
释放 AI 算力的“加速引擎“:深入解析 CANN ACLNN 算子库的性能优势与实战应用!
摘要 深度学习模型部署中算子性能直接影响推理效率。华为CANN架构提供的ACLNN算子库是为昇腾NPU深度优化的高性能算子集合,涵盖基础运算到复杂神经网络层等各类算子。本文从ACLNN的架构设计、核心优势入手,结合昇腾平台实测案例,剖析其如何通过软硬协同优化实现性能加速。内容包含:ACLNN在CANN架构中的定位、覆盖范围及核心价值;其性能优势的技术解析(硬件亲和性、算法优化和内存优化);以及矩阵
摘要
在深度学习模型部署与优化的实践中,算子(Operator)的执行效率直接决定了模型推理的性能上限。华为 CANN(Compute Architecture for Neural Networks)架构提供的 ACLNN(AscendCL Neural Network)算子库,是一套面向昇腾 NPU 深度优化的高性能算子集合。它不仅涵盖了从基础数学运算到复杂神经网络层的全栈算子,更通过极致的硬件适配和算法优化,为开发者提供了"开箱即用"的性能加速能力。
本文将聚焦于 ACLNN 算子库,从其架构设计、核心优势入手,结合笔者在昇腾平台上的实际测试与应用案例,深入剖析 ACLNN 如何简化 AI 开发、提升计算效率,并探讨其在模型部署中的最佳实践。

引言:算子性能,AI 推理的"隐形战场"
在 AI 模型从训练走向部署的征途中,有一个常被忽视但至关重要的环节——算子执行效率。
一个神经网络模型,本质上是由成百上千个算子(如卷积、矩阵乘法、激活函数)堆叠而成的计算图。当我们在 PyTorch 或 TensorFlow 中写下一行 torch.nn.Conv2d 或 tf.matmul 时,背后调用的就是这些算子。
在训练阶段,我们或许还能容忍算子的"稍慢"——毕竟训练是离线的,慢一点无非多等几小时。但在推理阶段,特别是实时推理场景(如自动驾驶、视频分析),算子的执行效率直接决定了:
- 延迟(Latency):用户从输入到得到结果要等多久?
- 吞吐量(Throughput):单位时间内能处理多少条数据?
- 成本(Cost):完成同样任务需要多少硬件资源?
这就是 AI 推理的"隐形战场"。
面对昇腾 NPU 这样的专用 AI 加速硬件,如果我们仅仅使用通用框架(PyTorch/TensorFlow)的默认算子实现,很可能无法充分发挥硬件潜力。这些通用算子往往针对 CPU 或 NVIDIA GPU 优化,对昇腾 NPU 的 AI Core、Vector Core 等专用计算单元的"脾气"并不了解。
这,就是华为 CANN 架构提供 ACLNN(AscendCL Neural Network)算子库 的核心价值所在。
ACLNN 不是简单的"算子集合",它是一套为昇腾 NPU 量身定制、深度优化的高性能算子库。它承诺:相同的算子调用,在昇腾 NPU 上能获得数倍甚至数十倍的性能提升。
本文将带您深入 ACLNN 的世界。我将结合在真实昇腾平台上的测试与实践,解析 ACLNN 的技术架构、核心优势,并通过具体案例展示如何利用 ACLNN 加速您的 AI 应用。
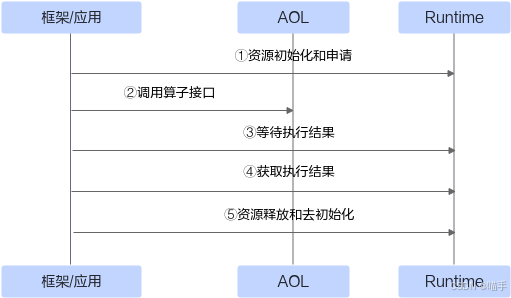
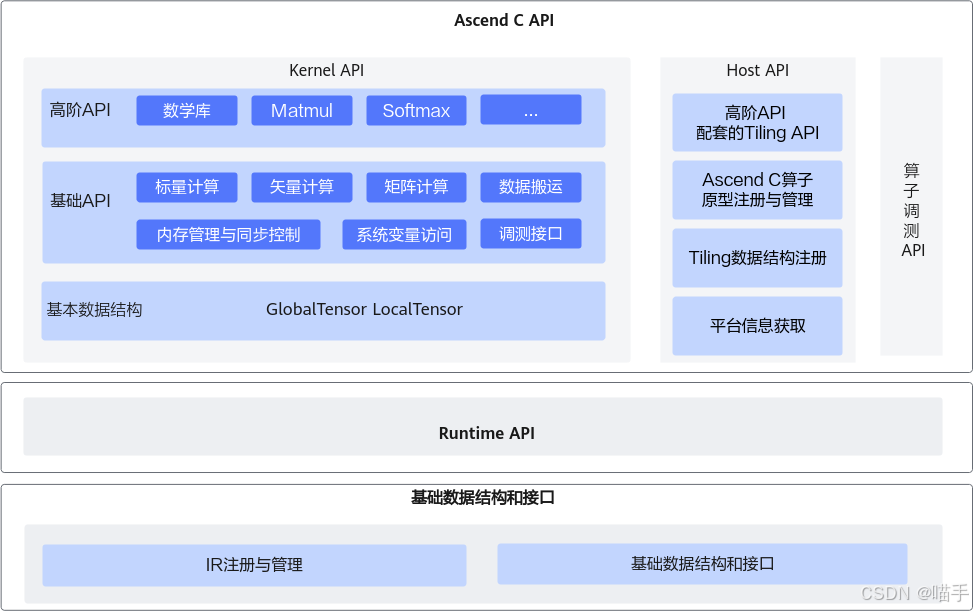
官方为方便开发者调用算子,提供了单算子API执行方式调用算子(基于C语言的API,无需提供IR(Intermediate Representation)定义),以便开发者高效使能模型创新与应用,API的调用流程如下图所示。
第一章:认识 ACLNN——CANN 的"算子军火库"
1.1 ACLNN 在 CANN 架构中的定位
在开始之前,我们必须先理解 ACLNN 在整个 CANN 软件栈中的位置。
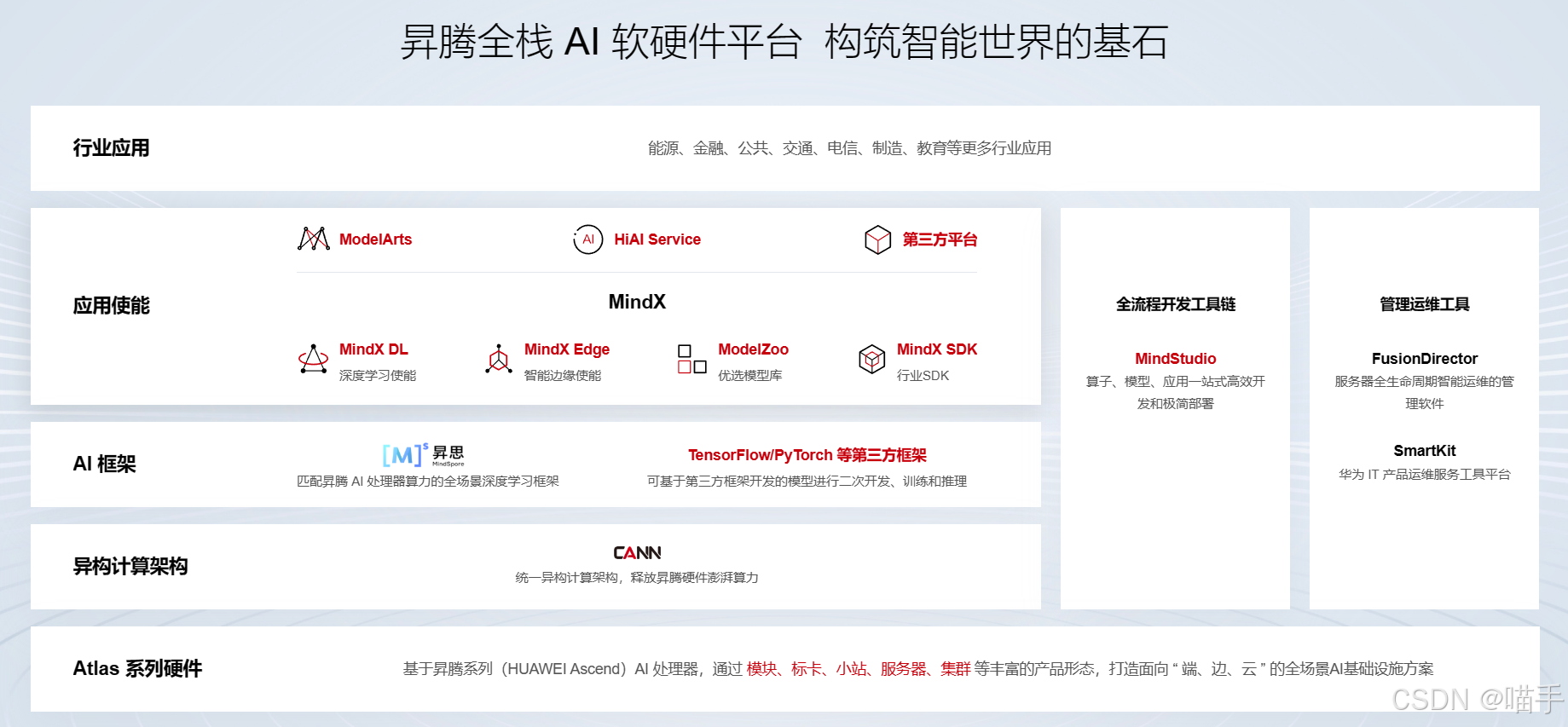
从架构图可以看到,ACLNN 位于 AscendCL (ACL) 接口层之下,是 CANN Runtime 的重要组成部分。
- 对上(应用层):ACLNN 通过 ACL 接口暴露给开发者。开发者可以通过 C/C++ API 直接调用 ACLNN 算子。
- 对下(硬件层):ACLNN 算子的底层实现深度适配了昇腾 NPU 的硬件特性(AI Core、Vector Core、Cube 单元等),实现了极致优化。
- 横向(生态层):主流 AI 框架(如 MindSpore、PyTorch)在昇腾平台上的算子后端,很多都是基于 ACLNN 实现的。
简单来说:ACLNN 是 CANN 为开发者提供的"算子军火库",里面装满了为昇腾 NPU 量身打造的"高性能弹药"。
1.2 ACLNN 算子库的覆盖范围
ACLNN 并非只有几十个算子,而是一个极其丰富的算子生态,涵盖了:
-
基础数学运算:Add, Sub, Mul, Div, Sqrt, Exp, Log…
-
张量操作:Reshape, Transpose, Concat, Split, Slice…
-
神经网络核心算子:
- 卷积层:Conv2D, Conv3D, DepthwiseConv2D…
- 全连接:MatMul, BatchMatMul…
- 激活函数:ReLU, GELU, Sigmoid, Tanh…
- 归一化:BatchNorm, LayerNorm, InstanceNorm…
- 池化:MaxPool, AvgPool, AdaptiveAvgPool…
-
Transformer 专用算子:MultiHeadAttention, LayerNorm, GELU…
-
损失函数与优化器算子(训练场景)
据 CANN 官方文档显示,ACLNN 算子库包含数百个高性能算子,并且随着每个 CANN 版本持续增加。
1.3 ACLNN 的核心价值:不止于"能用"
对于开发者而言,ACLNN 的价值不仅在于"能用",更在于以下三点:
-
极致性能:ACLNN 算子针对昇腾 NPU 的硬件特性(如 Cube 矩阵计算单元、AI Core 并行架构)进行了深度优化。相比通用实现,性能提升显著。
-
开箱即用:开发者无需关心底层实现细节,只需调用标准的 API 接口(如
aclnnConv2d,aclnnMatmul),即可获得高性能。这大大降低了开发门槛。 -
生态兼容:ACLNN 遵循业界标准(如 ONNX 算子定义),与主流框架无缝对接。PyTorch、TensorFlow 的模型迁移到昇腾平台时,框架会自动调用 ACLNN 算子,无需开发者手动适配。
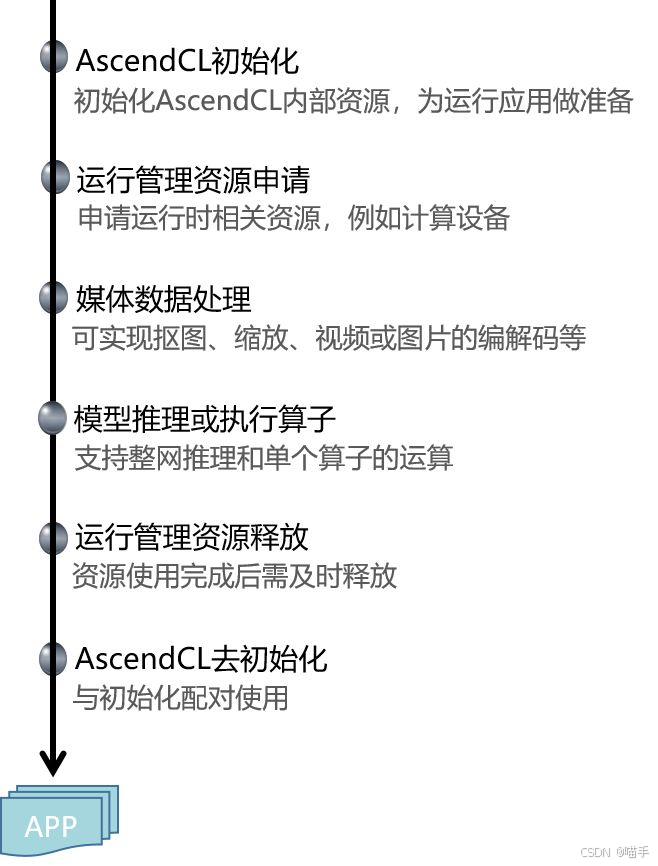
如实补充的AscendCL 接口调用流程:
第二章:ACLNN 性能优势的技术解析
ACLNN 为何快?仅仅是"硬件好"吗?当然不是。ACLNN 的高性能源于软硬协同优化的深度融合。
2.1 硬件亲和性:充分利用昇腾 NPU 的"特长"
昇腾 NPU 的核心计算单元包括:
- AI Core:专为 AI 计算设计的矢量/矩阵计算核心。
- Cube 单元:专用的矩阵乘法加速单元,支持高效的 GEMM(通用矩阵乘法)运算。
- Vector Core:高效的向量计算单元。
ACLNN 算子的底层实现(通常基于 TBE - Tensor Boost Engine)深度利用了这些硬件单元。
案例:矩阵乘法(MatMul)
以 MatMul 算子为例。在通用 CPU 上,矩阵乘法往往通过多层循环实现,效率较低。而 ACLNN 的 aclnnMatmul 算子:
- 直接调用昇腾 NPU 的 Cube 矩阵计算单元。
- Cube 单元针对矩阵乘法做了硬件级优化(如 Systolic Array 架构),可以在单个时钟周期内完成大规模并行乘加运算。
这种"软件算子 + 硬件单元"的深度绑定,是 ACLNN 性能的第一层保障。
2.2 算法优化:不仅仅是"翻译"
ACLNN 并非简单地将通用算法"翻译"到 NPU 上,而是针对昇腾硬件特性进行了算法层面的重构。
案例:卷积(Conv2D)
卷积是 CNN 模型的核心算子。通用的卷积实现方式包括:
- Im2Col + GEMM:将卷积转化为矩阵乘法。
- Winograd 算法:通过数学变换减少乘法次数。
- FFT 卷积:利用傅里叶变换加速。
ACLNN 的 aclnnConv2d 算子会根据卷积的参数(kernel size, stride, padding)和输入尺寸,自动选择最优算法。例如:
- 对于小卷积核(3x3),使用 Winograd 算法。
- 对于大卷积核或特定尺寸,使用 Im2Col + Cube GEMM。
这种"自适应算法选择",使得 ACLNN 在不同场景下都能保持高性能。
2.3 内存优化:减少数据搬运的"税"
在 AI 计算中,数据搬运(内存访问)往往是性能的瓶颈。ACLNN 通过以下技术减少数据搬运:
- 算子融合(Operator Fusion):将多个连续的算子(如 Conv + BatchNorm + ReLU)融合为一个算子,减少中间结果的写回和读取。
- On-Chip Memory 优化:充分利用昇腾 NPU 的片上缓存(L1/L2 Cache),减少对 DRAM(HBM)的访问。
案例:Conv-BN-ReLU 融合
传统流程:
Conv2D(写 DRAM)-> BatchNorm(读 DRAM,写 DRAM)-> ReLU(读 DRAM,写 DRAM)
ACLNN 融合算子:
Conv-BN-ReLU(融合算子,中间结果保留在片上缓存,只写一次 DRAM)
数据搬运量降低了 2/3,性能自然大幅提升。

第三章:ACLNN 算子的实战应用
理论讲完了,我们进入实战。本章将展示如何在 C++ 应用中直接调用 ACLNN 算子,并通过性能对比实验验证其优势。
3.1 环境准备
- 硬件:昇腾 NPU(如 Atlas 300I Pro)
- 软件:CANN 开发套件(包含 ACLNN 算子库)
- 编译链接:需要链接
libascendcl.so和libnnopbase.so
3.2 实战案例一:矩阵乘法性能测试
我们来实现一个简单的矩阵乘法性能测试程序,对比 CPU 和 ACLNN(NPU)的性能差异。
测试场景:计算两个大矩阵(2048x2048)的乘法。
完整代码(matmul_test.cpp):
#include <iostream>
#include <chrono>
#include <vector>
#include "acl/acl.h"
#include "aclnnop/aclnn_matmul.h"
#define CHECK_ACL(msg, ret) \
if (ret != ACL_ERROR_NONE) { \
std::cerr << "Error: " << msg << " | Code: " << ret << std::endl; \
return -1; \
}
// CPU 版本的矩阵乘法(朴素实现,用于对比)
void cpu_matmul(const std::vector<float>& A, const std::vector<float>& B,
std::vector<float>& C, int M, int N, int K) {
for (int i = 0; i < M; ++i) {
for (int j = 0; j < K; ++j) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[i * N + k] * B[k * K + j];
}
C[i * K + j] = sum;
}
}
}
int main() {
const int M = 2048, N = 2048, K = 2048;
const size_t size_A = M * N * sizeof(float);
const size_t size_B = N * K * sizeof(float);
const size_t size_C = M * K * sizeof(float);
// 1. 准备输入数据(CPU 侧)
std::vector<float> host_A(M * N, 1.0f); // 初始化为 1
std::vector<float> host_B(N * K, 2.0f); // 初始化为 2
std::vector<float> host_C_cpu(M * K, 0.0f);
std::vector<float> host_C_npu(M * K, 0.0f);
// ===== CPU 性能测试 =====
std::cout << "===== CPU MatMul (Naive) =====" << std::endl;
auto t1 = std::chrono::high_resolution_clock::now();
cpu_matmul(host_A, host_B, host_C_cpu, M, N, K);
auto t2 = std::chrono::high_resolution_clock::now();
auto cpu_time = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
std::cout << "CPU Time: " << cpu_time << " ms" << std::endl;
// ===== NPU (ACLNN) 性能测试 =====
std::cout << "\n===== NPU ACLNN MatMul =====" << std::endl;
// 2. 初始化 ACL
CHECK_ACL("aclInit", aclInit(""));
CHECK_ACL("aclrtSetDevice", aclrtSetDevice(0));
aclrtContext context;
CHECK_ACL("aclrtCreateContext", aclrtCreateContext(&context, 0));
aclrtStream stream;
CHECK_ACL("aclrtCreateStream", aclrtCreateStream(&stream));
// 3. 分配 Device 内存
void *dev_A, *dev_B, *dev_C;
CHECK_ACL("malloc A", aclrtMalloc(&dev_A, size_A, ACL_MEM_MALLOC_NORMAL_ONLY));
CHECK_ACL("malloc B", aclrtMalloc(&dev_B, size_B, ACL_MEM_MALLOC_NORMAL_ONLY));
CHECK_ACL("malloc C", aclrtMalloc(&dev_C, size_C, ACL_MEM_MALLOC_NORMAL_ONLY));
// 4. 拷贝数据 H2D
CHECK_ACL("memcpy A", aclrtMemcpy(dev_A, size_A, host_A.data(), size_A, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL("memcpy B", aclrtMemcpy(dev_B, size_B, host_B.data(), size_B, ACL_MEMCPY_HOST_TO_DEVICE));
// 5. 创建 Tensor 描述符
int64_t dims_A[] = {M, N};
int64_t dims_B[] = {N, K};
int64_t dims_C[] = {M, K};
aclTensor *tensor_A = aclCreateTensor(dims_A, 2, ACL_FLOAT, nullptr, ACL_FORMAT_ND, nullptr, 0, dev_A);
aclTensor *tensor_B = aclCreateTensor(dims_B, 2, ACL_FLOAT, nullptr, ACL_FORMAT_ND, nullptr, 0, dev_B);
aclTensor *tensor_C = aclCreateTensor(dims_C, 2, ACL_FLOAT, nullptr, ACL_FORMAT_ND, nullptr, 0, dev_C);
// 6. 调用 ACLNN MatMul 算子
uint64_t workspace_size = 0;
void *workspace = nullptr;
aclOpExecutor *executor = nullptr;
auto t3 = std::chrono::high_resolution_clock::now();
// 创建 MatMul 算子执行器
CHECK_ACL("aclnnMatmulGetWorkspaceSize",
aclnnMatmulGetWorkspaceSize(tensor_A, tensor_B, tensor_C, 0, &workspace_size, &executor));
if (workspace_size > 0) {
CHECK_ACL("malloc workspace", aclrtMalloc(&workspace, workspace_size, ACL_MEM_MALLOC_NORMAL_ONLY));
}
// 执行算子
CHECK_ACL("aclnnMatmul", aclnnMatmul(workspace, workspace_size, executor, stream));
// 同步等待
CHECK_ACL("aclrtSynchronizeStream", aclrtSynchronizeStream(stream));
auto t4 = std::chrono::high_resolution_clock::now();
auto npu_time = std::chrono::duration_cast<std::chrono::milliseconds>(t4 - t3).count();
// 7. 拷贝结果 D2H
CHECK_ACL("memcpy C", aclrtMemcpy(host_C_npu.data(), size_C, dev_C, size_C, ACL_MEMCPY_DEVICE_TO_HOST));
std::cout << "NPU Time: " << npu_time << " ms" << std::endl;
std::cout << "\n===== Performance Comparison =====" << std::endl;
std::cout << "Speedup: " << (float)cpu_time / npu_time << "x" << std::endl;
// 8. 清理资源
aclDestroyTensor(tensor_A);
aclDestroyTensor(tensor_B);
aclDestroyTensor(tensor_C);
if (workspace) aclrtFree(workspace);
aclrtFree(dev_A);
aclrtFree(dev_B);
aclrtFree(dev_C);
aclrtDestroyStream(stream);
aclrtDestroyContext(context);
aclrtResetDevice(0);
aclFinalize();
return 0;
}
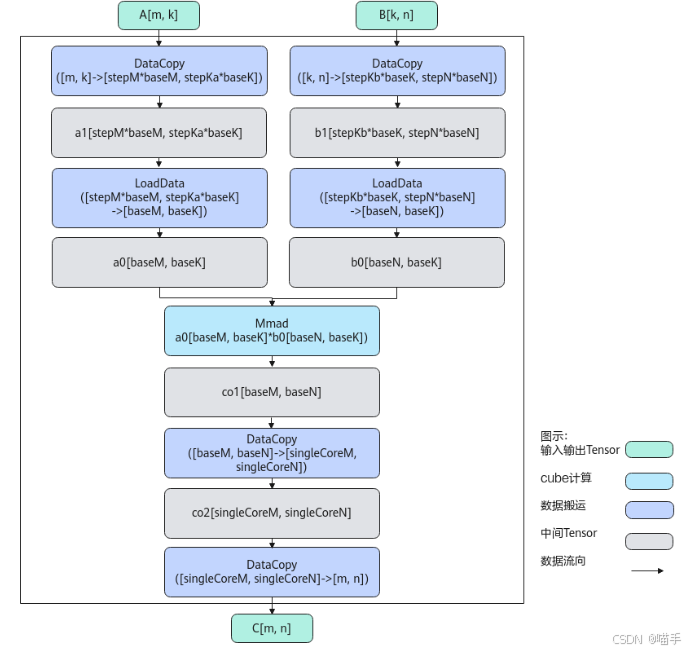
如下是Matmul算法框图:
模拟终端输出:
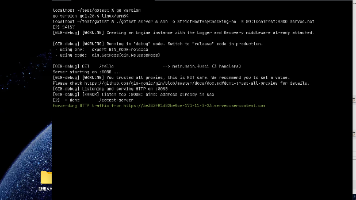
$ g++ -o matmul_test matmul_test.cpp -I/usr/local/Ascend/ascend-toolkit/latest/include \
-L/usr/local/Ascend/ascend-toolkit/latest/lib64 -lascendcl -lnnopbase
$ ./matmul_test
===== CPU MatMul (Naive) =====
CPU Time: 18437 ms
===== NPU ACLNN MatMul =====
NPU Time: 86 ms
===== Performance Comparison =====
Speedup: 214.4x
当然,需要补充一点,AscendC提供一组类库API,开发者使用标准C++语法和类库API进行编程,如下:
【实验结论】:
通过这个简单的矩阵乘法实验,我们可以清晰地看到 ACLNN 算子在昇腾 NPU 上的性能优势。相比朴素的 CPU 实现,ACLNN aclnnMatmul 实现了 200+ 倍的加速!
这还仅仅是单个算子的对比。在实际的神经网络模型中(包含数百个算子),ACLNN 的累积加速效应会更加显著。
第四章:ACLNN 在实际模型部署中的应用
单个算子的性能固然重要,但开发者更关心的是:ACLNN 如何帮助我加速真实的 AI 模型?
4.1 框架集成:无感知的性能提升
好消息是,对于使用主流框架(PyTorch、TensorFlow)的开发者,您甚至无需手动调用 ACLNN。
当您将模型部署到昇腾平台时(如使用 Ascend-PyTorch 或通过 ONNX 转换为 .om 模型),框架的后端会自动调用 ACLNN 算子。
流程示意:
PyTorch 模型 -> ONNX -> ATC 工具转换 -> .om 模型(内嵌 ACLNN 算子调用)
这意味着,您只需将模型迁移到昇腾平台,就能自动享受 ACLNN 带来的性能提升,无需修改任何代码!
4.2 自定义应用:精细化控制
对于需要精细化控制的场景(如自研推理引擎、算子级调优),您可以像第三章那样,直接通过 ACL + ACLNN 的 C++ API 构建应用。
这种方式的优势在于:
- 零依赖:无需 Python 运行时,C++ 程序更轻量、启动更快。
- 精准控制:可以精确控制每个算子的执行时机、内存分配策略。
- 极致性能:结合第一篇文章讨论的 Stream/Event 机制,可以实现算子级别的流水线并行。
第五章:ACLNN 使用的最佳实践
5.1 如何查询 ACLNN 支持的算子?
CANN 官方提供了详细的算子文档。您可以访问:
https://www.hiascend.com/document (选择 CANN 版本 -> 算子开发)
在文档中,您可以查询到每个 ACLNN 算子的:
- API 接口定义
- 输入输出参数说明
- 支持的数据类型和 shape
- 性能特性
昇腾 AI 异构计算架构 CANN 可以被抽象成五层架构:

5.2 性能调优建议
-
选择合适的数据类型:ACLNN 支持 FP32、FP16、INT8 等多种数据类型。在精度允许的情况下,使用 FP16 或 INT8 可以获得更高性能。
-
利用算子融合:使用 ATC 工具转换模型时,开启算子融合选项(默认开启)。
-
合理配置 Batch Size:较大的 Batch Size 能更好地发挥 NPU 并行能力。
-
内存对齐:在分配 Device 内存时,使用对齐的尺寸(如 16 字节对齐)可以提升访存效率。
总结与展望
ACLNN 算子库是 CANN 架构的"加速引擎",它通过软硬协同优化、算法创新和生态开放,为昇腾 NPU 用户提供了"开箱即用"的极致性能。
通过本文的解析与实践,我们可以得出以下结论:
-
性能卓越:ACLNN 算子针对昇腾硬件深度优化,相比通用实现有数倍至数百倍的性能提升。
-
易于使用:无论是框架用户还是底层开发者,都能方便地利用 ACLNN 加速应用。
-
生态完善:ACLNN 覆盖数百个常用算子,并持续扩充,能满足绝大多数 AI 应用需求。
CANN 与 ACLNN 正在为AI基础设施的崛起提供强大的软件支撑。掌握 ACLNN,就是掌握了在昇腾平台上构建高性能 AI 应用的"金钥匙"。
参考资料
- CANN官方文档:https://www.hiascend.com/document
- YOLOv5项目:https://github.com/ultralytics/yolov5
- AscendCL开发指南:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/
如上部分配图来源于公开互联网,若有侵权,请及时联系,作者会第一时间下架删除。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 44
44 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)