
1000道算法工程师面试题(大模型)—— 第三部分
深度学习框架技术解析摘要 反向传播原理基于链式法则,通过反向拓扑顺序计算梯度并累加。PyTorch等框架通过动态图(记录计算图与梯度函数)或静态图(预先编译优化)实现自动求导。 框架模式对比:PyTorch动态图(易调试但开销大)适合研发,TensorFlow静态图(优化充分但调试难)适合部署。MindSpore采用动静结合,通过MindIR实现图编译优化,尤其适合昇腾硬件。 关键组件关系:PyT
31、请简要说明反向传播(backpropagation)的原理,以及自动求导在框架中的实现思路。
答案:
-
反向传播的数学本质:链式法则(Chain Rule)
- 有一个复合函数:
( y = f(x) = f_n(\dots f_2(f_1(x)) \dots) )
想要 (\frac{\partial L}{\partial x}),其中 (L) 是损失函数。 - 链式法则告诉我们:
(\frac{\partial L}{\partial x} = \frac{\partial L}{\partial f_n} \cdot \frac{\partial f_n}{\partial f_{n-1}} \cdots \frac{\partial f_1}{\partial x}) - 计算图里,就是:从输出往输入方向,一层一层把梯度乘回去。
- 有一个复合函数:
-
反向传播的计算流程(以一个前馈网络为例):
-
前向传播:按拓扑顺序计算每一层的输出,并把中间结果(激活值)存起来。
-
从损失开始:先算 (\frac{\partial L}{\partial y})。
-
反向传播:
- 按计算图的反拓扑顺序遍历每个算子;
- 对每个算子,根据局部导数(算子的梯度公式)和“后面传来的梯度”算出“前面输入的梯度”;
- 把同一张量的多个梯度累加。
-
-
自动求导在框架中的实现思路(以 PyTorch 为例):
-
使用 反向模式自动微分(reverse-mode autodiff):
-
前向时:
- 记录一个 计算图(动态的):每个 Tensor 记住是谁算出来(
grad_fn); - 每个算子注册自己的反向函数(如何根据输出梯度算输入梯度)。
- 记录一个 计算图(动态的):每个 Tensor 记住是谁算出来(
-
反向时:
- 从 loss 调用
loss.backward(); - 框架从 loss 对应的节点开始,沿着
grad_fn指针往前回溯; - 用栈/队列管理待处理节点,做一次反向拓扑遍历;
- 在叶子节点(参数)上把梯度写到
param.grad里。
- 从 loss 调用
-
-
静态图框架(如 TF1 / MindSpore Graph 模式)会先构建完整的图,再一次性编译出前向 + 反向的优化图,一起运行。
-
32、PyTorch 的动态图(eager mode)与 TensorFlow 静态图模式有什么区别?各自优劣势是什么?
答案:
这里的 “TF 静态图” 主要指 TF1.x 的
Session.run风格;TF2 默认是 eager +tf.function的组合。
-
PyTorch 动态图(define-by-run, eager):
-
每执行一步 Python 代码,算子就立刻执行,边跑边建图。
-
优点:
- 调试方便:可以 print 中间结果,用 pdb/IDE 断点,逻辑错误容易定位。
- 控制流自然:
if / for / while就是普通 Python 语法。 - 对复杂结构(可变长度、递归、Dynamic RNN)很友好。
-
缺点:
- 图是每个 iteration 重新构建,解释器开销较大。
- 图级优化空间相对小(当然现在有
torch.compile之类在补)。
-
-
TensorFlow 静态图模式(define-and-run):
-
先构建一张完整的计算图(
tf.Graph),再在Session.run()中执行。 -
优点:
- 图已知且固定,方便做全局优化(算子融合、内存规划、跨设备调度)。
- 更容易导出成跨语言/跨平台的部署格式(如 SavedModel)。
- 在大规模分布式场景下,调度器能利用图结构做更多优化。
-
缺点:
- 调试麻烦:错误可能在 run 时才出现,堆栈不直观。
- 控制流要用
tf.cond / tf.while_loop,不如原生 Python 直观。 - 代码风格对新人不够友好。
-
-
总结:
- 研究/原型阶段:动态图(PyTorch、TF2 eager)更灵活。
- 部署/极致性能场景:静态图/图编译(TF1, TF2+
tf.function, JAX, MindSpore Graph 模式)更有优势。
33、解释一下 PyTorch 中的 nn.Module、nn.Parameter、Tensor 之间的关系。
答案:
-
Tensor
- 最基础的数据结构:带有 shape、dtype、device 的多维数组。
- 可以设置
requires_grad=True参与自动求导。
-
nn.Parameter
-
是
Tensor的子类,本质上仍是 Tensor。 -
特点:
- 默认
requires_grad=True; - 放在
nn.Module的属性里时,会被自动注册为“可训练参数”,出现在model.parameters()里。
- 默认
-
典型例子:线性层的
weight、bias都是nn.Parameter。
-
-
nn.Module
-
神经网络的基本构建单元,既可以表示一层(
nn.Linear),也可以表示一个子网络或整个模型。 -
职责:
- 持有子模块(
self.conv = nn.Conv2d(...)); - 持有参数(
self.weight = nn.Parameter(...)); - 定义前向计算(
forward(self, x)); - 提供一系列工具方法:
parameters()、children()、eval()/train()等。
- 持有子模块(
-
关系可以总结为:
Tensor是“原材料”;nn.Parameter是被标记为“要训练的 Tensor”;nn.Module是“装配好的零部件/整机”,负责组织参数和前向逻辑。
34、在 PyTorch 中如何排查梯度为 None 或梯度爆炸/消失问题?你有何经验?
答案:
-
梯度为 None 排查:
常见原因:
-
这个 Tensor 不是叶子节点(比如对参数做了某些操作):
w = nn.Parameter(...)w2 = w * 2,优化器里用了w2,那w2.grad有,w.grad没有。
-
requires_grad=False或中途.detach():- 某个环节用了
.detach()/.data破坏了计算图。
- 某个环节用了
-
没有参与到 loss 的计算:
- 你以为某个分支参与了,但实际上被
if条件跳过了。
- 你以为某个分支参与了,但实际上被
-
in-place 操作破坏了计算图:
- 如
x += 1、relu_(x)在某些情况下会报错或导致梯度为 None。
- 如
排查经验:
-
在 backward 前后打印/检查:
for name, p in model.named_parameters(): if p.grad is None: print("No grad for:", name) -
用
torch.autograd.set_detect_anomaly(True):当某个算子 backward 出 NaN 或出现问题时,会抛异常并带上具体算子栈信息。 -
对可疑中间结果检查
.requires_grad和.grad_fn是否存在。
-
-
梯度爆炸(exploding gradients):
现象:
- loss 变成 NaN / inf;
- 参数变成 NaN;
- 梯度范数非常大。
常见原因:
- 学习率太大;
- 模型太深 + 不合理初始化;
- RNN 等序列模型未做梯度裁剪。
解决方案:
- 梯度裁剪:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm) - 调低学习率,或在 warmup 阶段用小 LR。
- 使用更稳定的归一化/初始化(LayerNorm、RMSNorm、Xavier/Kaiming)。
-
梯度消失(vanishing gradients):
现象:
- 前面层的梯度非常小(接近 0),模型训练很慢,loss 长时间不下降。
- 深度网络中的早期层几乎不更新。
常见原因:
- 使用饱和型激活函数(sigmoid、tanh)且网络很深。
- 没有残差连接,信息/梯度难以传递。
解决方案:
- 使用 ReLU / GELU 等非饱和激活。
- 加残差连接、归一化(Transformer 里非常典型)。
- 合理初始化,使得输出方差不过大也不过小。
-
实战习惯:
-
经常在训练过程中记录梯度的范数(比如每个 step 记录 global grad norm 到 TensorBoard),一眼看出爆炸/消失趋势。
-
对关键层(embedding,最后一层)加 hook:
def grad_hook(module, grad_in, grad_out): print(module, grad_out[0].norm()) some_layer.register_backward_hook(grad_hook)
-
35、MindSpore 的计算图与 PyTorch 相比,有哪些设计上的差异?在性能上有什么优势?
答案:
(只谈关键差异,细节可以根据实际版本再看官方文档)
-
动态图 vs 动静结合:
-
PyTorch:典型的“动态计算图”(eager),每次前向边执行边建图。
-
MindSpore:
- 提供 PyNative 模式(动态图,类似 PyTorch,用于开发调试);([mindspore.cn][1])
- 提供 Graph 模式(静态图):将 Python 代码转换为统一 IR(MindIR),在部署时进行图编译和优化。([mindspore.cn][2])
-
-
IR & 编译优化:
-
MindSpore 在 Graph 模式下:
- 将 Python 源码转换成 MindIR 计算图;
- 在图级做全局优化:算子融合、内存复用、whole graph sink 等;
- 然后把整个图 offload 到硬件设备(尤其是 Ascend)。([Gitee][3])
-
PyTorch 虽然也有
torch.jit/torch.compile等图编译手段,但整体设计起点是 eager。
-
-
自动并行与硬件深度适配:
-
MindSpore 官方设计时非常强调“面向芯片的深度图优化”,尤其是 Ascend:
- 通过自动并行(数据并行 + 算子级并行),最大化利用异构硬件;([mindspore.cn][4])
- Graph-Kernel Fusion(AKG)自动生成高性能融合算子,在 Ascend/GPU 上提高算力利用率。([mindspore.cn][5])
-
PyTorch 的分布式/并行更多依赖外部库和生态(Megatron-LM、DeepSpeed 等)以及手工策略。
-
-
性能优势(典型场景):
- 在网络结构比较固定、训练/推理流程稳定的场景,MindSpore 的 Graph 模式可以通过编译期优化和算子融合在 Ascend 上获得非常可观的性能提升(文献中提到过相对 CPU/GPU host 调度方式的多倍加速)。([施普林格链接][6])
- 代价是:静态图对 Python 语法有一定约束,调试不如纯动态图随意。
36、在训练中常见的优化器(SGD、Adam、AdamW 等)有什么区别?如何选择合适的优化器?
答案:
-
SGD(带/不带动量):
-
纯 SGD:
(\theta_{t+1} = \theta_t - \eta \nabla L(\theta_t)) -
带动量(Momentum):
(v_{t+1} = \mu v_t + \nabla L(\theta_t))
(\theta_{t+1} = \theta_t - \eta v_{t+1}) -
特点:
- 单纯 SGD:收敛稳定但可能慢,尤其在鞍点附近。
- SGD+Momentum:对噪声鲁棒,常用于 CV 任务、ResNet 等,大 batch 训练中表现好。
-
优点:在一些任务上泛化性能好(CV 很多 SOTA 仍偏向 SGD)。
-
-
Adam:
-
自适应学习率(对每个参数维护一阶/二阶矩估计):
- (m_t) 估计梯度均值;
- (v_t) 估计梯度平方均值。
-
学习率对不同参数自动缩放。
-
优点:
- 收敛快,对超参数不太敏感;
- 在 NLP、Transformer、大模型预训练中非常常用。
-
缺点:
- 默认“L2 正则”其实是加在更新量上(非真正意义的 weight decay),在一些任务上泛化略差。
-
-
AdamW:
-
对 Adam 做了 decoupled weight decay:
- 把权重衰减和梯度更新解耦,真正意义上的 weight decay。
-
在 Transformer / BERT / GPT 系列训练中几乎是标配。
-
-
选择建议:
-
大部分 NLP/Transformer/大模型:
- AdamW + 合适的 LR schedule(warmup + cosine)是主流。
-
经典 CV / 图像分类(ResNet 系列):
- SGD + momentum + cosine/step decay 常常泛化更好。
-
小模型 / 资源有限 / 实验阶段:
- Adam 用起来更省心,可以快速试出有效学习率区间。
-
37、请解释 BatchNorm、LayerNorm、RMSNorm 等归一化方法的差异及应用场景。
答案:
-
BatchNorm(批归一化):
-
对象:同一层同一通道在一个 batch 内的分布。
-
对 CNN 来说,通常是对
(N, C, H, W)中的N, H, W维求均值和方差。 -
特点:
- 对 batch size 较敏感,小 batch 时统计不稳定。
- 训练和推理使用不一样的统计量(running mean/var)。
-
场景:
- 经典 CNN 网络(ResNet、VGG)中非常有效;
- 对 RNN/Transformer 适配不太自然。
-
-
LayerNorm(层归一化):
-
对象:每个样本内部的所有特征维度。
-
例如对
(batch, seq_len, hidden_size)中的最后一个维度hidden_size求均值方差。 -
特点:
- 与 batch size 无关,小 batch 也稳定;
- 对序列长度变化不敏感;
- 训练/推理使用同一套参数和计算方式。
-
场景:
- Transformer & 语言模型的标配(pre-LN、post-LN 结构)。
-
-
RMSNorm:
-
类似 LayerNorm,但只使用 均方根(RMS),不减均值:
- 归一化因子是 (\sqrt{\mathrm{mean}(x^2)}) 而不是 std。
-
特点:
- 计算略简单一些;
- 实践中在大语言模型中表现良好,且可能稍微更稳定(“均值”部分留给残差结构自己处理)。
-
场景:
- 许多 LLM(如一些开源模型)开始用 RMSNorm 替代 LayerNorm。
-
简单记:
- CNN:BatchNorm。
- Transformer / LLM:LayerNorm / RMSNorm。
- 小 batch、分布式很碎的场景:更倾向与 BN 解耦(GroupNorm / LayerNorm / RMSNorm)。
38、请说明混合精度训练(FP16/BF16)的原理,以及在 PyTorch 中的具体使用方式。
答案:
-
混合精度训练原理:
-
目标:加速 + 降低显存占用,同时尽量不损失精度。
-
做法:
-
大部分计算用低精度(FP16 或 BF16)进行:
- Tensor 核(Tensor Core)对 FP16/BF16 能显著提速。
- 显存占用近似减半。
-
关键部分仍用 FP32:
- 如权重的主副本(master weights);
- 累积梯度等敏感操作。
-
为 FP16 减少溢出/下溢问题,引入 loss scaling:
- 在 backward 前先把 loss 乘一个大系数 S,反向后梯度再除以 S。
- 这样梯度的数值落在更安全的 FP16 范围内。
-
-
-
FP16 vs BF16:
- FP16:10 位 mantissa、5 位 exponent,动态范围相对小,容易溢出,需要 loss scaling。
- BF16:7 位 mantissa、8 位 exponent,动态范围与 FP32 类似,一般不需要 loss scaling,训练稳定性更好。
-
PyTorch 中的使用方式(常见写法):
model = model.to(device) optimizer = ... scaler = torch.cuda.amp.GradScaler() # FP16 时常用 for inputs, labels in dataloader: inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() with torch.cuda.amp.autocast(dtype=torch.float16): outputs = model(inputs) loss = criterion(outputs, labels) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()-
对 BF16,可以直接:
with torch.cuda.amp.autocast(dtype=torch.bfloat16): ...通常不需要
GradScaler。
-
-
注意事项:
- 部分算子对 FP16/BF16 不稳定/不支持,需要在 autocast 里自动回退到 FP32(框架会处理大部分)。
- 大模型训练几乎默认用混合精度,否则显存和速度都撑不住。
39、如何在多卡训练中保证梯度同步正确性?分布式训练中常见的坑有哪些?
答案:
-
梯度同步的基本机制(数据并行 DDP):
- 每张卡(每个进程)持有一份完整模型副本。
- 每张卡拿到不同的 mini-batch 子集,做前向 + backward。
- 在
loss.backward()时,框架(如DistributedDataParallel)会对每个参数的梯度做一次 all-reduce(求和并平均),保证每个进程上的param.grad一致。 - 之后,每个进程独立调用
optimizer.step(),更新后的参数仍然保持一致。
-
确保正确性的关键点:
-
使用
DistributedDataParallel(DDP),而不是老的DataParallel。 -
每个 rank 都要执行完全相同的 forward/backward 逻辑:
- 不要让某些 rank 条件分支不同(如 rank0 多做了一些 loss 计算,但参与梯度)。
-
使用
DistributedSampler保证每个 rank 看到的数据 shard 不重复 / 可控。 -
避免在 forward 中改变模型结构或
requires_grad状态(DDP 需要固定参数拓扑)。
-
-
常见坑:
-
find_unused_parameters=True/False 设置不当:
- 网络里有条件分支导致某些参数在某个 iteration 未被用到。
- DDP 默认需要知道哪些参数被使用以便正确同步;否则会 deadlock 或梯度为 0。
-
梯度累积(gradient accumulation)+ DDP 的交互:
- 在多个 step 累积梯度时,可能无意中多次 all-reduce,导致梯度不正确。
- 需要配合
no_sync()上下文控制同步频率。
-
随机数不同步:
- dropout、数据增强等如果需要跨 rank 一致,需要统一 seed / broadcast 随机状态。
-
不正确的学习率缩放:
- global batch size = per-GPU batch * GPU 数;
- 大 batch 训练时往往需要按一定规则(线性 scaling)调整学习率。
-
40、在大模型训练中,数据并行(DP)、模型并行(MP)、流水线并行(PP)分别是什么?
答案:
-
数据并行(Data Parallel, DP):
-
思想:复制模型,拆分数据。
-
做法:
- 每张卡一份完整模型;
- 输入 batch 在不同卡上分块;
- 前向+反向后用 all-reduce 同步梯度。
-
优点:
- 实现简单,框架原生支持;
- 适用于模型本身能放进单卡显存的情况。
-
缺点:
- 模型太大时,单卡装不下,DP 也无能为力。
-
-
模型并行(Model Parallel, MP / Tensor Parallel):
-
思想:拆模型(按张量维度切)。
-
示例(Tensor Parallel):
- 把一个大矩阵 (W) 按列切在多卡上;
- 前向时每张卡计算自己的部分,再通过 all-reduce / all-gather 合并。
-
优点:
- 可以把一个极大的模型拆到多卡上,共享显存。
-
缺点:
- 通信复杂(在每一层甚至每个算子都要通信);
- 对框架支持和工程能力要求高。
-
-
流水线并行(Pipeline Parallel, PP):
-
思想:按层切模型,像“装配线”一样。
-
做法:
- 把模型分为若干 stage(比如 4 段层),放到不同 GPU 上;
- 输入 batch 再拆成多个 micro-batch,从前到后依次在不同 stage 上流动;
- 通过 fill & drain pipeline 方式,把前向/反向的执行“流水化”。
-
优点:
- 适合层数多的模型(Transformer 堆很多层);
- 通信主要发生在 stage 之间,相对规律。
-
缺点:
- 调度复杂,需要合理设计 micro-batch 数,防止“气泡”(空闲时间);
- 对梯度累积和显存管理要求高。
-
在大模型训练(例如 GPT-XXB)中,一般是 DP + TP(MP的一种)+ PP 三者叠加使用。
41、你如何在 MindSpore / PyTorch 中实现自定义算子(OP),以及在什么情况下需要自定义算子?
答案:
-
什么时候需要自定义 OP:
- 算法中有框架没有的算子或组合算子;
- 现有算子性能不满足要求,需要更高性能的融合/特化实现;
- 需要调用某些特定硬件指令或加密库(安全推理等)。
-
PyTorch 自定义算子:
-
Python 级别(自定义 autograd.Function):
-
适合逻辑不算特别重、对性能要求不极端的情况。
-
例子:
class MyOp(torch.autograd.Function): @staticmethod def forward(ctx, input): # 保存反向需要的中间值 ctx.save_for_backward(input) return some_forward_impl(input) @staticmethod def backward(ctx, grad_output): (input,) = ctx.saved_tensors grad_input = some_backward_impl(input, grad_output) return grad_input
-
-
C++/CUDA 扩展:
- 用
torch.utils.cpp_extension编译 C++/CUDA 代码; - 在 C++ 实现 forward/backward 的 kernel,再封装为 Python 可调用模块;
- 能充分利用 GPU/CPU 特性,实现高性能算子。
- 用
-
-
MindSpore 自定义算子(概念上):
-
MindSpore 支持在静态/动态图中定义自定义算子,核心思路类似:
- 在 Python 层定义一个
Primitive或自定义算子接口; - 为不同后端(CPU/GPU/Ascend)注册对应的 kernel 实现;
- 图编译时把这个算子融合进 MindIR,参与图优化和自动微分。([PyPI][7])
- 在 Python 层定义一个
-
对于 Ascend,还可以利用 AKG / CANN 工具自动生成高性能 kernel。
-
42、请描述一次你实际优化训练速度的经历(数据加载、模型重构、分布式策略等方面)。
答案:
我没有亲自跑线上的经历,只能用一个很典型的实战案例来说明完整思路:
场景:使用 PyTorch 训练一个中大型 Transformer 模型,初始版本每个 epoch 非常慢,GPU 利用率只有 40% 左右。
-
初步诊断:
-
用
nvidia-smi和 profiler(如torch.profiler)观察:- GPU 空闲时间很多;
- 前向/反向算子耗时还好,但每个 step 之间有明显间隙。
-
推断:数据加载/预处理成为瓶颈。
-
-
数据加载优化:
-
原来使用单进程数据加载、每次从磁盘读取小文件并做复杂的 Python 预处理。
-
改进:
- 使用
DataLoader(num_workers=N, pin_memory=True, prefetch_factor=2); - 将原本 on-the-fly 的重度预处理改为 离线预处理 + 二进制格式(如 mmap/LMDB/RecordIO);
- 使用
persistent_workers=True减少 worker 重启开销。
- 使用
-
结果:GPU 利用率从 40% → 75%。
-
-
模型结构与混合精度:
- 引入 FP16 混合精度(
torch.cuda.amp),显存占用下降,batch size 可以翻倍; - 同时保持 global batch size 一致,通过梯度累积调整;
- 适度调整 LayerNorm 的位置(pre-LN)提高稳定性。
- 结果:同样迭代数下,总训练时间又减少了不少。
- 引入 FP16 混合精度(
-
分布式策略:
- 单机多卡:使用 DDP 代替 DataParallel,减少 GIL/主进程开销;
- 多机:配置 NCCL / RDMA,减少 all-reduce 的通信开销,使用梯度累积减少同步频率;
- 对 embedding 层使用 sharding(简单模型并行),缓解显存压力。
-
最终效果:
- 同样的数据量和训练轮数下,总耗时减少到原来的 ~1/3;
- GPU 利用率较为均衡,集群资源利用率大幅提升。
这个流程比较有代表性:先看 GPU 是否忙 → 大多情况是 IO/数据问题 → 然后再考虑混合精度和分布式策略。
43、PaddlePaddle / TensorFlow 在工业界有哪些典型使用场景?你有接触或迁移经验吗?
答案:
-
PaddlePaddle:
-
由百度主导,国内工业界使用较多,特别是在:
- 搜索广告、推荐系统、NLP、CV 等内部业务;
- 开源模型库(PaddleNLP、PaddleDetection 等);
- 飞桨产业套件和 PaddleServing 等服务化组件。
-
在一些政企/国产化项目里也经常会遇到 Paddle 的生态。
-
-
TensorFlow:
-
早期在工业界占主导地位:
- 大量的图像识别、语音识别、推荐系统、CTR 模型都用 TF 建过。
- 在移动端推理(TensorFlow Lite)、服务器端推理(TF Serving)方面积累丰富。
-
目前在云服务、企业老项目、部分 AutoML/ML 平台中仍然大量存在。
-
-
迁移经验的一般模式(抽象):
-
从 TF → PyTorch:
- 先对齐数据预处理和损失函数;
- 再一一对照网络结构(Conv/BN/Linear/激活等)的参数;
- 利用小规模数据对比中间层输出和最终结果;
- 最后对齐训练策略(LR schedule、正则、dropout)。
-
从 Paddle → PyTorch 或反向:
- 类似步骤,重点是保证权重加载和算子语义一致(例如某些归一化或 embedding lookup 的默认行为)。
-
44、解释一下学习率预热(warmup)与学习率衰减(cosine、step 等)策略对训练的影响。
答案:
-
学习率预热(Warmup):
-
开始训练时,用一个较小的学习率,在若干 step/epoch 内逐步升到目标学习率。
-
原因:
- 随机初始化 + 大 batch + Adam 时,一开始梯度分布可能很不稳定,大 LR 容易导致 loss 爆炸。
- 预热阶段让参数/统计量慢慢“进入合理区间”,提高稳定性。
-
常见做法:
- linear warmup:从 0 → base_lr,持续 1k/5k/10k steps 等。
-
对大模型尤其重要(几乎必配)。
-
-
学习率衰减(Schedule):
-
Step Decay:
- 每隔固定 epoch 让 LR 乘一个衰减系数(如 0.1);
- 适合 CV/ResNet 等传统任务。
-
Cosine Decay:
- 学习率在训练过程中按 cos 曲线从 base_lr 慢慢降到接近 0;
- 优点:前期下降慢,后期慢慢收尾,整体更平滑,有助于收敛到更好的点。
-
Polynomial / Exponential 等:
- 根据具体任务选择。
-
-
综合影响:
-
Warmup + 合理衰减可以:
- 提高训练稳定性,减少初期梯度爆炸;
- 提升最终收敛效果和泛化性能。
-
对大模型(BERT/GPT 等)来说:linear warmup + cosine decay + AdamW 是一个非常典型的组合。
-
45、数据集非常大的情况下,你会如何设计数据加载与预处理流水线以避免 IO 成为瓶颈?
答案:
主要思路:让 GPU 始终有活干,不要让它等数据。
-
数据格式与存储:
-
避免大量小文件(每条样本一个小文件),改为:
- 采用二进制打包格式:如 TFRecord / LMDB / RecordIO / MindSpore 数据图等;
- 或者将文本预先 tokenize 后存为二进制数组。
-
存储在本地 NVMe / 高速网络存储(如对象存储 + 本地缓存)。
-
-
流水线并行:
-
数据加载、预处理、训练三者并行:
- 多进程/多线程数据加载;
- 预处理放在 worker 进程里完成;
- 主进程只做 forward/backward。
-
PyTorch:
DataLoader(num_workers > 0, pin_memory=True, prefetch_factor=k, persistent_workers=True)。
-
MindSpore:
- 使用其**数据图(data graph)**机制,在 Python 外部定义数据处理图,由框架内部并行执行、预取和缓存。([Medium][8])
-
-
缓存与复用:
- 对计算昂贵但可重复使用的预处理(如 BPE 分词)尽量离线化;
- 使用本地缓存(如第一次跑时 cache,后续直接读取)。
-
分布式数据加载:
-
多机多卡训练时:
- 每个 rank 使用
DistributedSampler或等价机制加载自己那一份数据 shard; - 保证全局上样本不重复/覆盖均匀。
- 每个 rank 使用
-
使用数据切片(sharding)和 shuffle buffer,让每轮数据顺序不同但又不会跨机重复筹载。
-
-
监控与调优:
-
用 profiler 看:
- 每个 step GPU 等待时间;
- DataLoader 开销;
-
调整
num_workers、批大小、预取大小,直到 GPU 利用率接近饱和但 CPU 不成为新的瓶颈。
-
46、如何实现可复现的训练(随机种子、数据顺序、分布式环境)?实际中有哪些难点?
答案:
-
基本操作:
-
固定所有随机源:
-
Python:
random.seed(seed) -
NumPy:
np.random.seed(seed) -
PyTorch:
torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)
-
-
设置确定性选项:
torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False
-
数据加载:
- DataLoader 中的
shuffle受种子控制; - 多进程 worker 中,使用
worker_init_fn传入确定性的子种子。
- DataLoader 中的
-
保存/恢复状态:
- 模型参数;
- 优化器状态;
- 学习率调度器状态;
- 随机数生成器状态(
torch.get_rng_state()等)。
-
-
分布式环境:
- 每个 rank 用不同但可推导的 seed(如
base_seed + rank); - 确保
DistributedSampler的set_epoch在每个 epoch 一致地调用; - 某些集体通信操作可能有非确定性实现,需要显式选择 deterministic backend(如某些 NCCL 算子)。
- 每个 rank 用不同但可推导的 seed(如
-
实际难点:
- 某些 GPU 算子天生有非确定实现(如原子加、某些 conv/cudnn 算法);
- 分布式训练中,通信和线程调度可能轻微打乱顺序;
- 跨版本(CUDA/cuDNN/驱动/框架)升级后,同样的种子也很难做 bit-level 复现;
- IO 层面:网络抖动、文件系统缓存等也会带来轻微扰动。
一般工程实践:追求“统计意义上的复现”(多次训练结果指标差异很小),而不是比特级完全一致。
47、你如何评估一个训练好的模型是否过拟合或欠拟合?会采取哪些措施来改善?
答案:
-
判断过拟合 / 欠拟合:
-
典型看法:
-
欠拟合:
- 训练集上的 loss 仍然很高,准确率/指标不理想;
- 验证集表现也很差;
- 说明模型容量不足 / 训练不够 / 特征不够。
-
过拟合:
- 训练 loss 很低甚至接近 0;
- 验证 loss 明显升高、验证指标明显较训练差;
- 说明模型在记忆训练集而没学到通用模式。
-
-
-
改善欠拟合:
-
增强模型表达能力:
- 加深/加宽网络;
- 引入更强的模型结构(如 CNN 更大、Transformer 更多层)。
-
训练更久、调大学习率或更好的 LR schedule;
-
提升特征质量:
- 更好的预处理、增加有用特征、采用预训练模型等。
-
-
改善过拟合:
-
数据层面:
- 增加训练数据量;
- 数据增强(图像增强、文本扰动等)。
-
模型层面:
-
减小模型容量;
-
使用正则化:
- L2 正则 / weight decay;
- dropout / label smoothing;
- early stopping(验证集性能不再提升就停止训练)。
-
-
训练策略:
- 更合理的 LR schedule;
- 交叉验证确保评估稳定。
-
48、请说明 Transformer 的核心结构(自注意力、多头注意力、残差连接等)。
答案:
-
整体结构:
-
编码器/解码器叠加若干层,每层主要包括:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈网络(Feed-Forward Network, FFN)
- 残差连接 + 归一化(LayerNorm/RMSNorm)
- 对解码器还有交叉注意力(Encoder-Decoder Attention)。
-
-
自注意力(Self-Attention):
-
对输入序列 (X = [x_1, …, x_n]):
- 通过线性变换得到 Query/Key/Value:
(Q = X W_Q),(K = X W_K),(V = X W_V)。 - 对每个位置计算与其他位置的相关性:
(\mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^\top}{\sqrt{d_k}})V) - 自注意力可以让每个位置“看到”整个序列的信息(全局依赖)。
- 通过线性变换得到 Query/Key/Value:
-
-
多头注意力(Multi-Head Attention):
-
将 Q/K/V 在隐藏维度上拆成多个“头”,每个头用不同的线性变换:
- 每个头关注不同的子空间特征;
- 所有头的输出 concat 后再线性映射回原维度。
-
能增强模型表达能力,让注意力从不同视角捕捉关系。
-
-
前馈网络(FFN):
-
对每个位置独立地通过一个两层(或更多层)MLP:
- 典型为
Linear -> 激活(GELU/ReLU) -> Linear; - 在 Transformer 中通常隐层维度比 d_model 大(如 4 倍)。
- 典型为
-
-
残差连接 + 归一化:
-
每个子层(MHA / FFN)都用残差:
x = x + sublayer(x);- 再做
LayerNorm(x)(pre-LN / post-LN 方案略有不同)。
-
作用:
- 缓解梯度消失;
- 让训练更加稳定,允许更深的网络。
-
-
位置编码(Positional Encoding):
-
因自注意力对序列位置没有偏好,需要显式注入位置信息:
- 经典 Transformer 用固定的正弦/余弦位置编码;
- LLM 多用可学习的位置编码 / RoPE(旋转位置编码)等。
-
49、在实际训练过程中,你如何监控与调试 Loss 曲线不收敛或震荡的问题?
答案:
-
先看现象:
- loss 一直很大,不怎么下降 → 可能学习率过小 / 模型容量不足 / 数据有问题。
- loss 一开始就 NaN / inf → 学习率过大 / 数值不稳定(比如 log(0)、除以 0)。
- loss 大幅震荡 → 学习率太大、优化器超参数不合适、梯度爆炸。
-
常规排查步骤:
-
检查数据与标签:
- 随机打印一批样本,看输入/标签是否正常(有没有大量异常值、全 0、全 1 等)。
- 检查是否搞错任务(比如分类标签没 one-hot 却当回归用了)。
-
检查模型输出与 loss:
- 用一小批数据跑几步,看输出是否在合理范围;
- 有无明显数值异常(非常大的值、NaN)。
-
降低复杂度做 sanity check:
-
在极小的子集(如 100 条数据)上训练:
- 如果模型在这个子集上的 loss 都下不去,说明实现有问题。
-
降低网络深度、使用小模型测试。
-
-
调整学习率:
- 大多数不收敛问题都可以先尝试降低 LR;
- 使用 learning rate finder(逐步增大 LR 看哪段区间 loss 最快降低)。
-
监控梯度与参数:
- 记录梯度范数、参数范数;
- 看是否出现梯度爆炸/消失;
- 必要时启用梯度裁剪。
-
-
工具与习惯:
-
使用 TensorBoard / WandB 等记录:
- 训练/验证 loss 曲线;
- 指标(accuracy/F1/perplexity);
- 学习率随时间变化;
- 梯度 norm。
-
如果使用混合精度:
- 监控 GradScaler 的缩放因子是否频繁回退(说明数值经常溢出)。
-
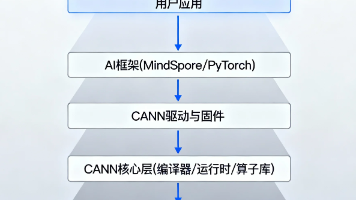
50、谈谈你对 MindSpore 在国产算力平台(如昇腾)上的适配与优势的理解。
答案:
结合官方公开信息,可以概括为几层:
-
软硬一体设计:
-
MindSpore 是华为主导的 AI 框架,与其 Ascend 昇腾 AI 处理器和全栈解决方案深度绑定:
- Ascend 芯片 + Atlas 硬件 + CANN(底层算子库) + MindSpore 框架 + 上层平台(ModelArts 等)。([Gitee][9])
-
-
针对昇腾的图编译优化:
-
在 Graph 模式下:
- 将完整计算图下沉(whole graph sink)到 Ascend 侧执行;
- 利用 AKG 等图内核融合技术自动生成高性能算子,减少 host–device 之间的调度开销。([mindspore.cn][5])
-
这类“靠近芯片”的设计,可以大幅减少同步等待、提高带宽利用率。
-
-
自动并行和大模型支持:
-
MindSpore 提供自动并行(数据并行 + 算子并行 + 混合并行)的编程接口:
- 对大模型训练,在昇腾集群上较容易做多维度并行和切分;
- 减少用户手写通信逻辑的负担。([mindspore.cn][4])
-
-
国产化与产业生态:
-
在国产算力推广场景(政企、运营商、金融等),
- 昇腾 + MindSpore 的组合提供了从芯片到框架、再到工具链的一整套国产方案;
- 在一些国产化要求较高的项目中,更容易通过合规与生态适配。
-
-
实践上的注意点:
-
虽然 MindSpore 也支持 GPU/CPU,但要真正发挥优势,需要:
- 对 Ascend 的内存层次、算子特性有一定了解;
- 利用其推荐的 Graph 模式、自动并行和数据 pipeline 机制;
- 注意用 MindSpore 提供的 API 而不是在关键路径里写大量纯 Python 逻辑。
-

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)