
昇腾CANN逻辑架构与算子开发全流程解析
引言
昇腾CANN作为连接硬件与AI应用的核心技术栈,其“分层解耦+全栈协同”的架构设计,既实现了硬件算力的高效调用,也为开发者提供了灵活的开发接口。本文从架构底层拆解入手,结合实战代码,详细解析CANN的核心能力与算子开发全流程。
一、昇腾CANN三层逻辑架构深度拆解
CANN架构分为应用层、芯片使能层、计算资源层,每层通过标准化接口协同,形成从硬件到应用的完整技术链路。
1. 应用层:开发与工具中枢
应用层是开发者直接交互的入口,核心功能是“降低开发门槛、提升开发效率”,包含三类核心能力:
- 多框架兼容:无缝对接MindSpore、TensorFlow、Caffe等主流AI框架,支持现有模型的快速迁移,无需更换工具链即可接入CANN生态;
- 全流程工具链:
- Blas加速库:优化矩阵运算、向量计算等基础数学操作,单次运算效率提升20%~30%;
- 模型小型化工具:提供量化、剪枝、压缩功能,可将模型体积压缩30%以上,精度损失控制在1%以内,适配终端/边缘资源受限场景;
- AutoML工具:支持模型结构搜索与超参数自动调优,减少人工调参成本;
- MindStudio集成环境:集代码编写、调试、编译、性能分析于一体,内置算子模板、语法检查、性能可视化功能,实现一站式开发;
- 系统管理:提供设备监控、日志收集、配置管理能力,支持实时查看芯片算力占用、任务执行状态,辅助问题定位与系统优化。
2. 芯片使能层:CANN核心能力引擎
芯片使能层是CANN的核心,负责将硬件算力转化为上层可调用的标准化能力,包含五大模块:
- AscendCL(昇腾计算语言库):
开发者调用芯片能力的统一入口,提供Device(设备)、Context(上下文)、Stream(流)等资源管理API,以及数据传输、任务提交接口。无论底层是终端、边缘还是云芯片,均通过统一接口调用算力,屏蔽硬件差异;
- 图优化与编译模块:
- Graph Engine(GE):将AI框架的计算图解析、拆分、重构为芯片可执行的子图,支持动态图转静态图、节点重排序,使计算流程贴合硬件特性;
- Fusion Engine(FE):管理算子融合规则,将“Conv+BN+Relu”“MatMul+Add”等高频组合算子合并为复合算子,减少数据搬运,推理性能提升20%~50%;
- AICPU引擎:处理控制流密集、计算量小的CPU算子(如数据预处理),与AI Core形成算力互补;
- HCCL引擎:实现多芯片/服务器间的高效通信,支持AllReduce、Broadcast等集合通信操作,满足分布式训练需求;
- 算子编译与算子库:
- TBE(Tensor Boost Engine):算子开发工具,提供Ascend C语言、编译链、调试工具,支持自定义算子开发,工具链自动完成硬件适配优化,开发效率提升3倍;
- 内置算子库:覆盖卷积、池化、激活等90%以上常用AI任务,算子针对昇腾芯片NPU架构优化,可直接调用获得最优性能;
- 运行管理(Runtime):
负责任务队列管理、资源分配、优先级调度,确保多任务并发时的稳定性与高效性;
- 数字视觉预处理(DVPP):
独立硬件加速模块,支持JPEG编解码、视频帧裁剪/缩放、格式转换,处理速度比CPU快5~10倍,支撑视觉类AI应用。
3. 计算资源层:硬件算力载体
计算资源层是CANN的物理基础,提供纯粹的算力支撑:
- 计算设备:
- AI Core:昇腾芯片核心算力单元,执行神经网络类算子(如卷积、矩阵乘法),支持张量/向量并行计算;
- AICPU:执行控制流密集的CPU算子,如数据预处理、后处理;
- DVPP硬件:承接视频/图像预处理任务,解放AI Core算力;
- 通信链路:
采用PCIe 4.0、RoCE技术,实现芯片与CPU、芯片间、服务器间的低时延、高吞吐数据传输,支撑多卡协同、分布式部署。
二、算子开发全流程:基于Ascend C的实战解析
算子开发是CANN的核心能力之一,以下以LogsoftmaxV2算子为例,详细解析“计算逻辑编写-初始化配置-算子注册-编译部署”的全流程。
1. 算子计算逻辑编写
LogsoftmaxV2算子用于分类模型输出层,核心公式为 Logsoftmax(x) = (x - max(x)) - ln(sum(exp(x - max(x)))) ,需处理数值溢出问题:

2. 算子初始化配置
初始化函数用于设置输出张量的形状、数据类型,确保输入输出的兼容性:

3. 算子注册
将自定义算子注册到CANN算子库,使上层框架可调用:

4. 编译与部署
通过TBE工具链完成算子编译与部署,步骤如下:
1. 编写算子代码:将上述代码保存为 LogsoftmaxV2.cpp ;
2. 编译算子:使用TBE编译器生成适配昇腾芯片的算子文件:
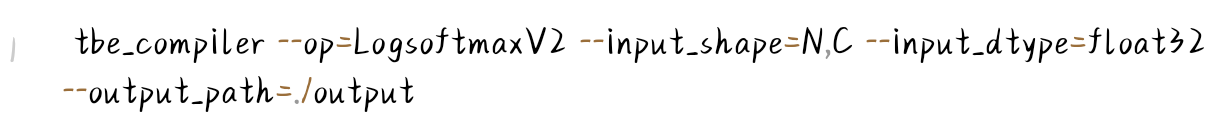
3. 注册算子:将编译后的 .so 文件复制到CANN算子库目录,完成注册;
4. 验证算子:在昇腾设备上通过AscendCL或MindSpore调用算子,验证计算结果与性能:

三、图优化与性能调优实践
通过图优化与算子融合,可进一步提升模型性能,以下以ResNet50为例解析优化流程:
1. 计算图解析与拆分
Graph Engine将ResNet50的计算图拆分为多个子图,识别出“Conv+BN+Relu”等高频算子组合;
2. 算子融合
Fusion Engine将“Conv+BN+Relu”合并为一个复合算子,减少数据在内存与寄存器间的搬运次数,推理时延降低40%;
3. 内存优化
通过中间结果缓存复用,减少内存申请/释放开销,内存带宽利用率提升25%;
4. 性能分析
使用MindStudio的性能分析工具,定位瓶颈(如内存带宽瓶颈),针对性优化算子执行顺序与并行策略。
四、总结
昇腾CANN的三层架构实现了硬件与应用的高效协同,而算子开发是发挥硬件算力的核心环节。通过Ascend C语言与TBE工具链,开发者可快速实现自定义算子的开发与优化,结合图优化与性能调优,能够将模型性能提升30%以上,为AI应用的规模化落地提供技术支撑。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)