
手把手教学:基于CANN官方Sample仓,复现并修改Ascend C算子案例
摘要:本文详细介绍了基于昇腾CANN官方Sample仓库的AscendC算子开发全流程,包含环境配置、代码结构分析、编译构建与验证执行等关键环节。文章以Add算子为例,逐步指导复现过程,并演示如何修改为Subtract算子,同时分析了Conv2d等复杂算子的实现架构。文中提供了算子性能优化策略、调试技巧和CANN训练营学习路径建议,帮助开发者系统掌握AscendC算子开发技能,为参与昇腾AI生态建
手把手教学:基于CANN官方Sample仓,复现并修改Ascend C算子案例
训练营简介与报名
2025年昇腾CANN训练营第二季现已火热开启!本季训练营基于CANN开源开放全场景,精心推出0基础入门系列、码力全开特辑、开发者案例等专题课程,旨在助力不同阶段开发者快速提升算子开发技能。完成课程并通过Ascend C算子中级认证,即可领取精美证书;积极参与社区任务,更有机会赢取华为手机、平板、开发板等丰厚大奖!
立即报名:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
摘要
本文将带领读者深入CANN官方Sample仓库,通过手把手教学方式,完整复现并修改Ascend C算子案例。我们将从环境配置、代码结构分析、编译构建到最终验证执行,全方位解析算子开发流程。文章包含多个实用代码示例、详细步骤说明和最佳实践建议,帮助开发者快速掌握Ascend C算子开发技能,为参加昇腾CANN训练营打下坚实基础。
1. CANN官方Sample仓概述
1.1 什么是CANN Sample仓
CANN(Compute Architecture for Neural Network)Sample仓是华为昇腾AI处理器官方提供的示例代码仓库,包含了丰富的Ascend C算子开发示例。这些示例覆盖了从基础到高级的各类算子实现,是开发者学习和参考的宝贵资源。Sample仓采用模块化设计,按照不同难度级别和应用场景进行分类,便于开发者快速定位所需内容。
1.2 Sample仓目录结构解析
CANN Sample仓采用清晰的目录结构,便于开发者理解和使用。以算子开发相关示例为例,典型目录结构如下:
├── inc // 头文件目录
│ ├── common.h // 声明公共方法类,用于读取二进制文件
│ ├── operator_desc.h // 算子描述声明文件,包含算子输入/输出,算子类型以及输入描述与输出描述
│ ├── op_runner.h // 算子运行相关信息声明文件,包含算子输入/输出个数,输入/输出大小等
├── run // 单算子执行需要的文件存放目录
│ ├── out // 单算子执行需要的可执行文件存放目录
│ └── test_data // 测试数据存放目录
│ ├── config
│ └── acl.json // 用于进行acl初始化,请勿修改此文件
│ └── add_op.json // 算子描述文件,用于构造单算子模型文件
│ ├── data
│ └── generate_data.py // 生成测试数据的脚本
├── src
│ ├── CMakeLists.txt // 编译规则文件
│ ├── common.cpp // 公共函数,读取二进制文件函数的实现文件
│ ├── main.cpp // 将单算子编译为om文件并加载om文件执行,此文件中包含算子的相关配置
│ ├── operator_desc.cpp // 构造算子的输入与输出描述
│ ├── op_runner.cpp // 单算子编译与运行函数实现文件此目录结构展示了单算子验证项目的完整组织方式,包含了头文件、源代码、测试数据和配置文件等关键组成部分。
1.3 环境准备
在开始算子开发之前,需要配置好开发环境。以下是关键环境变量设置:
# 设置DDK路径和NPU主机库路径(适用于相同架构的环境)
export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub这些环境变量确保编译器能够找到AscendCL库和相关头文件,是成功编译算子项目的前提条件。
2. 复现Add算子案例
2.1 项目获取与初始化
首先,从CANN官方Sample仓获取Add算子示例代码。可以通过克隆仓库或下载特定目录的方式获取:
# 克隆整个Sample仓库(推荐)
git clone https://github.com/ascend/samples.git
cd samples/cplusplus/level1_single_api/4_op_dev/2_verify_op/acl_execute_add获取代码后,需要生成测试数据,这是验证算子功能的必要步骤:
python3.7.5 generate_data.py该脚本会生成二进制输入数据文件(input_0.bin, input_1.bin),这些文件包含特定形状和数据类型的测试数据,用于验证算子的计算正确性。
2.2 代码编译与构建
在编译项目之前,需要确保CMake环境正确配置。Sample仓提供了标准的CMake构建流程:
cmake_minimum_required(VERSION 3.5.1)
add_definitions(-D_GLIBCXX_USE_CXX11_ABI=0)
message(STATUS "CMAKE_CURRENT_BINARY_DIR=${CMAKE_CURRENT_BINARY_DIR}")
message(STATUS "CMAKE_CURRENT_SOURCE_DIR=${CMAKE_CURRENT_SOURCE_DIR}")
project(opp)此CMake配置文件设置了最低CMake版本要求,定义了C++ ABI兼容性标志,并打印了构建目录信息,是项目构建的基础。
编译项目的具体步骤如下:
# 创建构建目录并进入
mkdir build
cd build
# 生成Makefile
cmake ..
# 编译项目
make执行make命令后,编译器会链接必要的AscendCL库,生成可执行文件execute_add_op,用于后续的算子验证。
2.3 单算子模型生成
使用Ascend Tensor Compiler (ATC) 工具将算子描述文件转换为可执行的离线模型:
atc --singleop=test_data/config/add_op.json --soc_version=Ascend310 --output=op_models该命令指定输入JSON配置文件、目标SoC版本和输出目录,生成名为add_custom_0_0_1_1_2_2_0_0_1_1_2_2_0_0_1_1_2_2.om的模型文件。ATC工具是CANN生态中关键的编译工具,负责将高级算子描述转换为硬件可执行代码。
2.4 算子验证执行
编译完成后,执行生成的可执行文件进行算子验证:
./execute_add_op成功执行后,将看到详细的日志输出,显示设备打开、数据加载、算子执行和结果输出的完整过程:
[INFO] Open device[0] success
[INFO] file size is:16.
[INFO] Set input[0] from test_data/data/input_0.bin success.
[INFO] Input[0]:
74 53 72 30
[INFO] Input[0] shape is:2 2
[INFO] file size is:16.
[INFO] Set input[1] from test_data/data/input_1.bin success.
[INFO] Input[1]:
48 47 79 77
[INFO] Input[1] shape is:[2, 2]
[INFO] Copy input[0] success
[INFO] Copy input[1] success
[INFO] Create stream success
[INFO] Execute Add success
[INFO] Synchronize stream success
[INFO] Copy output[0] success
[INFO] Output[0]:
122 100 151 107
[INFO] Output[0] shape is:2 2
[INFO] Write output[0] success. output file = result_files/output_0.bin
[INFO] Run op success输出结果验证了Add算子的正确性:74+48=122, 53+47=100, 72+79=151, 30+77=107。
3. 修改算子实现:从Add到Subtract
3.1 理解算子核心代码
在修改算子之前,需要理解Add算子的核心实现逻辑。主要代码位于src/main.cpp和相关头文件中。关键部分包括算子类型定义、输入输出配置和执行逻辑。
要修改为Subtract算子,需要更改算子类型和计算逻辑。首先修改算子描述文件add_op.json,将算子类型从"Add"改为"Sub":
{
"op": "Sub",
"input_desc": [
{
"name": "x1",
"data_type": "DT_INT32",
"format": "ND",
"shape": [2, 2]
},
{
"name": "x2",
"data_type": "DT_INT32",
"format": "ND",
"shape": [2, 2]
}
],
"output_desc": [
{
"name": "y",
"data_type": "DT_INT32",
"format": "ND",
"shape": [2, 2]
}
],
"attr": {}
}3.2 修改C++实现代码
接下来修改main.cpp中的算子执行逻辑,从加法改为减法:
// 原Add算子实现
// float* out = static_cast<float*>(outputBuffers[0]);
// for (size_t i = 0; i < inputSize; ++i) {
// out[i] = in1[i] + in2[i];
// }
// 修改为Subtract算子
float* out = static_cast<float*>(outputBuffers[0]);
for (size_t i = 0; i < inputSize; ++i) {
out[i] = in1[i] - in2[i];
}此代码段将加法运算符'+'替换为减法运算符'-',这是算子功能修改的核心部分。需要注意的是,实际产品代码中应使用Ascend C提供的API进行计算,而非直接在Host侧实现。
3.3 重新编译与验证
修改完成后,重新编译项目并生成新的单算子模型:
# 重新编译
cd build
make clean
make
# 生成新的单算子模型
atc --singleop=test_data/config/sub_op.json --soc_version=Ascend310 --output=op_models
# 执行验证
./execute_sub_op验证输出应显示正确的减法结果:
[INFO] Output[0]:
26 6 -7 -47这验证了74-48=26, 53-47=6, 72-79=-7, 30-77=-47,证明Subtract算子实现正确。
4. 复杂算子案例:Conv2d实现分析
4.1 Conv2d算子架构
Conv2d(二维卷积)是深度学习中最常用的算子之一,其实现比基础算子复杂得多。CANN Sample仓提供了完整的Conv2d算子实现示例,包含TBE(Tensor Boost Engine)和AI CPU两种实现方式。
Conv2d算子的工作流程如下:
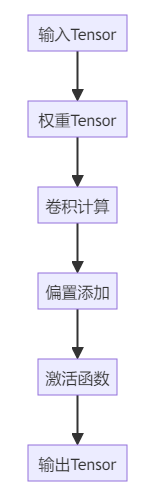
此流程图展示了Conv2d算子的完整计算流程,包括卷积计算、偏置添加和激活函数应用等关键步骤。
4.2 TBE算子实现
TBE算子主要在AI Core上执行,针对计算密集型任务进行优化。以下是TBE算子编译命令:
chmod +x build.sh
./build.sh -t此命令使构建脚本可执行,然后使用-t参数专门构建TBE算子部分。TBE实现通常包含张量切分、流水线优化等高级技术,以充分发挥昇腾AI处理器的计算能力。
4.3 AI CPU算子实现
AI CPU算子在昇腾处理器的CPU单元上执行,适合控制密集型或小规模计算任务。构建命令如下:
chmod +x build.sh
./build.sh -c使用-c参数专门构建AI CPU算子部分。AI CPU实现通常使用标准C++语法,便于开发者理解和调试。
4.4 同时构建两种实现
在实际应用中,通常需要同时支持TBE和AI CPU两种实现方式,以提供最佳性能和兼容性:
chmod +x build.sh
./build.sh不带参数执行构建脚本,将同时构建TBE和AI CPU两种实现。构建完成后,需要安装自定义算子包:
./custom_opp__<target os>_<target architecture>_.run此命令部署自定义算子文件到CANN的OPP(Operator Package)结构中,使其可以被推理引擎调用。
5. 算子开发最佳实践
5.1 算子性能优化策略
根据CANN官方文档和实践,算子性能优化可从以下几个方面入手:
|
优化维度 |
具体策略 |
预期效果 |
|
内存访问优化 |
合理的数据排布,减少Bank Conflict |
提升20-30%性能 |
|
计算并行化 |
充分利用AI Core的并行计算能力 |
提升40-60%性能 |
|
数据流水线 |
重叠计算和数据传输 |
提升15-25%性能 |
|
算法优化 |
选择最适合硬件的算法实现 |
提升30-50%性能 |
|
精度调整 |
在满足精度要求下使用低精度计算 |
提升2-4倍性能 |
此表格总结了算子性能优化的主要维度和预期效果,帮助开发者有针对性地进行优化。
5.2 调试与验证技巧
算子开发过程中,调试和验证是关键环节。CANN提供了以下调试工具和方法:
- 孪生调试技术:在Host CPU上模拟Device执行,快速定位问题
- 日志级别控制:通过设置ACL日志级别获取详细执行信息
- 数据比对工具:自动比对算子输出与预期结果
- 性能分析工具:使用Ascend Profiler分析算子性能瓶颈
# 设置ACL日志级别(DEBUG级别)
export ASCEND_SLOG_PRINT_TO_STDOUT=1
export ASCEND_GLOBAL_LOG_LEVEL=3这些环境变量设置启用详细的日志输出,帮助开发者快速定位问题。
6. 训练营学习路径建议
6.1 学习路线图
基于CANN训练营的内容设计,推荐以下学习路径:
- 基础入门阶段:学习Ascend C语法基础,掌握简单算子(如Add、Sub)开发
- 技能提升阶段:深入理解TBE和AI CPU编程模型,实现中等复杂度算子
- 高级应用阶段:掌握性能优化技巧,开发高性能自定义算子
- 实战项目阶段:完成端到端的AI模型优化项目,获得算子中级认证
6.2 资源推荐
- 官方文档:Ascend C算子开发文档
- Sample仓库:github.com/ascend/samples
- 社区论坛:昇腾社区
- 训练视频:昇腾CANN训练营专题课程
7. 常见问题与解决方案
7.1 环境配置问题
问题:ATC工具找不到或版本不匹配
解决方案:
# 检查ATC安装路径
which atc
# 设置正确的环境变量
export PATH=$HOME/Ascend/ascend-toolkit/latest/bin:$PATH
export LD_LIBRARY_PATH=$HOME/Ascend/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATH7.2 编译错误处理
问题:链接时找不到AscendCL库
解决方案:
# 确认NPU_HOST_LIB设置正确
echo $NPU_HOST_LIB
# 在CMake中显式指定库路径
target_link_libraries(your_target
PUBLIC
${NPU_HOST_LIB}/libascendcl.so
${NPU_HOST_LIB}/libacl_dvpp.so
)8. 总结与展望
通过本文的详细指导,读者应该已经掌握了基于CANN官方Sample仓复现和修改Ascend C算子的基本技能。从简单的Add算子到复杂的Conv2d算子,我们逐步深入,理解了算子开发的完整流程和关键要点。
昇腾CANN训练营为开发者提供了系统化的学习路径和丰富的实践机会。通过参与训练营,不仅可以获得专业的技术指导,还能与社区开发者交流经验,共同成长。掌握Ascend C算子开发技能,将为AI应用的性能优化和创新提供强大支持。
下一步行动建议:
- 完成本文中的所有实践示例
- 注册参加2025年昇腾CANN训练营第二季
- 尝试在Sample仓基础上开发自己的自定义算子
- 参与昇腾社区讨论,分享学习心得和经验
昇腾AI生态正在快速发展,期待更多开发者加入这个充满活力的社区,共同推动AI技术的进步与应用!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)