
手把手教你写昇腾Matmul算子:功能实现与性能优化全流程记录
先跑通Demo:不要上来就改代码,先照着图1里的开源样例把流程跑通。理解数据流:画出数据在各级缓存流动的图(GM->L1->L0)。用好工具:MindStudio的Timeline视图是性能优化的唯一依据,凭感觉优化都是扯淡。Matmul算子开发确实难,但当你看到Cube单元的利用率从20%飙升到90%的那一刻,那种成就感是无与伦比的。🔥 2025昇腾CANN训练营·第二季 报名开启!别让你的A
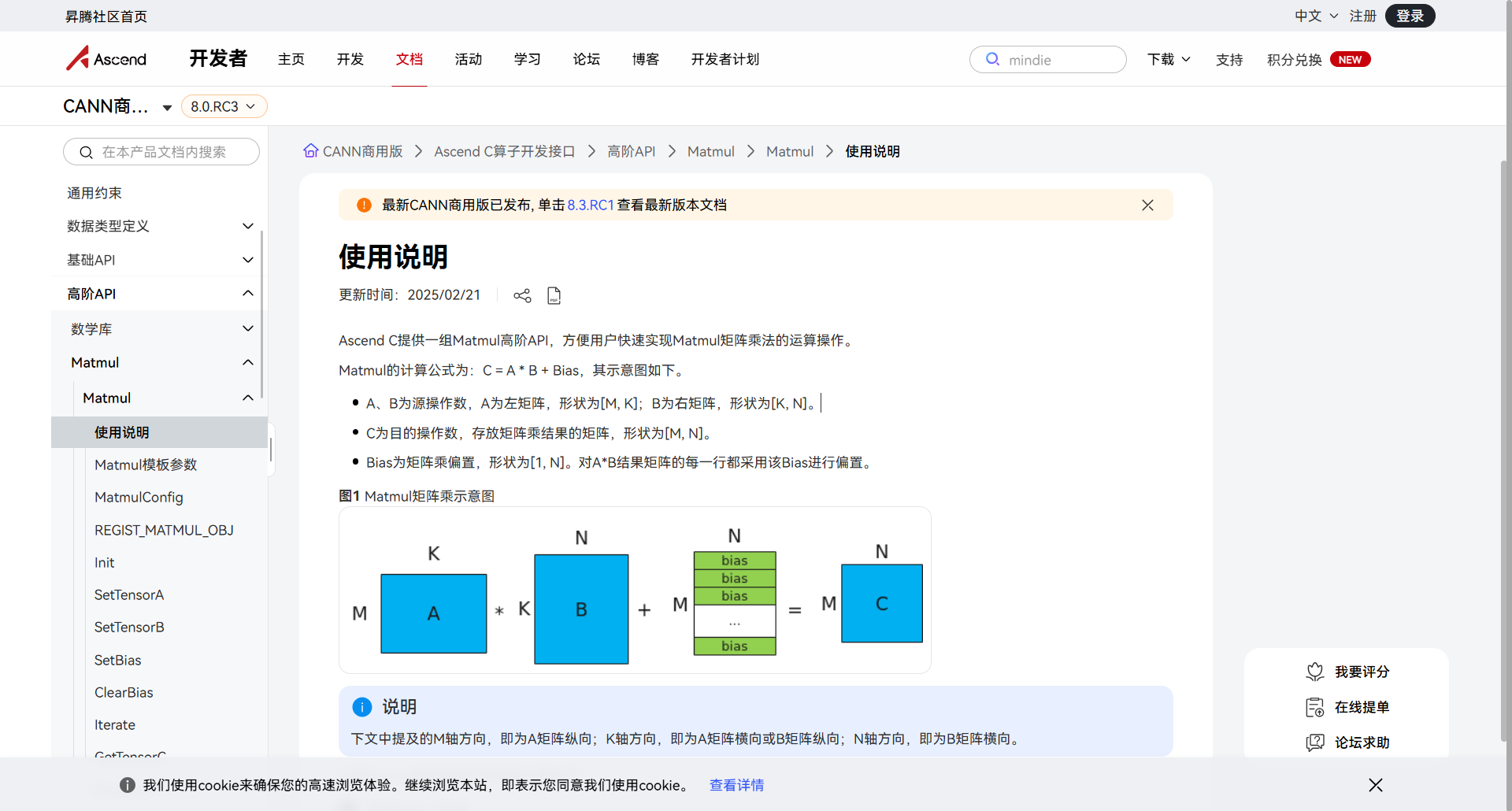
前言:矩阵乘法,没你想得那么简单
在深度学习里,90%的计算量都在矩阵乘法(Matmul)上。我以前觉得这东西不就是 C = A * B 吗?三层循环 for 一写不就完了?
直到参加了CANN训练营,开始接触昇腾Ascend C的Cube算子开发,我才发现自己太天真了。
在NPU上写Matmul,不仅是逻辑问题,更是对内存架构、数据搬运和指令流水线的极致考验。
这篇长文,就是我这半个月死磕Matmul算子的全流程记录。从功能跑到性能优化,把那些文档里没写透的“潜规则”一次性讲清楚。
第一阶段:理解硬件 —— Cube单元的“怪脾气”
在写代码前,必须先搞懂图3课程里反复强调的Cube Unit。
不同于Vector单元处理一维向量,Cube单元是专门吃“块”的。
1.1 独特的数据流
普通算子是 GM -> UB -> GM。
但Matmul算子有一条专属的VIP通道:Global Memory -> L1 Buffer -> L0A/L0B Buffer -> Cube计算单元 -> L0C Buffer -> Global Memory。
踩坑点:
我最开始把数据全都搬到UB(Unified Buffer)里想做矩阵乘,结果编译报错。记住:Cube计算必须走L1和L0缓存,UB在这里只是配角(通常用于后续的Bias加法或ReLU)。
1.2 令人头大的分形格式(Fractal Format)
这是新手最大的拦路虎。
在Host侧,矩阵是行优先(Row Major)存储的。
但在Device侧,为了迎合Cube单元的物理阵列结构,数据必须重排成分形格式(5D数据)。
好在Ascend C的高阶API帮我们屏蔽了大部分转换细节,但你心里必须要有这个概念,否则Debug时看到内存里的乱码会崩溃。
📷 图片生成提示 1:
画面描述: 一个动态的数据重排示意图。左侧是一个规整的二维大矩阵(A矩阵)。中间经过一个漏斗(ND2NZ指令)。右侧变成了一堆像俄罗斯方块一样的小Z字形(Fractal Z)数据块,整齐地填入Cube单元的卡槽中。
用途: 形象解释为什么需要特殊的数据格式转换。
第二阶段:功能实现 —— 高阶API的“真香”定律
图3课程标题是“手把手教你”,其实教的就是Matmul高阶API。
如果不使用高阶API,你需要手动管理L1到L0的数据搬运,那代码量得几千行起步。
2.1 核心代码四步走
利用 Matmul 模板类,实现一个基础Matmul算子只需要四步:
-
注册与初始化:
// 注册Matmul实例,绑定Tiling参数 REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), matmulObj, &tiling); matmulObj.Init(&tiling); -
设置数据(填弹):
告诉算子,A矩阵和B矩阵在GM的哪里。matmulObj.SetTensorA(gm_a); matmulObj.SetTensorB(gm_b); -
执行计算(开火):
这是最神奇的一行代码。它自动完成了GM->L1->L0->Cube->L0C的所有搬运和计算!matmulObj.IterateAll(gm_c); // 算出结果并写回gm_c // 或者分步走: // matmulObj.Iterate(); // matmulObj.GetTensorC(ub_c); // 如果还要做后处理(如ReLU) -
后处理(可选):
如果需要加Bias或者激活函数,这时候才轮到Vector单元出场,在UB里处理ub_c。
第三阶段:性能优化 —— 这里的差距是10倍
功能跑通了,但看Profiling数据,性能惨不忍睹。图3的后半部分重点就在讲**“性能优化”**。这也是大神和小白的分水岭。
3.1 Double Buffer(双缓冲)必须开
现象: 查看Timeline发现,Cube单元在计算时,搬运单元在休息;搬运时,计算在休息。这是极大的浪费。
优化: 在Host侧Tiling设置时,或者在Kernel侧Init时,开启双缓冲。
原理: 准备两块L1 Buffer。
- 当Cube在吃第一块肉(计算)时;
- DMA已经在锅里煮第二块肉(搬运)了。
这样Cube单元就永远不会饿肚子。
3.2 Tiling策略的艺术
Tiling(切分) 是Matmul性能的灵魂。
- 切大了:L1/L0放不下,爆内存。
- 切小了:搬运次数太多,指令开销把性能吃光了。
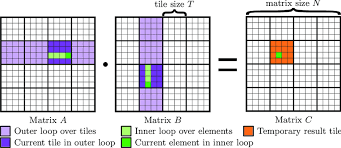
实战心得:
不要自己在Kernel里瞎算!一定要利用Host侧的 MatmulTiling 库。它会根据你的Shape大小和芯片型号,自动算出最优的 baseM, baseN, baseK。
注意: 还要考虑**尾块(Tail Block)**的处理。如果矩阵大小不是16的倍数,Tiling策略没弄好,很容易导致计算结果错位。
第四阶段:调试与避坑 —— 图4里的“常见错误”我都犯了
这一段是我的血泪Debug记录,对应图4的“常见错误解析”和图1的“MindStudio调试”。
4.1 精度丢失之谜
现象: 算出来的结果和PyTorch CPU版对比,偏差很大。
原因: 累加器溢出。
解决: 在Matmul模板参数里,务必将累加类型设置为 float32(即使输入是 float16)。
// 模板参数里指定
typename CFgType = MatmulConfig<code_block, float, float> // 中间用float32
4.2 死锁卡死
现象: 程序挂起,不报错也不退出。
原因: IterateAll 和手动 GetTensorC 混用,或者Queue没有配对使用。
调试方法: 使用 MindStudio 的模拟器功能。
不要盲猜!在模拟器里,我可以暂停程序,查看 L0C 里的中间结果。我曾经通过这个方法发现,原来是我的Bias数据没搬进UB,导致加了一堆0。
总结:从入门到精通的路径
回顾从无从下手到写出一个高性能Matmul算子,我的建议是:
- 先跑通Demo:不要上来就改代码,先照着图1里的开源样例把流程跑通。
- 理解数据流:画出数据在各级缓存流动的图(GM->L1->L0)。
- 用好工具:MindStudio的Timeline视图是性能优化的唯一依据,凭感觉优化都是扯淡。
Matmul算子开发确实难,但当你看到Cube单元的利用率从20%飙升到90%的那一刻,那种成就感是无与伦比的。
🔥 2025昇腾CANN训练营·第二季 报名开启!
别让你的AI模型只跑在黑盒子里,来这里,亲手拆解它!
👇 扫码/点击链接,硬核玩家速来集合:
https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)