
昇腾 A1 入门课(PyTorch)全解析与实战精讲
definitinit()return xprint("\nMyReLU输出Tensor:\n", output_tensor)
昇腾 A1 入门课(PyTorch)全解析与实战精讲
一、课程核心定位与目标
CANN 训练营 2023 年第一季昇腾 A1 入门课(PyTorch 方向)是华为昇腾生态面向 AI 开发者推出的零基础入门实战课程,聚焦昇腾 A1 系列处理器与 CANN 软件栈的 PyTorch 生态适配能力,旨在帮助开发者快速掌握 “PyTorch 模型→昇腾 NPU 部署” 的全流程技术栈。
1.1 核心目标
理解昇腾 A1 处理器硬件架构与 CANN 软件栈的 PyTorch 适配原理;
掌握昇腾 NPU 开发环境搭建与基础设备管理方法;
实现 PyTorch 模型向昇腾 NPU 的快速迁移、训练与推理;
学会基础性能分析与算子调用技巧,解决常见部署问题。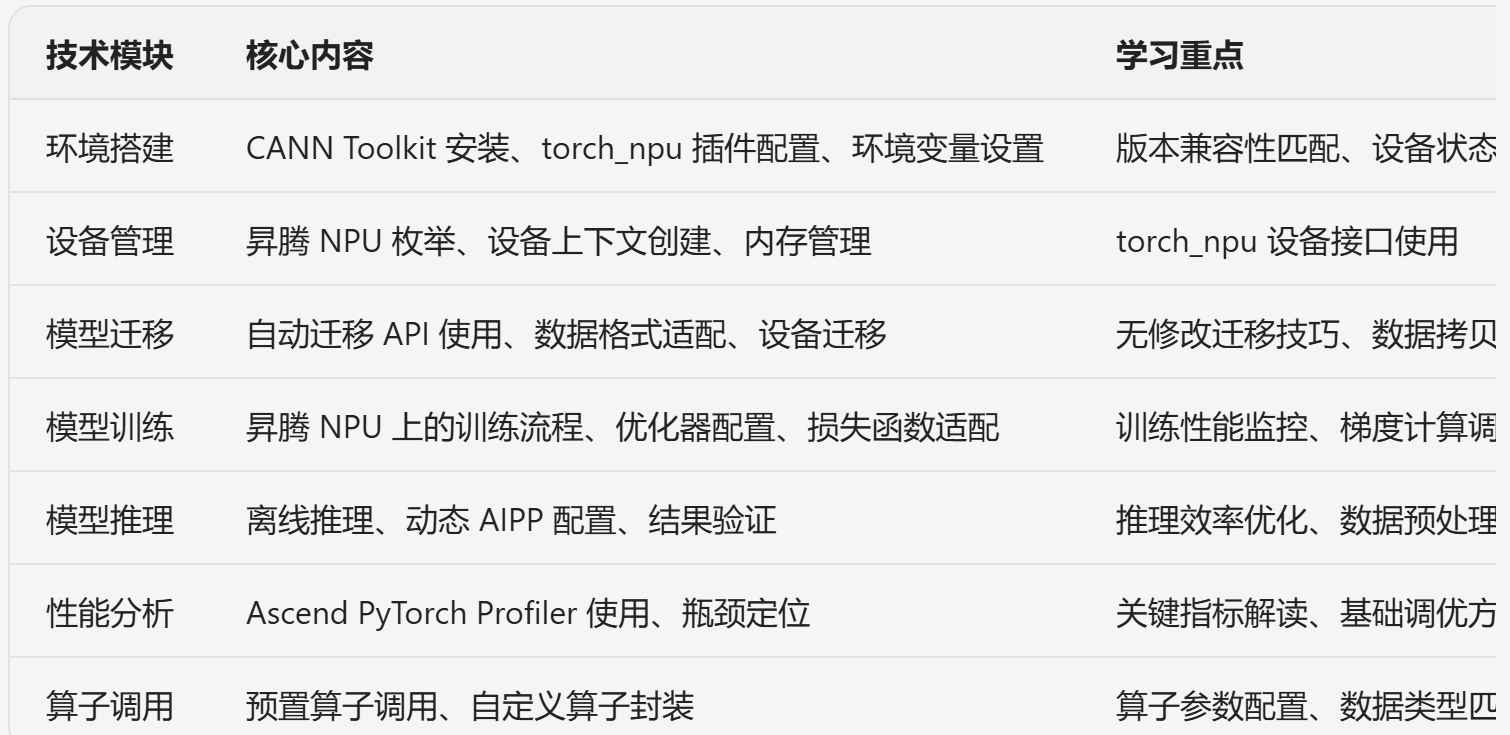
1.2 适用人群
具备 PyTorch 基础开发经验的 AI 工程师;
希望将深度学习模型迁移至昇腾硬件的算法开发者;
入门昇腾生态的技术爱好者与学生。
二、课程核心知识体系
2.1 昇腾 A1 处理器基础
昇腾 A1 系列处理器(如 Ascend A100)是面向端边云场景的高性价比 AI 处理器,基于达芬奇架构,内置 AI Core 计算单元,支持 INT4/INT8/FP16/FP32 多精度计算,专为 PyTorch 等框架的深度学习任务优化,单卡算力可达数十 TOPS,兼顾性能与功耗平衡。
2.2 CANN 软件栈的 PyTorch 适配逻辑
CANN 软件栈通过torch_npu 插件实现 PyTorch 与昇腾 NPU 的无缝对接,核心适配层架构如下:
上层:PyTorch 原生 API(完全兼容,无需修改核心代码);
中间层:torch_npu 插件(核心适配层,实现 CUDA API→NPU API 的自动转换);
下层:CANN 基础层(ACL 接口、算子库、Runtime 等,提供底层算力支撑)。
关键特性:
支持自动 / 工具 / 手动三种模型迁移方式,推荐自动迁移(仅需 1 行导入代码);
内置 1400+PyTorch 兼容算子,覆盖 CNN、Transformer、MLP 等主流模型;
支持动态显存分配、多卡协同等高级特性。
2.3 核心技术模块概览
技术模块 核心内容 学习重点
环境搭建 CANN Toolkit 安装、torch_npu 插件配置、环境变量设置 版本兼容性匹配、设备状态验证
设备管理 昇腾 NPU 枚举、设备上下文创建、内存管理 torch_npu 设备接口使用
模型迁移 自动迁移 API 使用、数据格式适配、设备迁移 无修改迁移技巧、数据拷贝优化
模型训练 昇腾 NPU 上的训练流程、优化器配置、损失函数适配 训练性能监控、梯度计算调试
模型推理 离线推理、动态 AIPP 配置、结果验证 推理效率优化、数据预处理加速
性能分析 Ascend PyTorch Profiler 使用、瓶颈定位 关键指标解读、基础调优方法
算子调用 预置算子调用、自定义算子封装 算子参数配置、数据类型匹配
三、实战环境搭建(详细步骤)
3.1 系统要求
操作系统:Ubuntu 20.04/22.04(x86_64/ARM 架构);
硬件:昇腾 A1 系列 NPU(如 Ascend A100)或昇腾 AI 开发板;
依赖:Python 3.8~3.10、CANN Toolkit 7.0+、PyTorch 1.10~2.1。
3.2 分步安装流程
步骤 1:安装 CANN Toolkit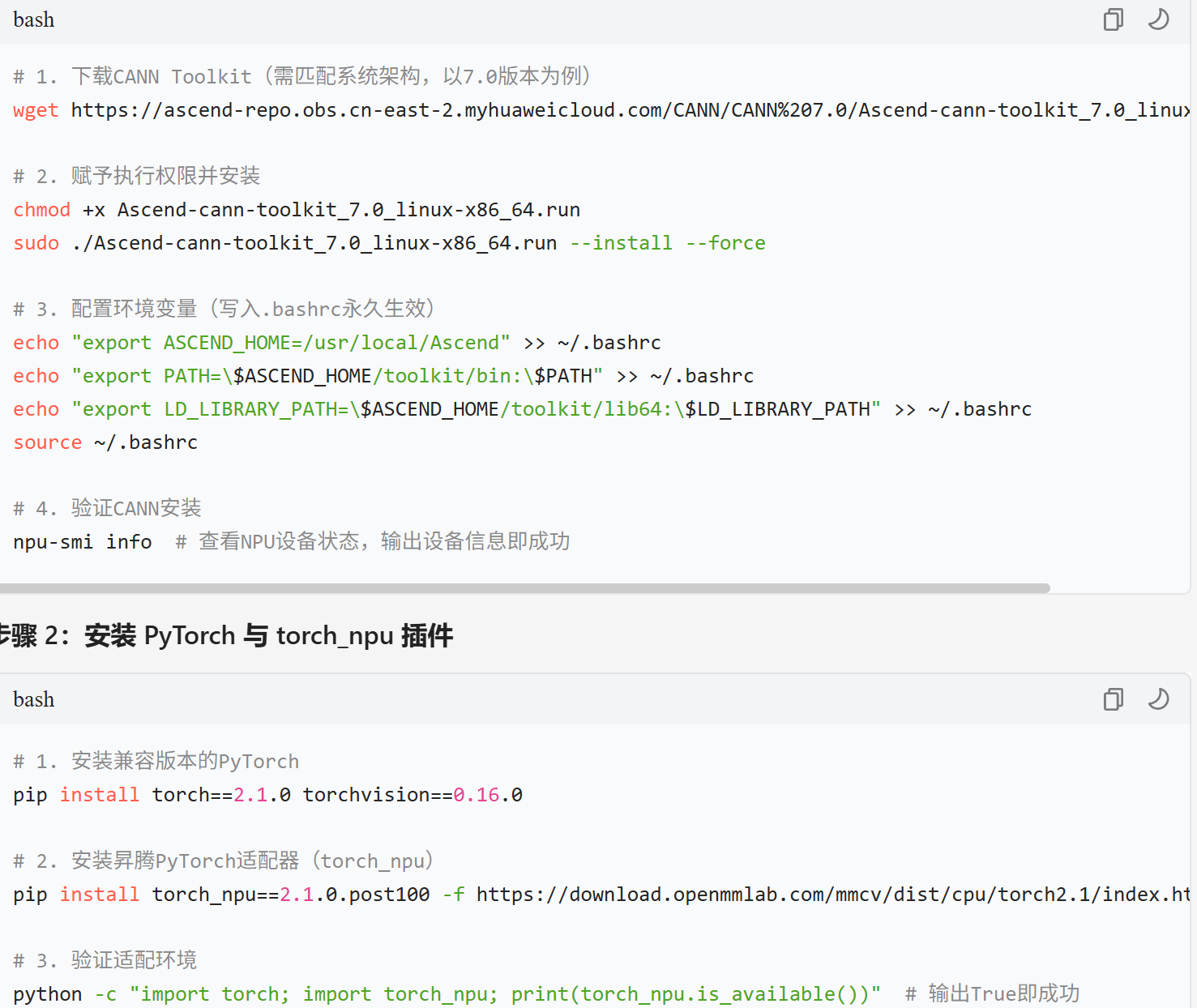
步骤 3:环境验证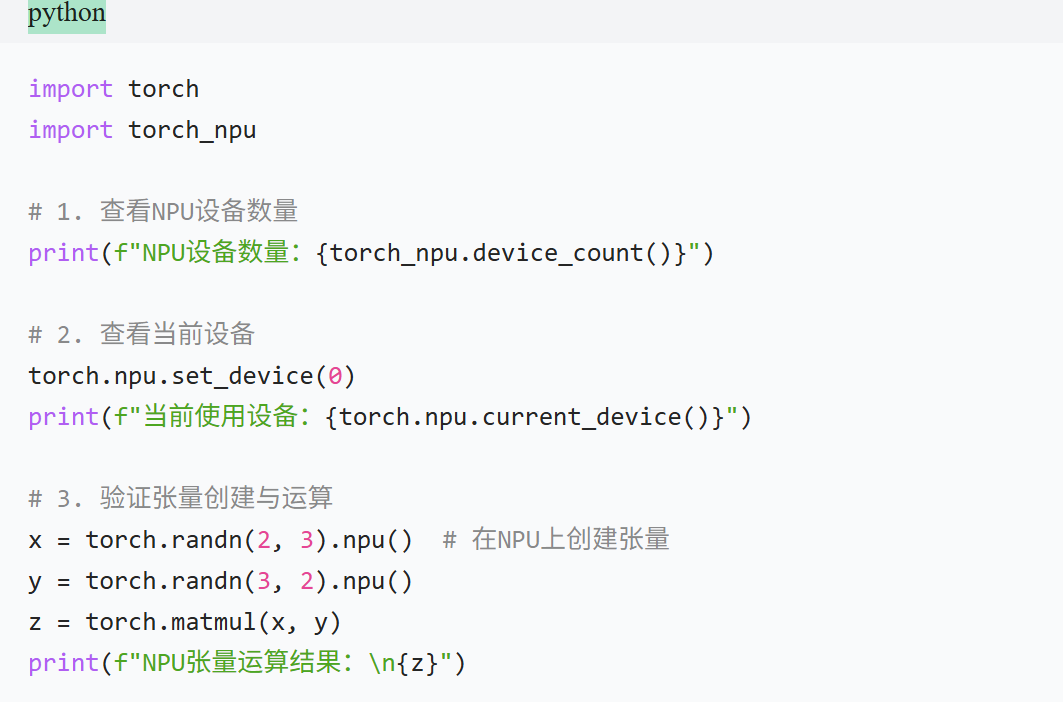
四、核心例题实战精讲
例题 1:PyTorch 模型自动迁移至昇腾 NPU(MLP 分类任务)
题目要求
实现一个简单的 MLP 模型,通过 CANN 的自动迁移功能,在昇腾 NPU 上完成训练与推理,验证模型迁移流程与训练效果。
技术要点
torch_npu 自动迁移 API 使用;
昇腾 NPU 上的数据加载与模型部署;
训练过程监控与结果验证。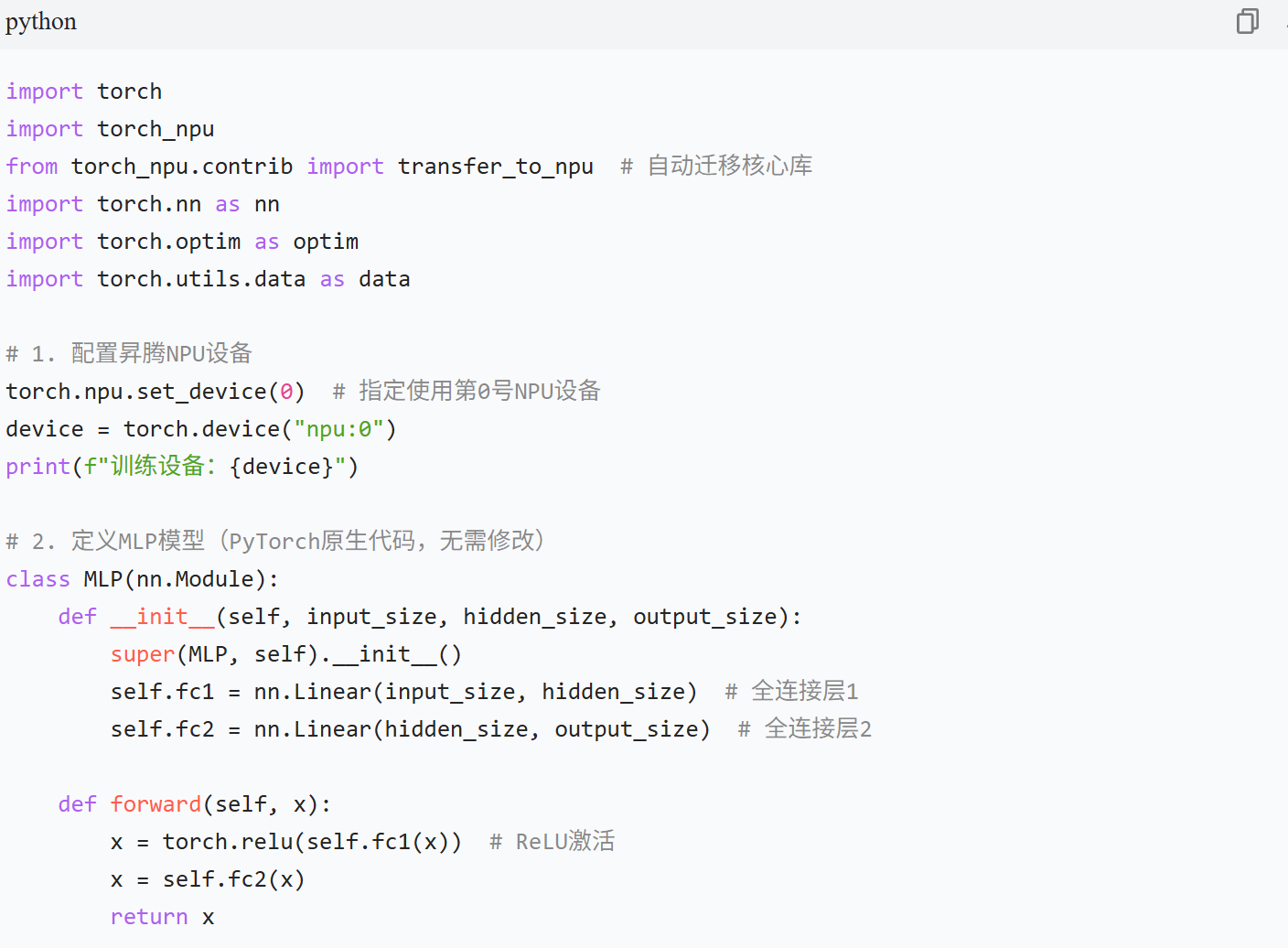


代码说明
自动迁移核心:from torch_npu.contrib import transfer_to_npu一行代码实现 CUDA 接口向 NPU 接口的自动转换;
设备适配:torch.device(“npu:0”)指定 NPU 设备,完全兼容 PyTorch 的设备管理逻辑;
数据与模型迁移:通过.to(device)统一实现,无需修改原有 PyTorch 代码结构。
预期输出
plaintext
训练设备:npu:0
Epoch [10/50], Loss: 0.6543
Epoch [20/50], Loss: 0.5876
Epoch [30/50], Loss: 0.5210
Epoch [40/50], Loss: 0.4689
Epoch [50/50], Loss: 0.4231
测试输入:[[2. 3. 4.]]
预测类别:0
模型参数所在设备:npu:0
例题 2:昇腾 NPU 性能分析(使用 Ascend PyTorch Profiler)
题目要求
基于例题 1 的 MLP 模型,使用 CANN 提供的 Ascend PyTorch Profiler 工具,采集训练过程中的 NPU 性能数据,分析计算效率与资源利用率。
技术要点
Ascend PyTorch Profiler 配置与使用;
关键性能指标(计算利用率、内存占用)解读;
性能数据可视化(TensorBoard)。
完整代码实现
python
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
1. 配置NPU设备
torch.npu.set_device(0)
device = torch.device(“npu:0”)
2. 定义MLP模型(同例题1)
class MLP(nn.Module):
def init(self, input_size, hidden_size, output_size):
super(MLP, self).init()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
3. 构建数据集(同例题1)
features = torch.tensor([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0), (7.0, 8.0, 9.0),
(1.0, 2.0, 3.0), (4.0, 5.0, 6.0), (7.0, 8.0, 9.0)], dtype=torch.float)
labels = torch.tensor([0, 1, 0, 0, 1, 0], dtype=torch.long)
custom_dataset = data.TensorDataset(features, labels)
dataloader = data.DataLoader(custom_dataset, batch_size=2, shuffle=True)
4. 初始化模型、损失函数与优化器
model = MLP(3, 5, 2).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
5. 配置Ascend PyTorch Profiler
experimental_config = torch_npu.profiler._ExperimentalConfig(
aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization, # 采集AI Core流水线利用率
profiler_level=torch_npu.profiler.ProfilerLevel.Level1, # 性能采集级别
l2_cache=False,
data_simplification=False
)
6. 启动性能采集并训练
with torch_npu.profiler.profile(
activities=[torch_npu.profiler.ProfilerActivity.CPU, # 采集CPU活动
torch_npu.profiler.ProfilerActivity.NPU], # 采集NPU活动
record_shapes=True, # 记录张量形状
profile_memory=True, # 记录内存占用
with_stack=True, # 记录调用栈
experimental_config=experimental_config,
schedule=torch_npu.profiler.schedule( # 采集调度策略
wait=1, # 等待1轮
warmup=1, # 热身1轮
active=2, # 活跃采集2轮
repeat=1,
skip_first=14 # 跳过前14轮(避免初始化干扰)
),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(
“/home/user/profiling_data” # 性能数据保存路径
)
) as prof:
num_epochs = 20
for epoch in range(num_epochs):
model.train()
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
prof.step() # 标记每轮结束,触发性能数据采集
print(f’Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
7. 查看性能数据(终端执行)
print(“\n性能数据已保存至 /home/user/profiling_data”)
print(“启动TensorBoard查看:tensorboard --logdir=/home/user/profiling_data”)
代码说明
性能采集配置:通过_ExperimentalConfig指定采集 AI Core 利用率等核心指标;
调度策略:schedule参数控制采集时机,避免初始化阶段的数据干扰;
可视化:通过 TensorBoard 查看 CPU/NPU 耗时、内存占用、算子执行效率等指标。
运行与分析步骤
运行代码,性能数据将自动保存至指定目录;
启动 TensorBoard:tensorboard --logdir=/home/user/profiling_data;
访问浏览器http://localhost:6006,查看关键指标:
NPU Compute Time:NPU 计算耗时占比;
Memory Usage:NPU 显存占用趋势;
AI Core Pipe Utilization:AI Core 流水线利用率(目标 > 70%)。
例题 3:自定义 CANN 算子的 PyTorch 调用(MyReLU 算子)
题目要求
通过 C++ 编写自定义 ReLU 算子(MyReLU),基于 CANN 框架编译为动态链接库,封装为 PyTorch 可调用的接口,在昇腾 NPU 上验证算子功能。
技术要点
自定义 CANN 算子的 “胶水层” 编写;
PyTorch 接口封装与动态链接库编译;
自定义算子的 NPU 执行与结果验证。
实现步骤
步骤 1:编写 C++“胶水层” 代码(算子适配插件)
创建文件my_relu_op.cpp,负责 PyTorch Tensor 与 CANN 数据格式的转换:
cpp
#include <torch/extension.h>
#include “ascendcl/ascendcl.h”
// 错误处理宏
#define CHECK_ACL_RET(ret, msg) do {
if (ret != ACL_ERROR_NONE) {
fprintf(stderr, “[ERROR] %s, ret=%d\n”, msg, ret);
return at::Tensor();
}
} while(0)
// 自定义MyReLU算子的NPU执行逻辑
at::Tensor my_relu_npu(const at::Tensor& self) {
// 1. 初始化ACL环境(若未初始化)
aclError ret = aclInit(NULL);
if (ret != ACL_ERROR_NONE && ret != ACL_ERROR_REPEAT_INIT) {
CHECK_ACL_RET(ret, “aclInit failed”);
}
// 2. 获取Tensor基本信息(形状、数据类型、设备ID)
auto self_sizes = self.sizes();
int64_t numel = self.numel();
int device_id = self.device().index();
// 3. 创建设备上下文
aclrtContext context = NULL;
ret = aclrtCreateContext(&context, device_id);
CHECK_ACL_RET(ret, "aclrtCreateContext failed");
// 4. 转换PyTorch Tensor为CANN数据格式
aclTensorDesc *input_desc = aclCreateTensorDesc(ACL_FLOAT, self_sizes.size(),
(int*)self_sizes.data(), ACL_FORMAT_ND);
aclDataBuffer *input_buf = aclCreateDataBuffer((void*)self.data_ptr(),
numel * sizeof(float));
// 5. 创建输出Tensor(PyTorch格式)
auto output = torch::empty_like(self);
aclTensorDesc *output_desc = aclCreateTensorDesc(ACL_FLOAT, self_sizes.size(),
(int*)self_sizes.data(), ACL_FORMAT_ND);
aclDataBuffer *output_buf = aclCreateDataBuffer((void*)output.data_ptr(),
numel * sizeof(float));
// 6. 调用CANN底层API执行MyReLU算子(模拟实现,实际需编译算子OM文件)
printf("Executing custom MyReLU operator on NPU...\n");
ret = aclopCreate(NULL, "MyReLU", ACL_ENGINE_SYS, ACL_FUNC_SCALAR);
CHECK_ACL_RET(ret, "aclopCreate MyReLU failed");
// 7. 执行算子(输入1个,输出1个)
const void *inputs[] = {input_buf};
void *outputs[] = {output_buf};
ret = aclopExecuteByDesc(NULL, 1, &input_desc, inputs, 1, &output_desc, outputs,
NULL, NULL, 0);
CHECK_ACL_RET(ret, "aclopExecuteByDesc failed");
// 8. 等待算子执行完成
ret = aclrtSynchronizeStream(NULL);
CHECK_ACL_RET(ret, "aclrtSynchronizeStream failed");
// 9. 释放资源
aclDestroyDataBuffer(input_buf);
aclDestroyDataBuffer(output_buf);
aclDestroyTensorDesc(input_desc);
aclDestroyTensorDesc(output_desc);
aclrtDestroyContext(context);
aclFinalize();
return output;
}
// 注册Python接口
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def(“my_relu_npu”, &my_relu_npu, “Custom MyReLU operator for Ascend NPU”);
}
步骤 2:编写 Python 接口封装
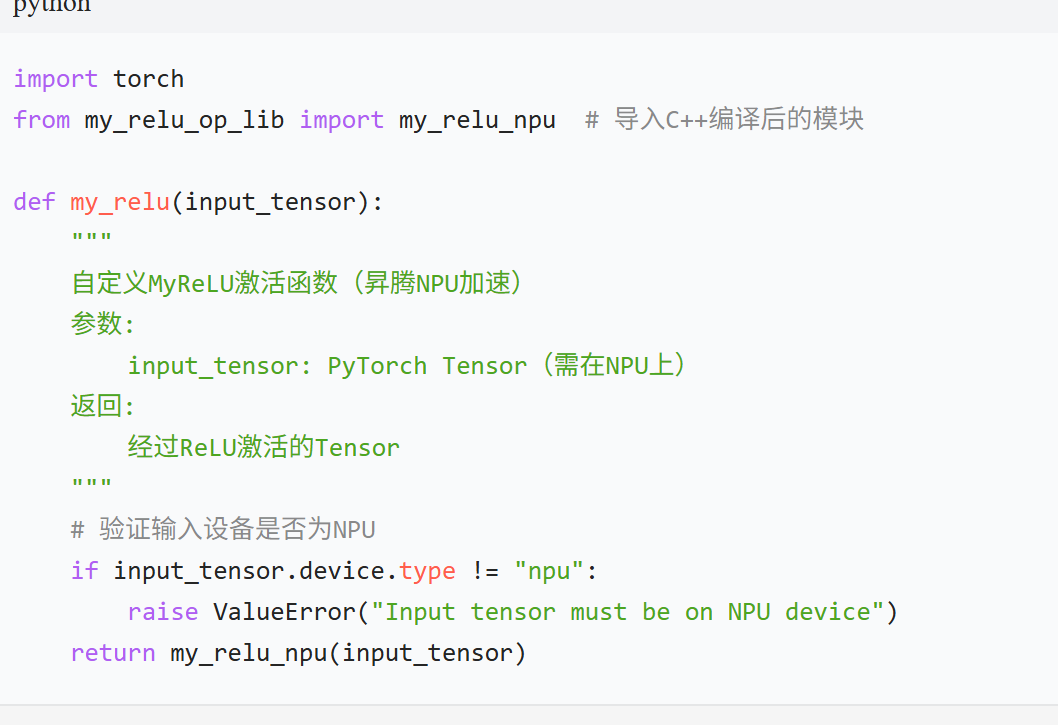
创建文件my_op_api.py,定义 PyTorch 可调用的接口:
python
import torch
from my_relu_op_lib import my_relu_npu # 导入C++编译后的模块
def my_relu(input_tensor):
“”"
自定义MyReLU激活函数(昇腾NPU加速)
参数:
input_tensor: PyTorch Tensor(需在NPU上)
返回:
经过ReLU激活的Tensor
“”"
# 验证输入设备是否为NPU
if input_tensor.device.type != “npu”:
raise ValueError(“Input tensor must be on NPU device”)
return my_relu_npu(input_tensor)
步骤 3:编写编译配置文件
创建setup.py,用于编译 C++ 代码为动态链接库:
python
from setuptools import setup, Extension
from torch.utils.cpp_extension import BuildExtension, CppExtension
配置编译参数(链接CANN库)
ascend_include_dirs = [“/usr/local/Ascend/toolkit/include”]
ascend_lib_dirs = [“/usr/local/Ascend/toolkit/lib64”]
setup(
name=“my_relu_op_lib”,
ext_modules=[
CppExtension(
“my_relu_op_lib”,
[“my_relu_op.cpp”],
include_dirs=ascend_include_dirs,
library_dirs=ascend_lib_dirs,
libraries=[“ascendcl”], # 链接CANN核心库
extra_compile_args=[“-std=c++17”]
)
],
cmdclass={
“build_ext”: BuildExtension
}
)
步骤 4:编译与安装
bash
编译动态链接库
python setup.py build_ext --inplace
安装到Python环境
pip install .
步骤 5:PyTorch 中调用自定义算子
创建测试文件test_custom_op.py:
python
import torch
import torch_npu
from my_op_api import my_relu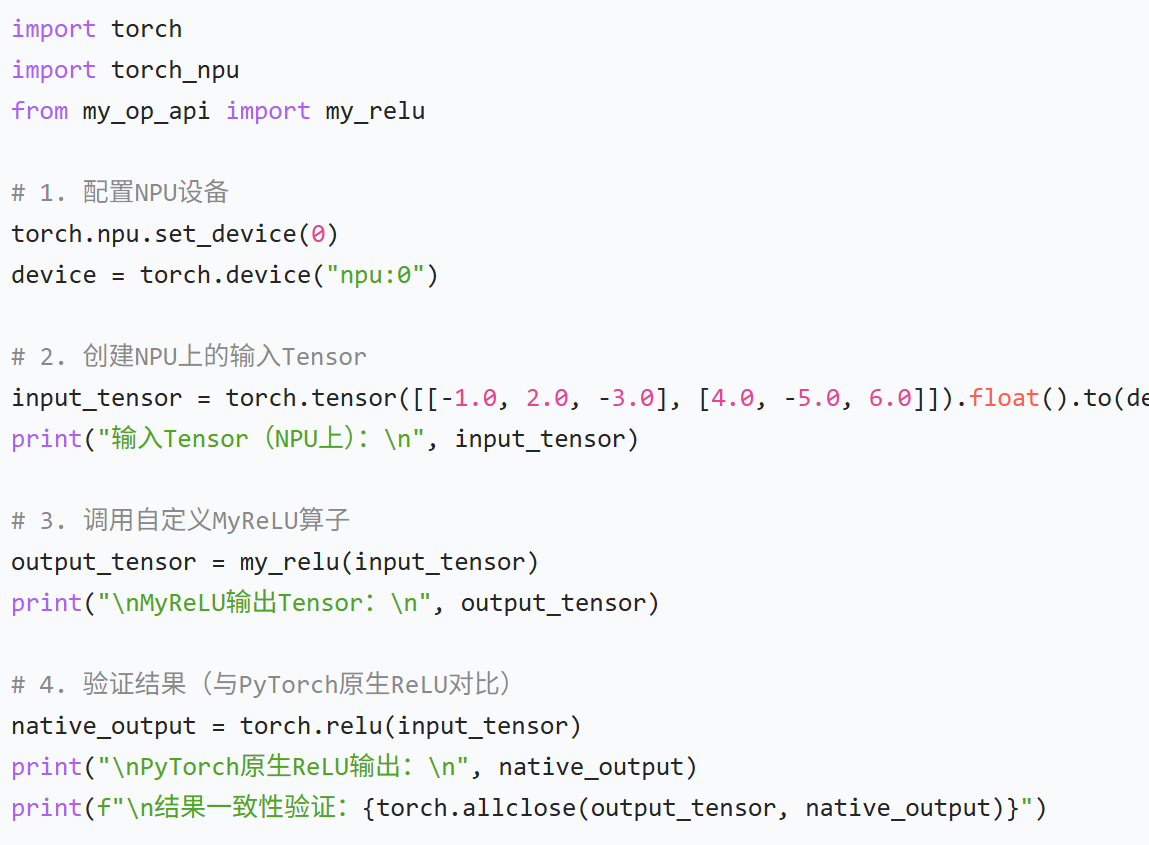
1. 配置NPU设备
torch.npu.set_device(0)
device = torch.device(“npu:0”)
2. 创建NPU上的输入Tensor
input_tensor = torch.tensor([[-1.0, 2.0, -3.0], [4.0, -5.0, 6.0]]).float().to(device)
print(“输入Tensor(NPU上):\n”, input_tensor)
3. 调用自定义MyReLU算子
output_tensor = my_relu(input_tensor)
print(“\nMyReLU输出Tensor:\n”, output_tensor)
4. 验证结果(与PyTorch原生ReLU对比)
native_output = torch.relu(input_tensor)
print(“\nPyTorch原生ReLU输出:\n”, native_output)
print(f"\n结果一致性验证:{torch.allclose(output_tensor, native_output)}")
预期输出
关键说明
“胶水层” 作用:C++ 代码负责 PyTorch Tensor 与 CANN 数据格式的互转,是自定义算子的核心适配逻辑;
编译依赖:需链接 CANN 的 ACL 库,确保ascend_include_dirs和ascend_lib_dirs路径正确;
无缝调用:封装后的 Python 接口与 PyTorch 原生函数完全兼容,可直接嵌入现有模型。
五、常见问题与排查技巧
5.1 环境配置类问题
问题 1:导入torch_npu报错 “ModuleNotFoundError”
排查:确认 torch 与 torch_npu 版本匹配,重新执行pip install torch_npu==对应版本。
问题 2:npu-smi info无设备输出
排查:检查 CANN 驱动与固件版本兼容性,重新配置环境变量source /usr/local/Ascend/toolkit/set_env.sh。
5.2 模型迁移类问题
问题 1:模型训练时提示 “算子不支持”
排查:使用torch_npu.op_checker.check_support(model)检查不支持的算子,替换为兼容算子或手动实现。
问题 2:数据拷贝速度慢
优化:使用异步数据拷贝torch.npu.stream(),或批量加载数据减少 Host-Device 交互。
5.3 性能类问题
问题 1:AI Core 利用率低(<30%)
优化:增大 batch size、启用算子融合、减少 CPU-NPU 数据传输。
问题 2:显存溢出(OOM)
优化:使用动态显存分配torch.npu.set_per_process_memory_fraction(0.8),或降低模型复杂度。
六、课程总结与进阶方向
6.1 核心知识点回顾
昇腾 A1+CANN+PyTorch 的生态适配逻辑:通过 torch_npu 插件实现无修改迁移;
核心流程:环境搭建→设备管理→模型迁移→训练 / 推理→性能优化;
关键工具:Ascend PyTorch Profiler(性能分析)、ACL 接口(底层开发)。
6.2 进阶学习方向
复杂模型迁移:Transformer、YOLO 等大型模型的昇腾 NPU 部署与优化;
分布式训练:基于 torch.distributed 实现多 NPU 协同训练;
算子开发:深入学习 CANN 算子编程(TBE/TVM),实现高性能自定义算子;
推理部署:模型量化(INT8)、OM 模型导出与离线推理优化。
4. 课程中常见问题与解决方案(Troubleshooting)
- 错误:ModuleNotFoundError: No module named ‘torch_npu’
· 原因:torch_npu 插件未正确安装。
· 解决:根据昇腾官方文档,使用与你的PyTorch和Python版本匹配的 torch_npu whl包进行安装。 - 错误:RuntimeError: Expected all tensors to be on the same device
· 原因:模型和数据不在同一个设备上。
· 解决:仔细检查代码,确保 model.to(device) 和 tensor.to(device) 被正确调用。 - NPU推理速度不如预期
· 原因:
· 首次运行包含算子编译时间。
· 数据搬运(CPU <-> NPU)成为瓶颈。
· Batch Size太小,未能充分利用NPU算力。
· 解决:
· 使用 warm-up 循环。
· 考虑使用数据流水线技术。
· 适当增大Batch Size。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=gos0rpt1v21

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)