
昇腾异构算子开发编程
在AI算力爆发式增长的今天,异构计算已成为支撑大模型训练、高分辨率图像处理等复杂任务的核心架构。昇腾AI芯片作为国内异构计算领域的标杆产品,其独特的达芬奇架构为高效算力输出提供了硬件基础,而异构算子作为连接硬件能力与上层应用的关键桥梁,直接决定了AI任务的执行效率。本文将从架构认知、开发流程、核心技术、优化策略到实战案例,全方位拆解昇腾异构算子开发的完整路径,助力开发者快速掌握这一核心技能。
在AI算力爆发式增长的今天,异构计算已成为支撑大模型训练、高分辨率图像处理等复杂任务的核心架构。昇腾AI芯片作为国内异构计算领域的标杆产品,其独特的达芬奇架构为高效算力输出提供了硬件基础,而异构算子作为连接硬件能力与上层应用的关键桥梁,直接决定了AI任务的执行效率。本文将从架构认知、开发流程、核心技术、优化策略到实战案例,全方位拆解昇腾异构算子开发的完整路径,助力开发者快速掌握这一核心技能。
一、昇腾异构计算架构核心认知
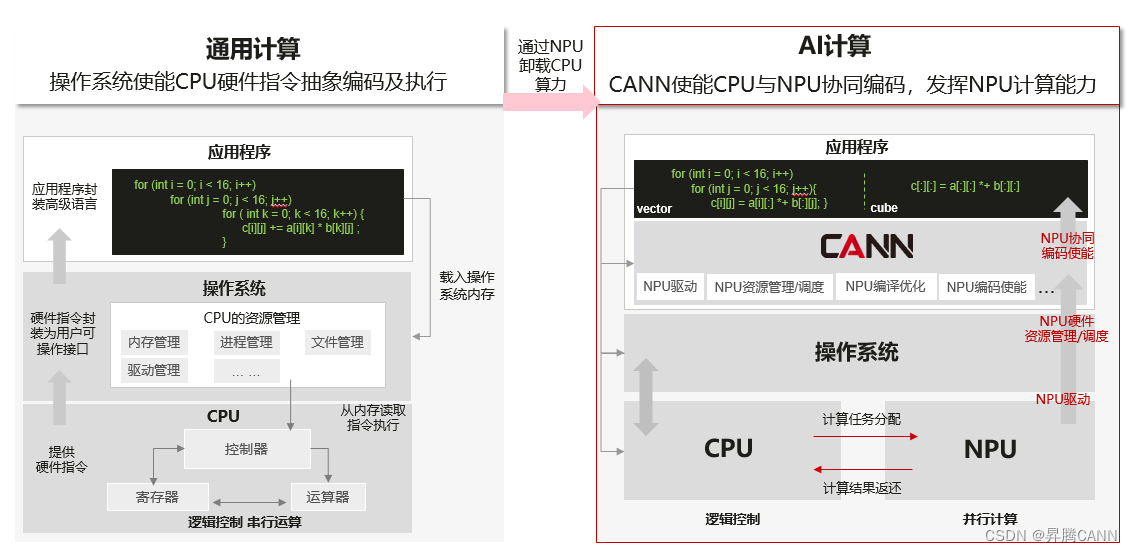
我们知道,通用计算就是我们常写的一些在CPU上运行的计算,它擅长逻辑控制和串行计算,而AI计算相对通用计算来说,更擅长并行计算,可支持大规模的计算密集型任务。在开展AI计算开发前,必须先深入理解昇腾的异构计算架构,明确各硬件单元的分工与协作模式,这是设计高效算子的前提。昇腾AI芯片采用“CPU+NPU”的经典异构架构,其中NPU(神经网络处理单元)是算力核心,内置大量达芬奇架构计算单元,而CPU则负责任务调度、数据预处理等控制类工作。
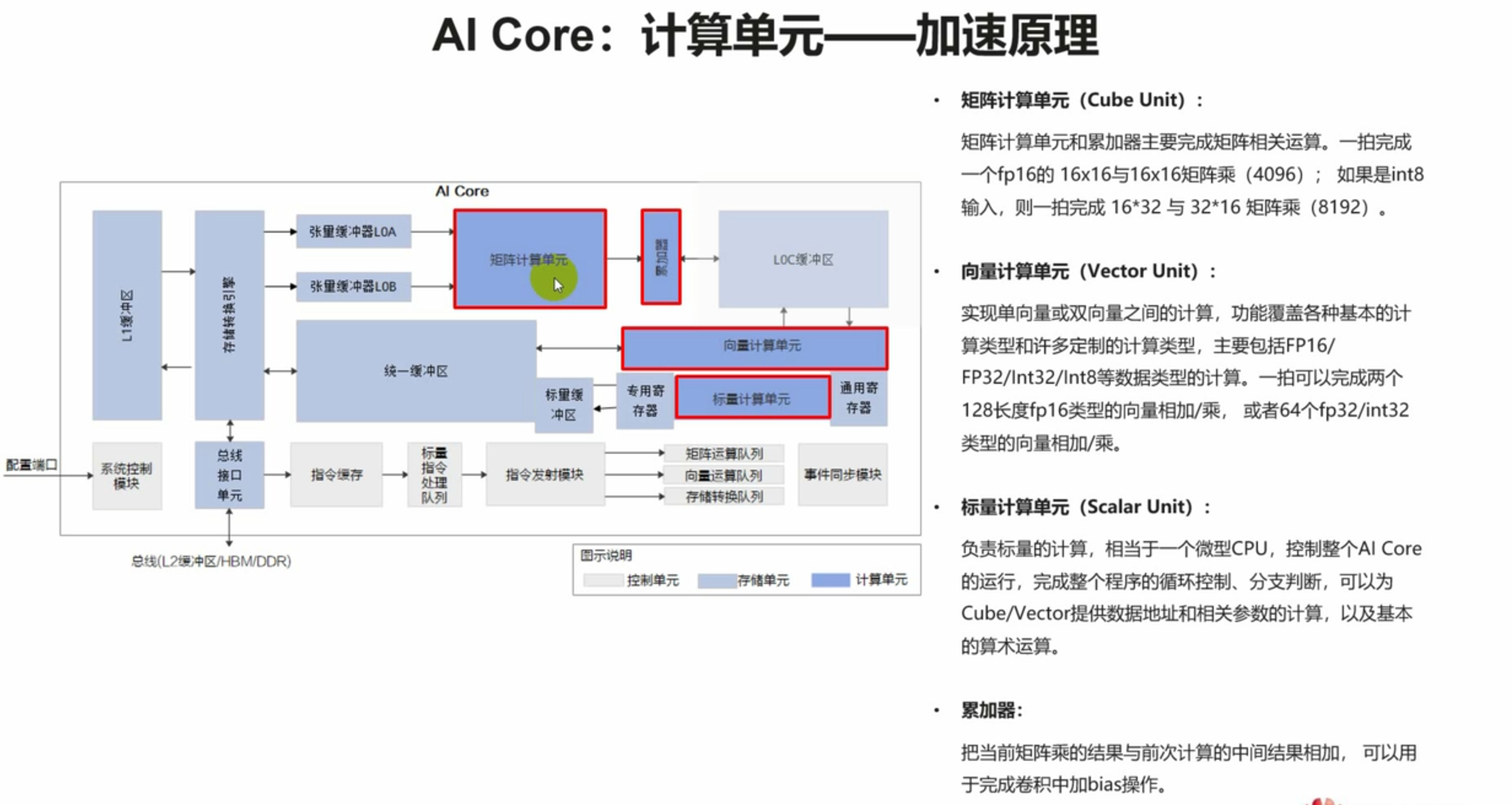
达芬奇架构作为昇腾NPU的核心,采用“计算单元阵列+存储层次化+指令并行化”的设计理念。每个计算单元包含矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit):Cube Unit专为矩阵乘法累加(GEMM)等核心AI运算设计,能提供超高算力密度;Vector Unit适用于向量级别的数据处理,如激活函数计算、数据格式转换;Scalar Unit则负责轻量级标量运算和流程控制。存储层次上,架构包含寄存器、L1缓存、L2缓存和外部内存,不同层级的存储速度和容量差异显著,算子开发的核心优化点之一就是减少数据在不同存储层级间的搬运。
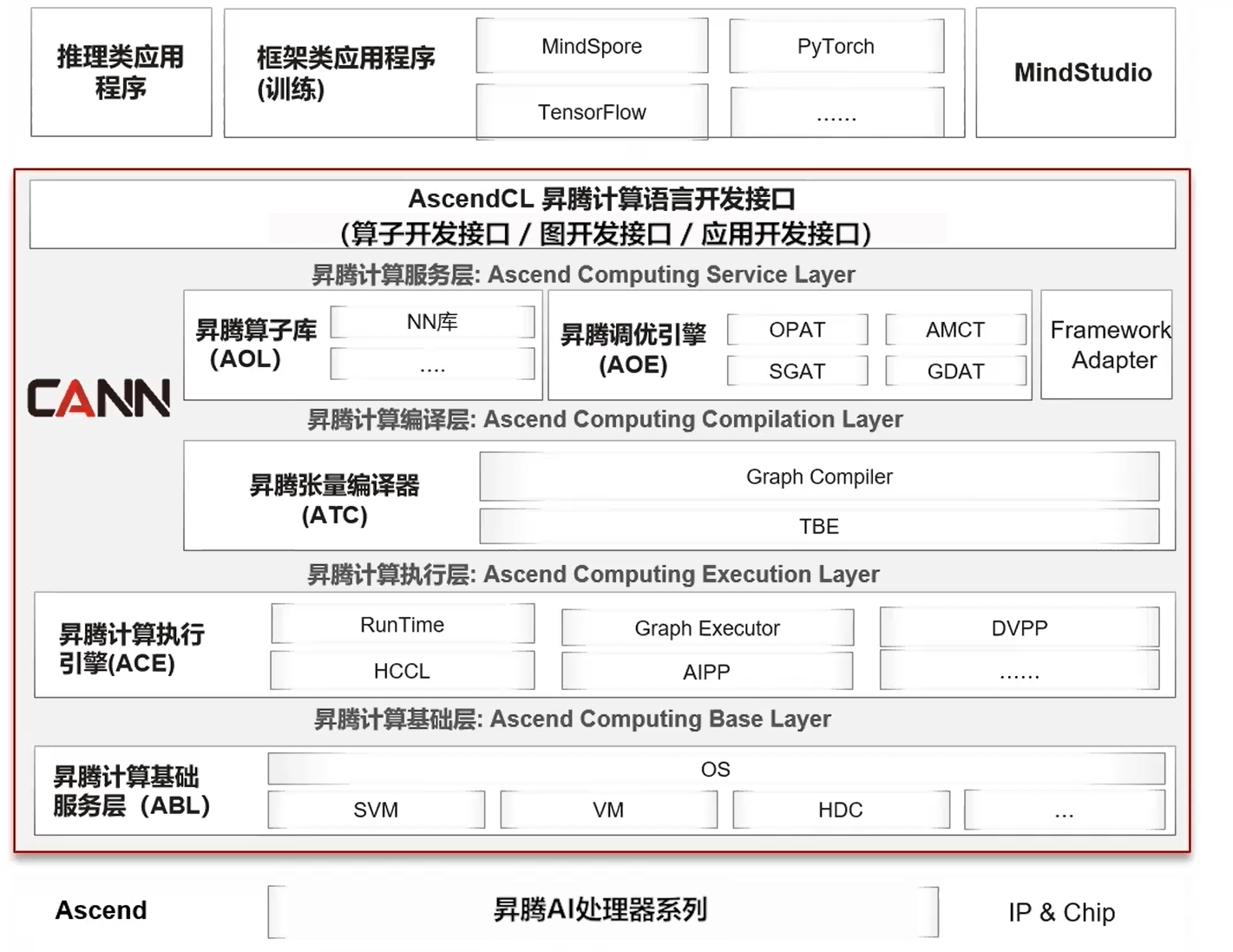
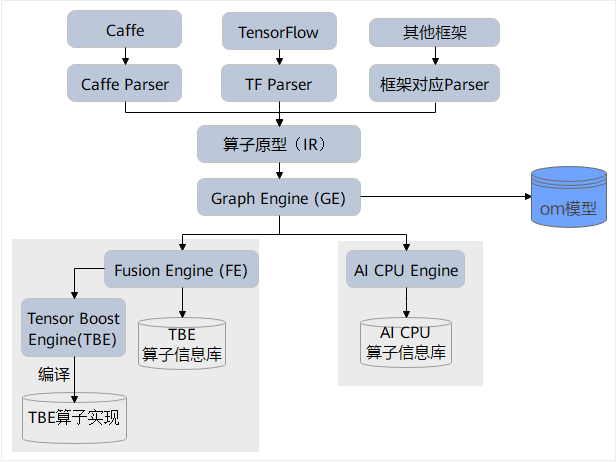
软件层面,昇腾提供了CANN(Compute Architecture for Neural Networks)异构计算架构作为开发基础。CANN是上层(推理类应用程序)与底层(昇腾AI处理器)的桥梁,提供了算子开发所需的全套API、编译工具链和性能分析工具。算子开发者主要基于CANN的AscendCL(Ascend Computing Language)和TBE(Tensor Boost Engine)进行开发,其中TBE是专为昇腾算子设计的开发框架,提供了丰富的算子开发模板和优化接口。
二、昇腾异构算子开发核心流程
昇腾异构算子开发遵循“构建模型→开发应用→编译运行→性能优化”的标准化流程,每个环节都有明确的目标和关键技术点。以下将详细拆解各环节的核心任务和实操要点。
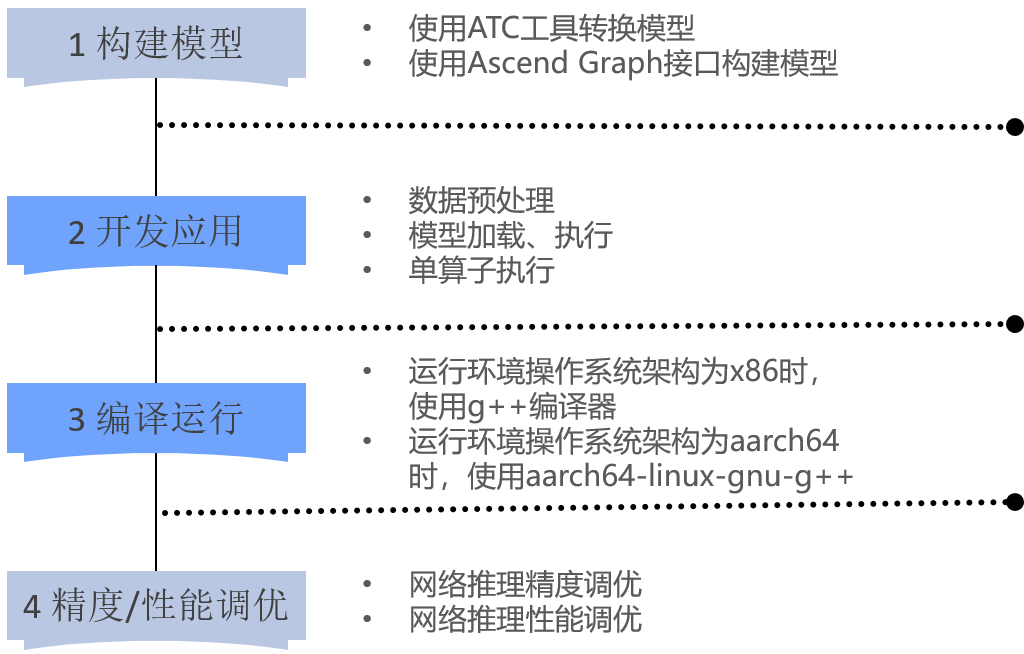
2.1 需求分析与构建模型
需求分析阶段需明确算子的核心功能、输入输出规格、数据类型及性能指标。首先要确定算子的应用场景:是用于模型训练还是推理?处理的数据是图像、文本还是语音?不同场景对算子的精度(如FP32、FP16、INT8)和性能(吞吐量、延迟)要求差异极大。例如,推理场景通常可采用INT8量化以提升性能,而训练场景则需FP32或FP16保证精度。
算子设计是决定开发效率和性能上限的关键环节,核心在于“硬件适配”——即根据昇腾硬件架构特点设计计算逻辑和数据流向。需重点关注三个维度:一是计算任务拆分,将复杂运算拆解为适合Cube Unit、Vector Unit的子任务,例如将卷积运算拆分为矩阵乘法(Cube Unit执行)和偏置加法(Vector Unit执行);二是数据布局优化,采用昇腾硬件友好的数据格式(如NHWC→NCHWc),减少数据搬运时的格式转换开销;三是存储层级利用,尽量将热点数据保存在L1缓存或寄存器中,避免频繁访问外部内存。
设计阶段建议绘制算子的计算流程图和数据流向图,明确各步骤的计算单元分配和数据存储位置,为后续编码提供清晰蓝图。
2.2 基于TBE的编码开发
TBE(Tensor Boost Engine)是昇腾官方推荐的算子开发框架,基于Python语言封装了大量底层硬件操作接口,兼具开发效率和性能优化能力。TBE算子开发的核心是构建算子的计算图和调度逻辑,主要包含以下关键步骤:
首先是算子信息定义,通过TBE提供的接口指定算子的输入输出张量信息(形状、数据类型、格式)、属性参数(如卷积核大小、步长)等,这是编译器进行后续优化的基础。例如,定义一个简单的矩阵加法算子时,需明确输入张量A、B的形状为[M, N],数据类型为FP16,输出张量C的形状与输入一致。
其次是计算逻辑实现,这是编码的核心部分。TBE提供了两类API:基础算子API(如add、mul、conv2d)和原子操作API(如cube_mm、vec_add)。对于简单算子,可直接调用基础算子API快速实现;对于复杂自定义算子,则需通过原子操作API对接底层硬件单元。例如,实现矩阵乘法时,可调用cube_mm接口直接利用Cube Unit的算力,同时指定数据的分块大小以适配缓存容量。
数据搬运与内存管理也是编码重点。昇腾异构架构中,CPU和NPU拥有独立的内存空间,算子开发需通过AscendCL的内存管理接口(如aclrtMalloc、aclrtMemcpy)实现数据在Host(CPU端)和Device(NPU端)之间的传输,以及Device端内部的内存分配与释放。需特别注意内存对齐和数据同步问题,避免出现内存泄漏或数据不一致的情况。
最后是算子注册,将实现的算子逻辑注册到TBE算子库中,以便编译器在编译模型时能够识别和调用。注册时需指定算子的名称、适配的硬件版本和数据类型等信息,确保算子能够被正确匹配。
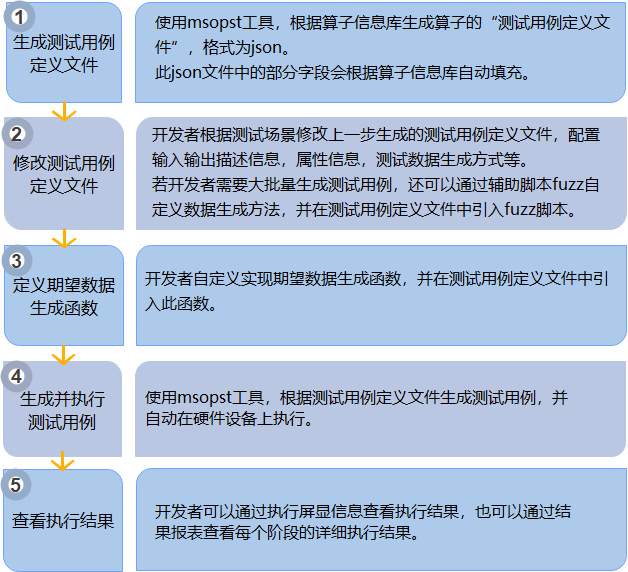
2.3 编译调试与验证
编码完成后,需通过CANN提供的编译工具链进行编译,并开展全面的调试验证工作,确保算子功能正确、运行稳定。
编译过程主要通过昇腾算子编译器(Operator Compiler)完成,将TBE算子的Python代码编译为适配昇腾硬件的二进制文件(.o文件)和算子描述文件(.json)。编译时需指定目标硬件型号(如Ascend 910B、Ascend 310B)和编译选项(如优化级别、调试开关)。编译过程中若出现语法错误或接口调用错误,编译器会输出详细的错误信息,开发者可根据信息定位问题并修改代码。
调试环节分为功能调试和性能调试。功能调试可通过编写单算子测试用例,利用CANN的测试工具(如msoptest)加载算子并输入测试数据,对比算子输出结果与预期结果的一致性。对于复杂算子,建议采用“分步骤调试”策略,逐步验证每个计算子模块的输出是否正确。性能调试则需借助昇腾性能分析工具(如Profiling),采集算子运行过程中的硬件指标(如Cube Unit利用率、内存带宽、任务调度延迟),定位性能瓶颈。
验证环节需覆盖不同的输入场景,包括边界值(如输入张量为空、形状为1x1)、极端值(如超大尺寸张量)和典型业务场景数据,确保算子的鲁棒性。同时,还需验证算子在不同硬件型号和CANN版本下的兼容性,避免出现版本适配问题。
六、结束语
昇腾异构算子开发是一项“硬件认知+软件实现+性能优化”三位一体的复杂工作,核心在于深入理解达芬奇架构的硬件特性,通过TBE框架高效对接硬件能力,并围绕计算单元利用率、内存开销、任务调度三大核心维度进行优化。本文通过架构解析、流程拆解、策略总结和实战案例,为开发者提供了系统的开发指南,助力快速掌握昇腾算子开发技能。
随着昇腾生态的不断完善,算子开发工具链也在持续升级——CANN 7.0及以上版本提供了更智能的自动优化工具(如AutoTune),可自动搜索最优的分块大小和调度策略;同时,昇腾算子仓库(Ascend Operator Zoo)已积累大量成熟算子案例,开发者可通过复用案例快速实现自定义算子开发。未来,随着AI大模型和异构计算技术的持续演进,昇腾算子开发将向“自动化、智能化、高并行化”方向发展,为开发者降低开发门槛的同时,进一步释放硬件算力潜力。
对于开发者而言,建议从基础算子入手,逐步积累硬件适配经验,善用Profiling等工具定位问题,同时关注昇腾官方生态的更新动态,充分利用工具链和案例资源提升开发效率。相信通过持续实践与优化,开发者能够打造出高效、稳定的昇腾异构算子,为AI业务的性能提升提供核心支撑。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)