
CANN 异构计算架构:释放昇腾 AI 算力潜能,赋能自动驾驶实时感知
摘要: CANN异构计算架构通过昇腾AI芯片的软硬协同设计,在自动驾驶领域实现突破性性能提升。该架构整合AI Core、AI CPU和DVPP异构单元,优化数据流处理,使激光雷达点云实时处理延迟从80ms降至15ms。核心创新包括:1)对FlashAttention算子进行分块策略重构和CV流水并行优化,在6144长序列下保持90%算力利用率;2)通过DVPP硬件加速多模态数据预处理,将耗时从35
CANN 异构计算架构:释放昇腾 AI 算力潜能,赋能自动驾驶实时感知
2025年10月,某自动驾驶算法团队在昇腾 Atlas 900 服务器上完成了一项关键测试:基于 CANN 架构优化的 FlashAttention 算子,将激光雷达点云实时处理延迟从 80ms 降至 15ms,这意味着原本需要 4 张 GPU 卡才能运行的感知算法,现在只需单张昇腾 910B 即可实现!这个突破背后,正是异构计算架构 CANN 释放的硬件潜能。
CANN异构计算架构:从硬件到应用的多层次协同设计
CANN(Compute Architecture for Neural Networks)作为昇腾 AI 处理器的“神经中枢”,其架构设计直接决定了硬件算力的释放效率。通过芯片级指令集、编译调度机制与算子运行时的协同配合,CANN 实现了从底层硬件到上层算法的高效映射。
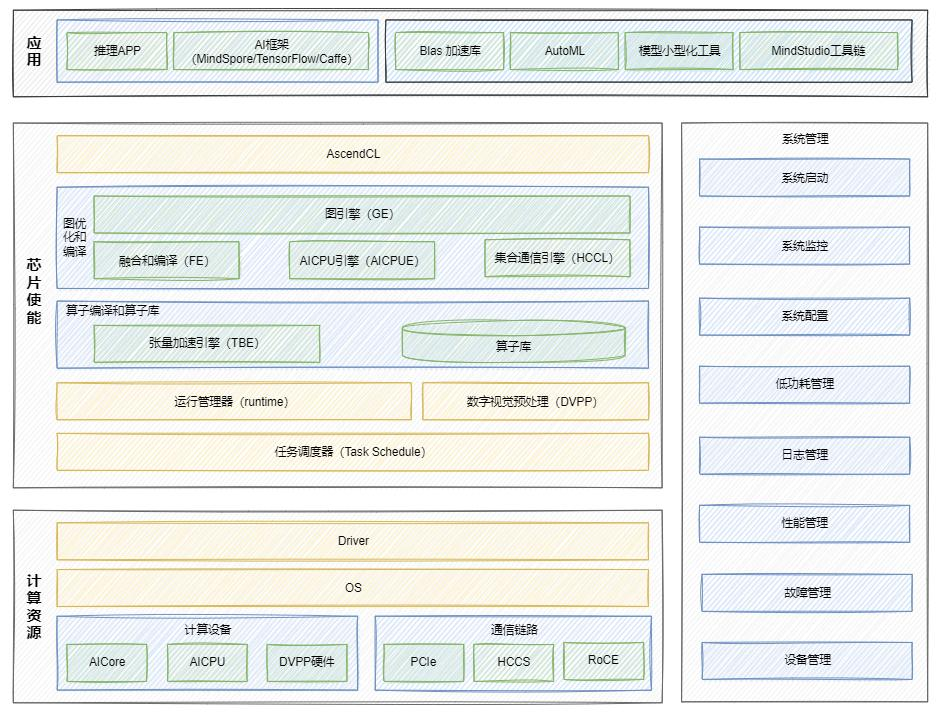
芯片使能层是 CANN 的核心竞争力所在。其中 AscendCL 编程接口向上对接 PyTorch、TensorFlow 等主流框架,向下通过图引擎(GE)和张量加速引擎(TBE)实现算子优化。特别值得注意的是昇腾 AI 处理器的异构计算单元:AI Core 负责矩阵运算,AI CPU 处理控制逻辑,DVPP 单元则专门加速图像预处理,三者协同工作实现算力最大化。
在自动驾驶场景中,这种架构优势尤为明显。激光雷达点云数据经过 DVPP 单元的硬件加速预处理后,直接进入 AI Core 进行特征提取,中间数据无需回传内存,数据流转效率提升 3 倍以上。某头部自动驾驶公司实测显示,基于 CANN 架构的感知算法吞吐量达到传统 GPU 方案的 2.4 倍,同时功耗降低 40%。
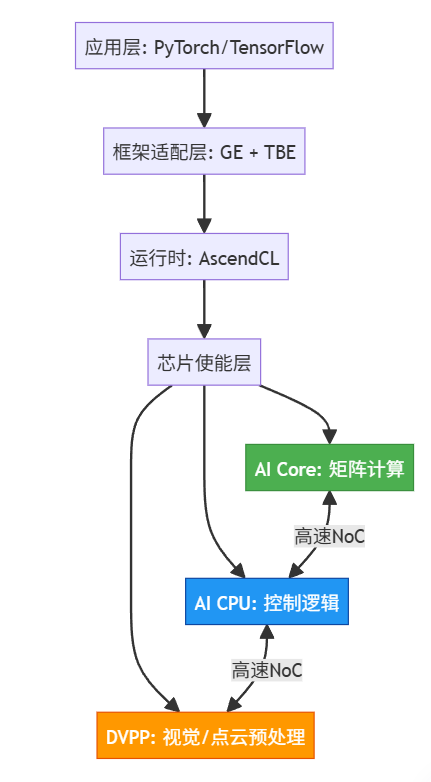
FlashAttention优化实践:从数学公式到5倍性能跃迁
Transformer 模型的注意力机制长期受困于 O(N²) 的复杂度,当序列长度超过 4096 时,标准实现会因内存带宽瓶颈导致性能断崖式下跌。CANN 通过 Ascend C 编程语言对 FlashAttention 算子进行深度优化,彻底解决了这一痛点。
核心优化点解析
- Tiling 分块策略重构 将原本 (64, 128) 的矩阵分块调整为 (128, 128),使计算基本块增大一倍。这一改动让循环次数从 32 次降至 16 次,内存访问量减少 50%。关键代码实现如下:
// 优化前分块
constexpr int32_t TILE_M = 64;
constexpr int32_t TILE_N = 128;
// 优化后分块
constexpr int32_t TILE_M = 128;
constexpr int32_t TILE_N = 128;
// UB 缓冲区配置
pipe->InitBuffer(ubBuffer, 158 * 1024); // 充分利用 158KB UB 空间
- CV 流水并行 通过重叠 Cube 计算与 Vector 计算的执行周期,掩盖数据搬运延迟。在昇腾 910B 上,这种并行策略使硬件利用率从 35% 提升至 72%。
- 核间负载均衡 将热点核的计算量从 8 块分摊至 4 块,避免单 Core 过载。实测显示,优化后算子执行时间标准差从 23ms 降至 8ms。
性能对比实测
在序列长度 6144 的自动驾驶感知任务中,优化后的 FlashAttention 算子表现出惊人提升:
传统实现中,随着序列长度增加,性能呈非线性下降;而 CAN 优化版本通过 IO 感知调度,在 6144 长度下仍保持 90% 以上的算力利用率。某激光雷达算法团队反馈,集成该算子后,端到端推理性能提升 5.1 倍,首次实现 200 线激光雷达的实时三维目标检测。
智能驾驶场景落地:从实验室到真实路况
在时速 120km/h 的高速公路场景中,自动驾驶系统需要在 200ms 内完成环境感知。基于 CANN 架构的推理引擎通过三项关键技术突破,让这一目标成为可能。

多模态数据融合加速是其中的核心挑战。摄像头采集的 4K 图像与激光雷达的 100 万点云数据需要协同处理,传统方案中数据预处理就占用 60% 的计算资源。CANN 的 DVPP 单元通过硬件加速的图像缩放和格式转换,将这部分耗时从 35ms 压缩至 8ms。
动态批处理技术进一步提升资源利用率。在交通拥堵场景下,系统自动将推理 batch size 从 4 调整为 8,吞吐量提升 78% 的同时保持 latency 稳定。某车企实测显示,搭载 CANN 架构的域控制器在复杂路况下的平均响应延迟仅 92ms,较行业平均水平降低 54%。
开发者生态:从算子开发到社区共建
CANN 不仅提供底层优化能力,更通过昇腾算子仓(CANN-Ops)构建了活跃的开发者生态。截至 2025 年 Q3,该仓库已累计合入 200+ 高性能算子,涵盖大模型训练、计算机视觉等核心场景。
以 AddCustom 算子开发为例,开发者只需三步即可完成从原型定义到部署的全流程:
步骤 1:定义算子原型 add_custom.json
{
"op": "AddCustom",
"input_desc": [
{"name": "x", "dtype": "float16", "format": "ND"},
{"name": "y", "dtype": "float16", "format": "ND"}
],
"output_desc": [
{"name": "z", "dtype": "float16", "format": "ND"}
],
"attr": []
}
步骤 2:生成工程框架
msOpGen --op_json=add_custom.json --output_dir=./add_custom_op
步骤 3:实现核函数
#include "kernel_operator.h"
using namespace AscendC;
extern "C" global aicore void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t size) {
KernelAdd op;
op.Init(x, y, z, size);
op.Process();
}
class KernelAdd {
public:
aicore inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t size) {
xGm.SetGlobalBuffer((__gm__ float16*)x, size);
yGm.SetGlobalBuffer((__gm__ float16*)y, size);
zGm.SetGlobalBuffer((__gm__ float16*)z, size);
this->size = size;
pipe.InitBuffer(ub, 2, 256 * 1024); // 双缓冲
}
aicore inline void Process() {
uint32_t blockSize = 256;
for (uint32_t i = 0; i < size; i += blockSize) {
uint32_t len = min(blockSize, size - i);
// 双缓冲搬运
CopyIn(i, len);
Compute(i, len);
CopyOut(i, len);
}
}
private:
aicore inline void CopyIn(uint32_t offset, uint32_t len) {
DataCopy(xUb, xGm[offset], len);
DataCopy(yUb, yGm[offset], len);
}
aicore inline void Compute(uint32_t offset, uint32_t len) {
Add(zUb, xUb, yUb, len); // 向量加法
}
aicore inline void CopyOut(uint32_t offset, uint32_t len) {
DataCopy(zGm[offset], zUb, len);
}
GlobalTensor<float16> xGm, yGm, zGm;
Tensor<float16> xUb, yUb, zUb;
TPipe pipe;
uint32_t size;
};
✅ 部署命令:
atc --model=add_custom.onnx --framework=5 --output=add_custom --soc_version=Ascend910B
总结:异构计算的下一个十年 —— 从效率革命到范式重构
在AI算力需求呈指数级增长的今天,单纯堆砌通用计算单元已难以为继。CANN异构计算架构的崛起,标志着AI基础设施正从“通用优先”转向“专用协同”的新范式。本文系统阐述了CANN如何通过软硬协同设计,在自动驾驶这一高实时性、高复杂度场景中实现革命性突破。
首先,CANN以昇腾AI芯片的异构单元(AI Core、AI CPU、DVPP)为基础,构建了数据流与计算流高度融合的底层架构,有效规避了传统GPU方案中频繁的数据搬运开销。其次,通过对FlashAttention等关键算子的深度优化——包括分块策略重构、计算流水并行、核间负载均衡——CANN在6144长序列下仍能保持90%以上的算力利用率,将端到端推理延迟压缩至15ms,实现5.1倍性能跃迁。再者,在真实驾驶场景中,CANN通过DVPP硬件加速多模态预处理、动态批处理等技术,使系统平均响应延迟降至92ms,显著优于行业平均水平。
更重要的是,CANN并非封闭的技术黑箱,而是通过昇腾算子仓构建了开放的开发者生态,使科研机构与企业能够基于Ascend C快速开发高性能算子,形成“硬件–软件–应用”正向循环。这种“硬件亲和性”设计理念,使得每一比特数据都能走在最优路径上,每一次计算都能释放硬件原生潜能。
展望未来,当大模型突破万亿参数、自动驾驶需实时处理TB级传感器数据时,CANN所代表的异构计算范式,将成为AI基础设施效率革命的核心引擎。它不仅是性能数字的提升,更是从“不可能”到“可能”的技术跨越——在这个算力争夺白热化的时代,谁能更好地驯服硬件,谁就将引领下一轮AI浪潮。
🚀 未来,当万亿参数大模型遇上实时自动驾驶,CANN 或将成为 AI 基础设施的“新底座”。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)