
基于cann-recipes-infer的Kimi-K2-Thinking仓库技术解读:大模型推理优化的昇腾案例分析
随着大语言模型(LLM)和多模态模型规模的不断扩大,高效推理部署成为AI落地的关键挑战。华为昇腾计算平台凭借其强大的AI计算能力,为大模型推理提供了重要支撑。cann-recipes-infer仓库作为昇腾CANN平台上大模型推理优化的实战范例集,为开发者提供了可直接复用的代码样例和优化方案,架起了模型与硬件之间的桥梁。
基于cann-recipes-infer的Kimi-K2-Thinking仓库技术解读:大模型推理优化的昇腾案例分析
一、引言
随着大语言模型(LLM)和多模态模型规模的不断扩大,高效推理部署成为AI落地的关键挑战。华为昇腾计算平台凭借其强大的AI计算能力,为大模型推理提供了重要支撑。cann-recipes-infer仓库作为昇腾CANN平台上大模型推理优化的实战范例集,为开发者提供了可直接复用的代码样例和优化方案,架起了模型与硬件之间的桥梁。
与cann-recipes-train仓库专注于训练优化不同,cann-recipes-infer仓库聚焦于推理阶段的性能优化和工程实践,通过一系列精心设计的优化技术,实现了在昇腾Atlas系列硬件上的高效推理部署。本文将深入剖析该仓库的架构设计、关键优化技术和实际应用价值。

二、仓库定位与架构设计
2.1 仓库定位
cann-recipes-infer仓库定位为大模型与多模态模型推理业务的"实战底座",提供基于CANN平台的推理优化样例集。它的核心价值在于:
- 连接模型与硬件:将复杂的模型适配、优化和部署流程标准化,降低开发者使用昇腾平台的门槛
- 性能优化实践:集成了多种针对昇腾硬件特性的优化技术,提供开箱即用的高性能推理方案
- 全栈技术支持:覆盖从模型加载、权重转换到推理执行的完整流程,支持多种并行策略和优化方法
2.2 整体架构
仓库采用模块化设计,各组件职责明确、耦合度低。主要由以下几个核心部分组成:
- models目录:包含各类模型的适配实现和部署脚本,每个模型有独立的子目录
- executor目录:负责模型加载、初始化和推理执行的核心逻辑
- module目录:包含模型的核心组件实现,如量化、算子融合等
- ops目录:提供底层优化算子,包括AscendC、PyPTO等多种实现方式
- accelerator目录:提供加速相关的工具和组件
- dataset目录:存放测试数据集和处理脚本
- docs目录:包含详细的文档和优化指南
这种分层架构使得仓库既可以作为完整的推理解决方案使用,也支持开发者根据需要灵活定制和扩展各个组件。

三、支持的主要模型与优化技术
3.1 模型支持概览
cann-recipes-infer仓库支持多种主流大模型和多模态模型,截至2025年11月,主要包括:
- Kimi-K2-Thinking:支持256K超长序列推理,实现W4A16量化优化
- DeepSeek-R1/K2:支持多个版本,包含多种量化方案
- DeepSeek-V3.2-Exp:实现CP并行与NPU融合Kernel优化
- Qwen3-MoE:支持235B-A22B和30B-A3B两个版本,适配Mixture-of-Experts架构
- Wan2.2-I2V:图像到视频生成模型,实现NPU融合算子优化
- HunyuanVideo:多模态视频生成模型

3.2 典型模型适配案例

Qwen3-MoE模型适配
Qwen3-MoE作为2025年开源的大语言模型,采用了混合专家(Mixture-of-Experts)架构,在NPU上的适配面临独特挑战。仓库通过以下方式实现高效推理:
- 基于transformers库的modeling_qwen3_moe.py完成适配优化
- 支持Atlas A3系列产品,采用CANN 8.3.RC1.alpha002和torch_npu 7.2.RC1.alpha002
- 针对MoE架构特点,实现了专家路由和计算优化,提高计算效率
- 支持长序列prompt,可使用LongBench数据集进行长文本处理
DeepSeek-V3.2-Exp模型优化
DeepSeek-V3.2-Exp作为最新的高性能模型,在昇腾平台上的优化重点包括:
- 支持FP8权重转换为Bfloat16、W8A8C16和W8A8C8等多种精度格式
- 采用CP并行策略和NPU融合Kernel技术,充分利用昇腾硬件特性
- 支持长序列输入,如InfiniteBench数据集的长文本处理
- 提供完整的Docker镜像,简化环境配置
Kimi-K2-Thinking长序列优化
针对Kimi-K2-Thinking模型的256K超长序列推理需求,仓库实现了专门的优化:
- 基于CANN 8.5和PyTorch 2.6.0构建优化环境
- 支持Prefill阶段8-192卡并行,Decode阶段8-192卡并行
- 实现W4A16量化,在保持精度的同时大幅提升性能
- 针对超长序列特点优化内存管理和计算调度
四、GitCode实践cann-recipes-infer仓库
1、NoteBook 资源配置
计算资源:NPU:1*NPU 910B 32vCPU + 64GB 内存
容器镜像:ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook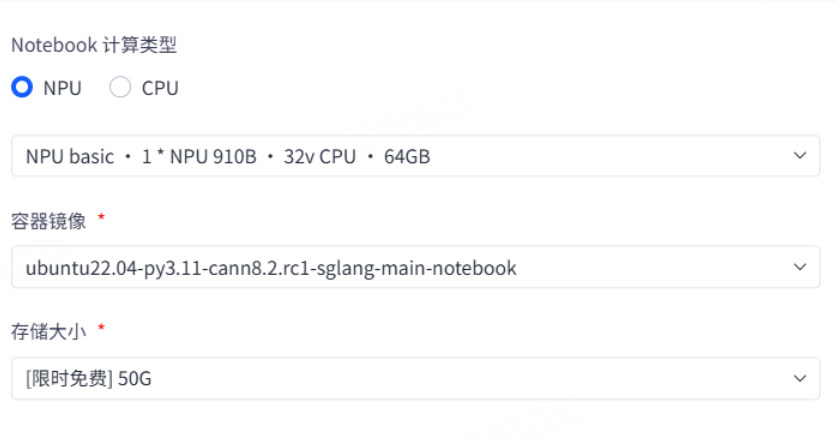
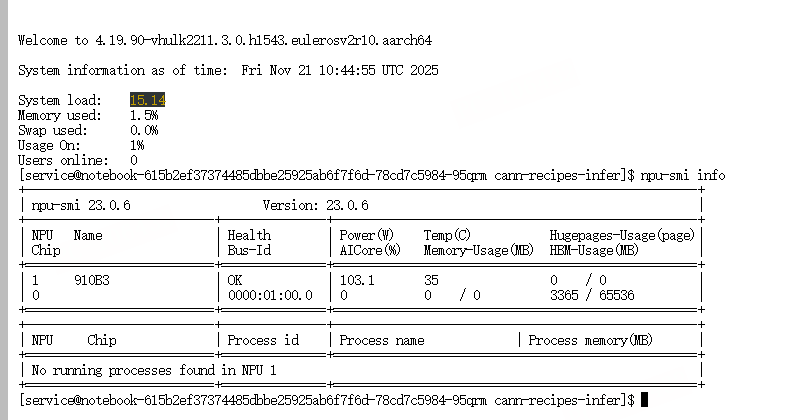
NoteBook 启动成功后使用 npu-smi 查看 NPU 状态、利用率
npu-smi info
cann-recipes-infer 克隆到本地
git clone https://gitcode.com/cann/cann-recipes-infer.git

4.1 Kimi-K2-Thinking实践样例
Atlas A3推荐部署策略如下图所示,Prefill使用M个节点部署,Decode使用N个节点部署,每个节点包含8卡,推荐根据资源数量、SLA等约束,M和N在1~24内动态调整。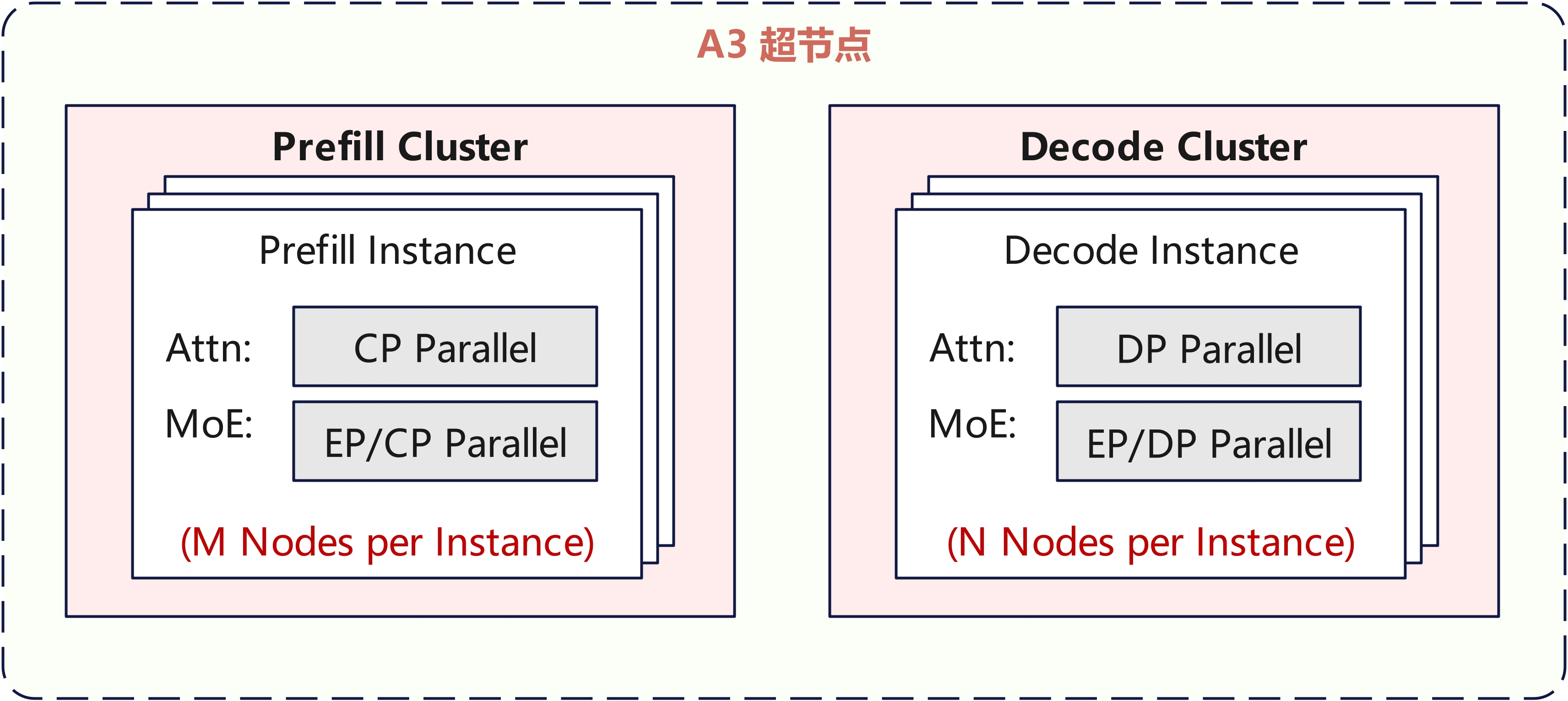
下载源码
在各个节点上执行如下命令下载 cann-recipes-infer 源码。
mkdir -p /home/code; cd /home/code/
git clone https://gitcode.com/cann/cann-recipes-infer.git
cd cann-recipes-infer
# 创建目标目录
mkdir -p dataset/InfiniteBench
# 进入目录
cd dataset/InfiniteBench
# 使用 wget 下载数据集
wget https://huggingface.co/datasets/xinrongzhang2022/InfiniteBench/resolve/main/longbook_qa_eng.jsonl
下载速度比较慢,可以使用本地电脑下载后才上传到服务器中。
下载权重
下载Kimi-K2-Thinking原始权重,并上传到Atlas A3各节点某个固定的路径下/data/models/Kimi-K2-Thinking。 文件结构参考
文件结构参考

将源码与权重路径挂载到容器内,使用如下脚本启动容器(默认容器名 cann_recipes_infer):
docker run -u root -itd --name cann_recipes_infer --ulimit nproc=65535:65535 --ipc=host \
--device=/dev/davinci0 --device=/dev/davinci1 \
--device=/dev/davinci2 --device=/dev/davinci3 \
--device=/dev/davinci4 --device=/dev/davinci5 \
--device=/dev/davinci6 --device=/dev/davinci7 \
--device=/dev/davinci8 --device=/dev/davinci9 \
--device=/dev/davinci10 --device=/dev/davinci11 \
--device=/dev/davinci12 --device=/dev/davinci13 \
--device=/dev/davinci14 --device=/dev/davinci15 \
--device=/dev/davinci_manager --device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /home/:/home \
-v /data:/data \
-v /etc/localtime:/etc/localtime \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info -v /var/log/npu/:/usr/slog \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /sys/fs/cgroup:/sys/fs/cgroup:ro \
-v /usr/local/dcmi:/usr/local/dcmi -v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf -v /root/.pip:/root/.pip -v /etc/hosts:/etc/hosts \
-v /usr/bin/hostname:/usr/bin/hostname \
--net=host \
--shm-size=128g \
--privileged \
cann8.5_pt2.6.0_kimi_k2_aarch_image:v0.1 /bin/bash
在各个节点上通过如下脚本拉起容器,默认容器名为 cann_recipes_infer。注意:需要将权重路径和源码路径挂载到容器里。
配置修改,设置集群 IP
修改 set_env.sh:
export IPs=('node1_IP' 'node2_IP' ...)
第一个 IP 必须为 Master 节点,多节点以空格分隔
配置模型路径
编辑 config/ 目录下即将执行的 YAML 文件:
model_path: "/data/models/Kimi-K2-Thinking"
指定推理 YAML 文件
在 infer.sh 中设置:
# prefill 阶段(支持 8-192 卡)
export YAML_FILE_NAME=kimi_k2_thinking_rank_64_64ep_prefill_benchmark.yaml
# decode 阶段(支持 8-192 卡)
export YAML_FILE_NAME=kimi_k2_thinking_rank_128_128ep_decode_benchmark.yaml
world_size 可在对应 YAML 文件中修改以适配不同卡数。
启动多卡推理任务
在所有节点上执行:
bash infer.sh
即可启动多节点多卡推理任务。
4.2Kimi-K2-Thinking推理优化实践
Prefill并行策略
考虑到长序列场景,Prefill Attention选用Context Parallel(CP)并行,多个rank均摊长序列的计算,单rank的计算量和activation内存都较小,TTFT较为可控,用户体验更好。MoE模块则沿用DeepSeek-V3.1的EP并行,兼顾吞吐与时延。
Decode并行策略
Decode阶段依旧沿用DeepSeek V3.1的部署策略,选用Attention DP + MoE EP部署。
特别地,由于O_proj和LM_Head权重内存较大,且在Decode阶段表现为明显的访存瓶颈,本实践选用局部TP并行。同时为了降低设备内存占用,Embedding层同样使用TP切分。为了尽可能地减小TP并行带来的通信开销,TP域控制在单机内。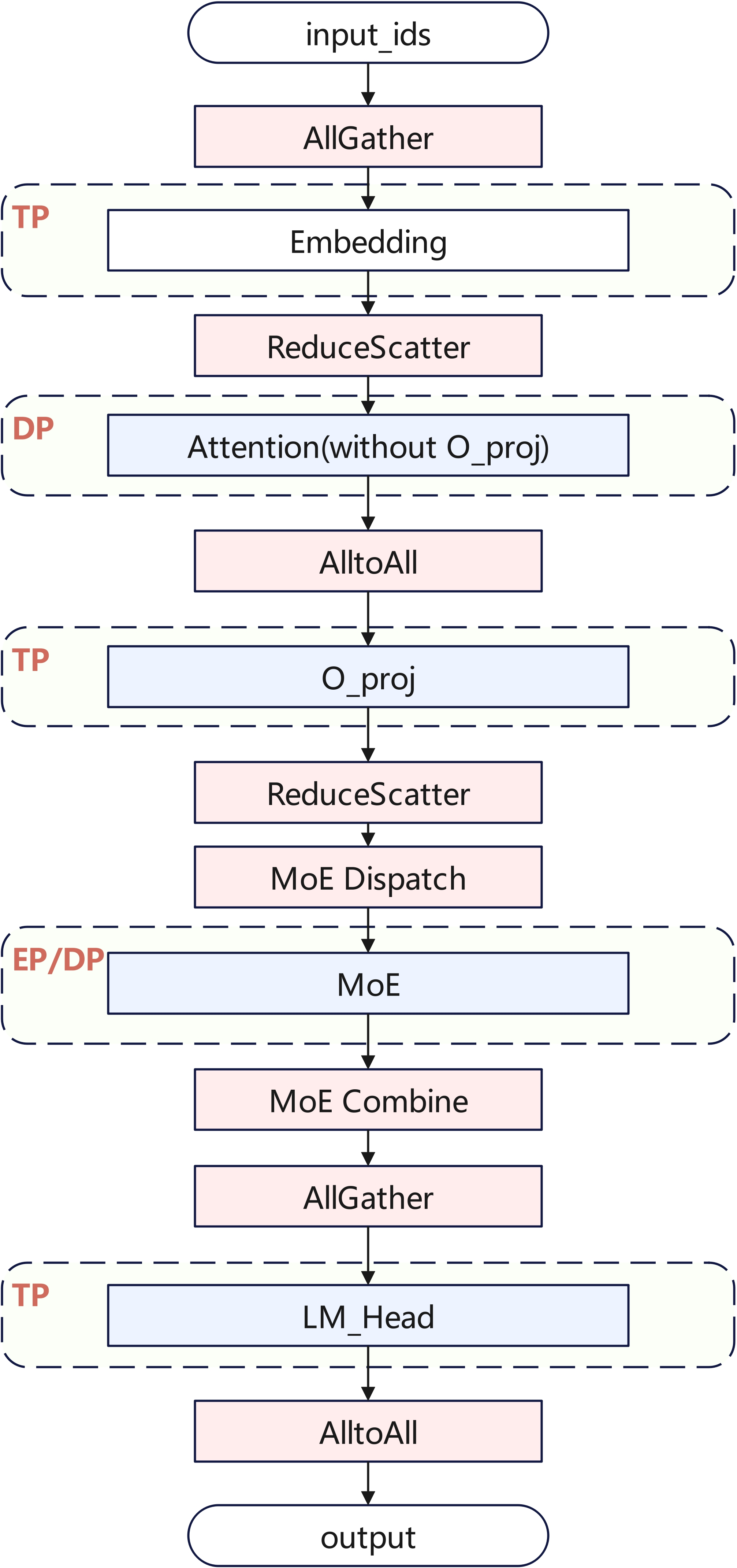
融合Kernel
整网计算流如下图所示,本实践使用了MLAProlog、FusedInferAttentionScore、MoeDistributeDispatch、MoeDistributeCombine、GroupedMatmul等融合Kernel,可供其他同类模型在昇腾平台的高效落地提供实践参考。
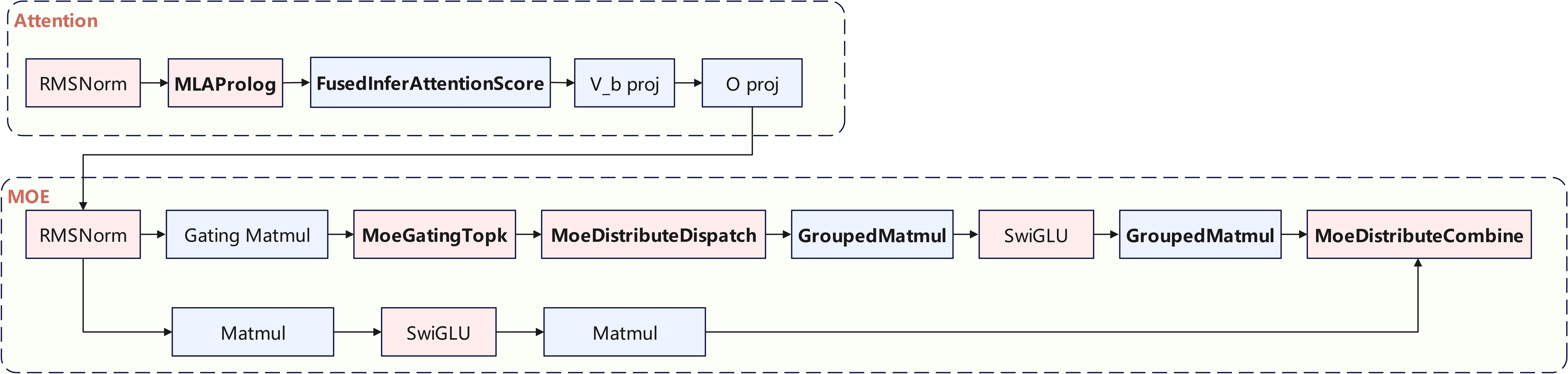
相较于DeepSeek V3.1,Kimi-K2-Thinking的Attention Head数量从128精简至64,使得Attention计算量显著降低,更利好MTP场景。LLM推理Decode阶段通常为访存瓶颈,MTP可通过少量计算代价来缓解访存压力,而 Kimi-K2-Thinking的Attention本身计算负载更轻,因此在 MTP模式下更难触及计算瓶颈,性能更优。
本实践对应的代码已支持多头 MTP 功能,若具备训练完成的MTP权重,可直接启用该功能以实现推理加速。
Kimi-K2-Thinking 训练优化点解读
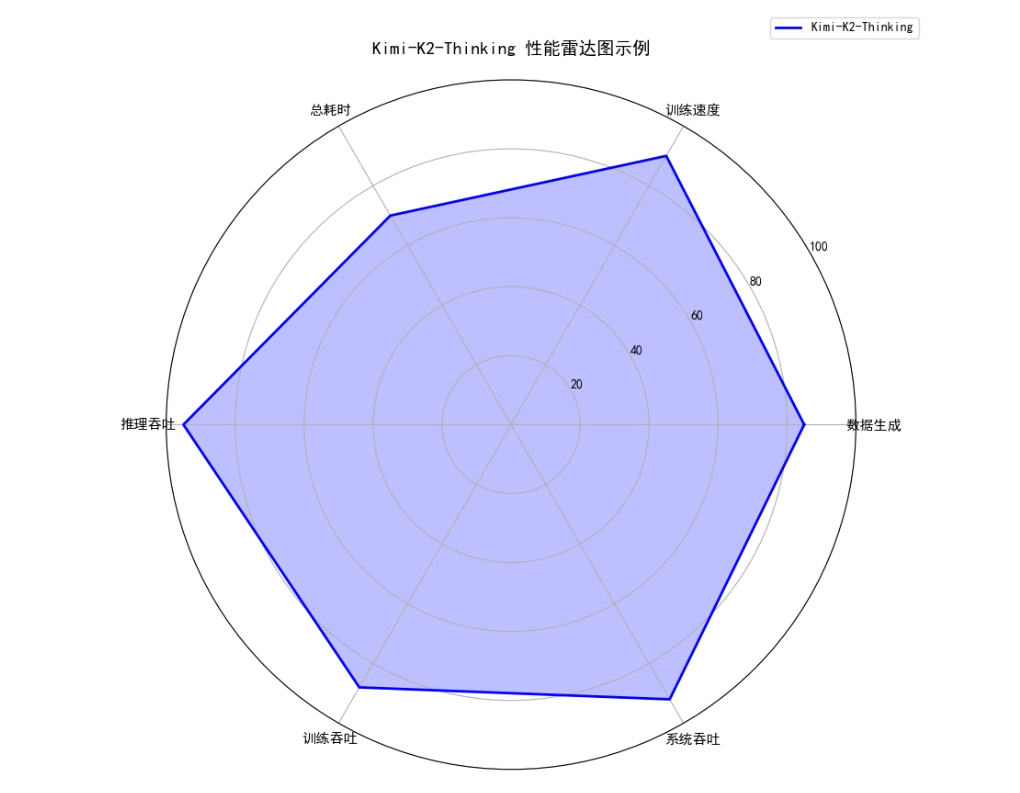
如图是基于Kimi-K2-Thinking,加载真实权重和随机初始化权重的两个场景中性能效果
通过数据生成管线、多卡并行策略和通信优化,Kimi-K2-Thinking在长序列训练和推理中表现出高效且均衡的性能。雷达图显示,模型在数据生成、训练速度、推理吞吐和系统吞吐等关键指标上得分较高,总耗时相对可控,训练吞吐也保持在较高水平,体现了多卡分布式训练、Context Parallel与MoE
并行策略协同优化的效果,为在Atlas A3等昇腾平台上大规模部署提供了可靠参考。
Kimi-K2-Thinking在A3集群上的推理优化实践展示了针对长序列、MOE W4A16量化和混合精度模式的多维优化能力。通过Prefill阶段的Context Parallel并行、Decode阶段的Attention DP + MoE EP策略,以及局部TP和Embedding切分,本实践在保证推理精度的同时,显著提升了吞吐与系统利用率。融合Kernel(如MLAProlog、FusedInferAttentionScore、GroupedMatmul等)的应用进一步降低了计算开销和访存瓶颈,MTP模式针对Decode阶段访存压力进行了有效缓解。
整体来看,本实践为Kimi-K2-Thinking在单机及多机多卡环境下的高效落地提供了可复用的优化方案,并为未来量化、长序列性能及Kernel优化提供了明确方向,具备很强的工程参考价值和可扩展性。
五、总结
cann-recipes-infer仓库为昇腾平台上的大模型和多模态模型推理提供了完整的优化实践和可复用方案。通过模块化架构、并行策略优化、融合Kernel和量化技术的综合应用,仓库有效解决了大模型在长序列、高吞吐和多卡部署场景下的性能瓶颈。
以Kimi-K2-Thinking为例,本实践展示了从Prefill阶段的Context Parallel并行、Decode阶段的Attention DP + MoE EP策略,到局部TP切分和MTP模式的全链路优化,兼顾了推理精度、吞吐和系统利用率。融合Kernel如MLAProlog、FusedInferAttentionScore、GroupedMatmul的应用进一步提升了计算效率,降低了访存压力,为长序列推理提供了高效解决方案。
总体而言,cann-recipes-infer不仅为昇腾平台大模型推理提供了成熟的工程参考,也为未来在量化、长序列优化及Kernel级改进方向提供了明确的实践路径,具有很高的推广价值和可扩展性。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)