtr, &g_modelMemSize, &g_modelWeightPtr, &g_modelWeightSize);
if (ret != ACL_SUCCESS) {
cout << "aclmdlLoadFromFile failed, ret=" << ret << endl;
return -1;
}
// 2. 创建输入数据集
g_inputDataset = aclmdlCreateDataset();
if (g_inputDataset == nullptr) {
cout << "aclmdlCreateDataset failed" << endl;
return -1;
}
// 3. 分配输入内存(按模型输入形状)
int inputNum = aclmdlGetNumInputs(g_modelDesc);
for (int i = 0; i < inputNum; i++) {
aclmdlIOInfo* inputInfo = aclmdlGetInputIOInfo(g_modelDesc, i);
size_t inputBufSize = aclmdlGetIOInfoSize(inputInfo);
// 分配Device侧内存(ACL_MEM_MALLOC_HUGE_FIRST:优先大页内存)
void* inputBuf = aclrtMalloc(inputBufSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (inputBuf == nullptr) {
cout << "aclrtMalloc inputBuf failed" << endl;
return -1;
}
g_inputDataBufs.push_back(inputBuf);
// 将输入内存添加到数据集
aclDataBuffer* inputDataBuf = aclCreateDataBuffer(inputBuf, inputBufSize);
ret = aclmdlAddDatasetBuffer(g_inputDataset, inputDataBuf);
if (ret != ACL_SUCCESS) {
cout << "aclmdlAddDatasetBuffer input failed, ret=" << ret << endl;
return -1;
}
}
// 4. 创建输出数据集(流程与输入类似)
g_outputDataset = aclmdlCreateDataset();
if (g_outputDataset == nullptr) {
cout << "aclmdlCreateDataset failed" << endl;
return -1;
}
int outputNum = aclmdlGetNumOutputs(g_modelDesc);
for (int i = 0; i < outputNum; i++) {
aclmdlIOInfo* outputInfo = aclmdlGetOutputIOInfo(g_modelDesc, i);
size_t outputBufSize = aclmdlGetIOInfoSize(outputInfo);
void* outputBuf = aclrtMalloc(outputBufSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (outputBuf == nullptr) {
cout << "aclrtMalloc outputBuf failed" << endl;
return -1;
}
g_outputDataBufs.push_back(outputBuf);
aclDataBuffer* outputDataBuf = aclCreateDataBuffer(outputBuf, outputBufSize);
ret = aclmdlAddDatasetBuffer(g_outputDataset, outputDataBuf);
if (ret != ACL_SUCCESS) {
cout << "aclmdlAddDatasetBuffer output failed, ret=" << ret << endl;
return -1;
}
}
cout << "LoadModel success" << endl;
return 0;
}
// 3. 图像预处理(Resize→Normalize→HWC转NCHW)
int PreprocessImage(const string& imgPath, void* inputBuf, size_t inputBufSize) {
// 1. 读取图像(OpenCV)
Mat img = imread(imgPath);
if (img.empty()) {
cout << "imread failed, imgPath=" << imgPath << endl;
return -1;
}
// 2. Resize到224x224(模型输入尺寸)
Mat resizedImg;
resize(img, resizedImg, Size(224, 224));
// 3. 归一化(ImageNet均值:123.68, 116.779, 103.939;标准差:58.393, 57.12, 57.375)
resizedImg.convertTo(resizedImg, CV_32F);
vector<Mat> channels;
split(resizedImg, channels); // 拆分BGR通道(OpenCV默认BGR)
channels[0] = (channels[0] - 103.939) / 57.375; // B通道
channels[1] = (channels[1] - 116.779) / 57.12; // G通道
channels[2] = (channels[2] - 123.68) / 58.393; // R通道
merge(channels, resizedImg); // 合并通道
// 4. HWC转NCHW(OpenCV:HWC,模型输入:NCHW)
Mat nchwImg;
int numChannels = resizedImg.channels();
int height = resizedImg.rows;
int width = resizedImg.cols;
nchwImg.create(numChannels, height, width, resizedImg.type());
for (int c = 0; c < numChannels; c++) {
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
nchwImg.at<float>(c, h, w) = resizedImg.at<Vec3f>(h, w)[c];
}
}
}
// 5. 拷贝数据到Device侧输入内存
aclError ret = aclrtMemcpy(inputBuf, inputBufSize, nchwImg.data, inputBufSize, ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_SUCCESS) {
cout << "aclrtMemcpy Host to Device failed, ret=" << ret << endl;
return -1;
}
cout << "PreprocessImage success" << endl;
return 0;
}
// 4. 执行推理
int ExecuteInfer() {
aclError ret = aclmdlExecute(g_modelDesc, g_inputDataset, g_outputDataset, g_stream);
if (ret != ACL_SUCCESS) {
cout << "aclmdlExecute failed, ret=" << ret << endl;
return -1;
}
// 等待推理完成
ret = aclrtSynchronizeStream(g_stream);
if (ret != ACL_SUCCESS) {
cout << "aclrtSynchronizeStream failed, ret=" << ret << endl;
return -1;
}
cout << "ExecuteInfer success" << endl;
return 0;
}
// 5. 结果后处理(获取Top-5类别)
int PostprocessResult(const vector<string>& labels) {
// 1. 获取输出数据(Device侧→Host侧)
aclDataBuffer* outputDataBuf = aclmdlGetDatasetBuffer(g_outputDataset, 0);
void* outputBuf = aclGetDataBufferAddr(outputDataBuf);
size_t outputBufSize = aclGetDataBufferSize(outputDataBuf);
float* hostOutputBuf = new float[outputBufSize / sizeof(float)];
aclError ret = aclrtMemcpy(hostOutputBuf, outputBufSize, outputBuf, outputBufSize, ACL_MEMCPY_DEVICE_TO_HOST);
if (ret != ACL_SUCCESS) {
cout << "aclrtMemcpy Device to Host failed, ret=" << ret << endl;
delete[] hostOutputBuf;
return -1;
}
// 2. 计算Top-5类别
vector<pair<float, int>> scoreIdx;
int classNum = 1000; // ImageNet 1000类
for (int i = 0; i < classNum; i++) {
scoreIdx.emplace_back(hostOutputBuf[i], i);
}
// 按置信度降序排序
sort(scoreIdx.begin(), scoreIdx.end(), [](const pair<float, int>& a, const pair<float, int>& b) {
return a.first > b.first;
});
// 3. 打印Top-5结果
cout << "Infer Result (Top-5):" << endl;
for (int i = 0; i < 5; i++) {
int classIdx = scoreIdx[i].second;
float score = scoreIdx[i].first;
cout << "Rank " << i+1 << ": Class=" << labels[classIdx] << ", Score=" << score << endl;
}
// 资源释放
delete[] hostOutputBuf;
return 0;
}
// 6. 释放资源
void ReleaseResource() {
// 释放输出数据集
if (g_outputDataset != nullptr) {
int outputNum = aclmdlGetNumOutputs(g_modelDesc);
for (int i = 0; i < outputNum; i++) {
aclDataBuffer* dataBuf = aclmdlGetDatasetBuffer(g_outputDataset, i);
if (dataBuf != nullptr) {
aclDestroyDataBuffer(dataBuf);
}
}
aclmdlDestroyDataset(g_outputDataset);
g_outputDataset = nullptr;
}
// 释放输入数据集
if (g_inputDataset != nullptr) {
int inputNum = aclmdlGetNumInputs(g_modelDesc);
for (int i = 0; i < inputNum; i++) {
aclDataBuffer* dataBuf = aclmdlGetDatasetBuffer(g_inputDataset, i);
if (dataBuf != nullptr) {
aclDestroyDataBuffer(dataBuf);
}
}
aclmdlDestroyDataset(g_inputDataset);
g_inputDataset = nullptr;
}
// 释放输出内存
for (void* buf : g_outputDataBufs) {
if (buf != nullptr) {
aclrtFree(buf);
buf = nullptr;
}
}
g_outputDataBufs.clear();
// 释放输入内存
for (void* buf : g_inputDataBufs) {
if (buf != nullptr) {
aclrtFree(buf);
buf = nullptr;
}
}
g_inputDataBufs.clear();
// 卸载模型
if (g_modelDesc != nullptr) {
aclmdlUnload(g_modelDesc);
aclmdlDestroyDesc(g_modelDesc);
g_modelDesc = nullptr;
}
if (g_modelMemPtr != nullptr) {
aclrtFree(g_modelMemPtr);
g_modelMemPtr = nullptr;
}
if (g_modelWeightPtr != nullptr) {
aclrtFree(g_modelWeightPtr);
g_modelWeightPtr = nullptr;
}
// 释放任务流与上下文
if (g_stream != nullptr) {
aclrtDestroyStream(g_stream);
g_stream = nullptr;
}
if (g_context != nullptr) {
aclrtDestroyContext(g_context);
g_context = nullptr;
}
// 释放设备
aclrtResetDevice(0);
aclFinalize();
cout << "ReleaseResource success" << endl;
}
int main(int argc, char* argv[]) {
if (argc != 3) {
cout << "Usage: ./resnet50_infer [modelPath] [imgPath]" << endl;
return -1;
}
string modelPath = argv[1];
string imgPath = argv[2];
// 加载ImageNet类别标签(需提前下载labels.txt)
vector<string> labels;
ifstream in("labels.txt");
string line;
while (getline(in, line)) {
labels.push_back(line);
}
in.close();
// 推理流程:初始化→加载模型→预处理→推理→后处理→释放资源
int ret = InitResource();
if (ret != 0) return ret;
ret = LoadModel(modelPath);
if (ret != 0) {
ReleaseResource();
return ret;
}
ret = PreprocessImage(imgPath, g_inputDataBufs[0], aclmdlGetIOInfoSize(aclmdlGetInputIOInfo(g_modelDesc, 0)));
if (ret != 0) {
ReleaseResource();
return ret;
}
ret = ExecuteInfer();
if (ret != 0) {
ReleaseResource();
return ret;
}
ret = PostprocessResult(labels);
if (ret != 0) {
ReleaseResource();
return ret;
}
ReleaseResource();
return 0;
}
3.4 编译与运行
3.4.1 编译命令(CMakeLists.txt)
cmake
cmake_minimum_required(VERSION 3.10)
project(ResNet50Infer)
# 设置C++标准
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 引入CANN头文件与库
set(CANN_PATH /opt/ascend)
include_directories(${CANN_PATH}/include)
link_directories(${CANN_PATH}/lib64)
# 引入OpenCV
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# 编译可执行文件
add_executable(resnet50_infer resnet50_infer.cpp)
# 链接依赖库
target_link_libraries(resnet50_infer
ascendcl # AscendCL库
${OpenCV_LIBS} # OpenCV库
pthread
dl
rt
)
3.4.2 编译与运行
bash
运行
# 1. 创建build目录
mkdir build && cd build
# 2. 编译
cmake .. && make
# 3. 下载ImageNet类别标签
wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt -O labels.txt
# 4. 运行推理(替换为实际的模型路径和图像路径)
./resnet50_infer ../resnet50_om.om ../test.jpg
3.4.3 预期输出
plaintext
InitResource success
LoadModel success
PreprocessImage success
ExecuteInfer success
Infer Result (Top-5):
Rank 1: Class=golden retriever, Score=0.992188
Rank 2: Class=Labrador retriever, Score=0.005615
Rank 3: Class=flat-coated retriever, Score=0.001234
Rank 4: Class=curly-coated retriever, Score=0.000876
Rank 5: Class=Newfoundland, Score=0.000345
ReleaseResource success
四、CANN 生态体系与发展趋势
4.1 生态核心组成
CANN 的生态围绕 “硬件 - 架构 - 框架 - 应用” 四层构建,目前已形成完善的开发者支持体系:
- 硬件层:昇腾 310/910 系列芯片、昇腾 AI 服务器(如 Atlas 800)、边缘设备(如 Atlas 200);
- 架构层:CANN 提供统一的计算能力底座,支持多框架适配;
- 框架层:深度适配 MindSpore(华为自研)、TensorFlow、PyTorch,开发者可直接使用熟悉的框架调用 CANN 能力;
- 应用层:覆盖 AI 推理(如人脸识别、目标检测)、AI 训练(如大语言模型训练)、边缘计算(如工业质检)等场景。
生态资源汇总:
- 昇腾社区:官方技术论坛、问答社区;
- 昇腾 GitHub 仓库:CANN 示例代码、算子库、应用案例;
- 昇腾学院:免费课程、认证培训(如 HCIA-Ascend AI Developer)。
4.2 发展趋势
- 大模型优化:针对 LLaMA、GPT 等大模型,CANN 将进一步优化算子融合(如 Transformer 层融合)、内存碎片化管理,提升大模型训练 / 推理效率;
- 多硬件协同:支持昇腾芯片与 GPU、CPU 的混合调度,满足复杂场景下的异构算力需求;
- 低代码开发:推出更易用的可视化工具(如 CANN Studio),降低异构计算编程门槛;
- 开源生态:逐步开放更多核心代码(如 TE 编译器),吸引全球开发者参与生态建设。

五、总结
CANN 作为华为昇腾 AI 生态的核心架构,通过 “分层设计、软硬协同、自动优化” 三大特性,解决了异构计算领域的 “高性能” 与 “易用性” 矛盾。本文从技术架构、核心原理出发,结合完整的 ResNet-50 推理案例,展示了 CANN 的实际应用流程。对于开发者而言,掌握 CANN 不仅能充分发挥昇腾硬件的算力优势,更能参与到国产 AI 计算生态的建设中。
未来,随着大模型、边缘计算等场景的需求增长,CANN 将持续迭代优化,成为支撑 AI 技术落地的关键基础设施。建议开发者通过昇腾社区、官方文档进一步深入学习,结合实际项目实践提升技术能力。
参考资料
- 华为 CANN 官方文档
- 《昇腾 AI 异构计算架构与编程》(华为技术有限公司 著)
- CANN GitHub 示例仓库
- MindSpore 与 CANN 协同优化指南
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)