
超越核函数:掌握昇腾CANN中的主机-设备交互,实现端到端性能跃升
如果这场交响乐的指挥节奏混乱,充满了不必要的停顿和等待,那么无论单个乐手(核函数)的技艺多么高超,最终的演出(端到端性能)也必然是缓慢而拖沓的。对于需要处理一批数据的任务,我们可以将其切分成多个数据块(Chunks),并使用至少三个Stream来构建流水线:一个用于将数据从主机拷贝到设备(H2D),一个用于计算,一个用于将结果从设备拷回主机(D2H)。这个过程增加了一次额外的内存拷贝。我们可以创建
前言
在CANN算子开发的学习路径中,我们往往沉醉于核函数(Kernel)优化的精妙艺术:精心设计Tiling策略、实现完美的双缓冲、将向量指令运用到极致。然而,一个在AI Core上执行效率高达99%的核函数,其最终的端到端性能,却可能被一个效率低下的“指挥官”——主机(Host CPU)——所拖累。
一个AI模型的执行,并非一次单一、宏大的核函数调用,而是由主机端精心编排的、包含数千个任务的复杂交响乐。这些任务包括数据从主机到设备的传输、一系列核函数的启动、以及设备到主机的结果回传。如果这场交响乐的指挥节奏混乱,充满了不必要的停顿和等待,那么无论单个乐手(核函数)的技艺多么高超,最终的演出(端到端性能)也必然是缓慢而拖沓的。
本文旨在带领你“超越核函数”的微观视角,上升到系统层面,深入探索CANN生态中主机与设备交互的世界。我们将解构其核心的异步执行模型,掌握Stream(流)这一并行化利器,并学习如何系统性地最小化同步开销,从而将优化对象从单个算子,扩展到整个计算流水线。
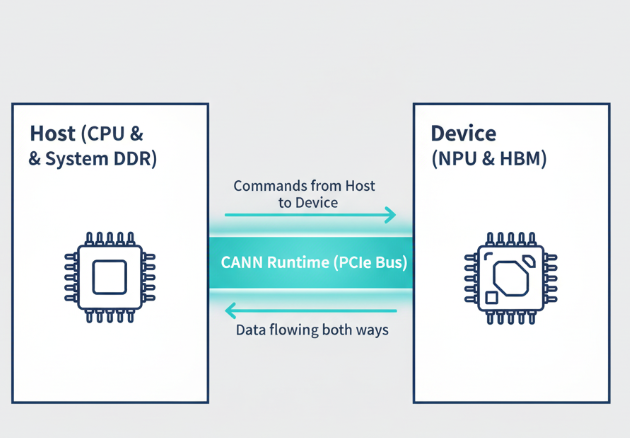
第一章:两个世界及其桥梁 —— 主机、设备与运行时
要理解交互,必先明确参与者。在异构计算中,我们始终在与两个分离但又紧密协作的世界打交道:
- 主机(Host): 指的是系统的CPU及其主内存(DDR)。它是整个系统的“总指挥官”,负责执行主程序逻辑、准备数据、发起计算任务、管理硬件资源以及处理最终结果。在CANN算子开发中,
TilingFunc的计算、算子信息的注册等逻辑,都运行在主机端。 - 设备(Device): 指的是昇腾NPU及其板载的高速内存(HBM)。它是“超级计算兵团”,负责执行被下发的高密度计算任务。我们编写的Ascend C核函数,就是在这个世界里运行。
这两个世界拥有各自独立的内存空间。主机CPU不能直接读写设备的HBM,反之亦然。它们之间的所有通信,都必须通过一座“桥梁”来完成。这座桥梁,就是CANN的运行时库(Runtime),它提供了如aclrtMemcpy(内存拷贝)、aclrtLaunchKernel(核函数启动)等API。
第二章:高性能的心脏 —— 异步执行模型与Stream
理解CANN乃至所有现代异构计算平台的性能,关键在于理解**“异步执行”**。
2.1 同步 vs. 异步:咖啡店里的哲学
- 同步(Synchronous): 你去咖啡店点单,说完“一杯拿铁”后,你就必须站在柜台前一直等待,直到咖啡师做完、递给你,你才能离开去做别的事。这是阻塞式的,CPU在等待期间被浪费了。
- 异步(Asynchronous): 你点完单,拿到一个取餐器。下单后,你就可以立刻离开柜台,去看书、回消息。当咖啡做好时,取餐器会震动提醒你。这是非阻塞式的,CPU在等待期间可以去处理其他任务。
CANN的大部分关键操作,默认都是异步的。 当主机调用aclrtLaunchKernel启动一个核函数时,它就像点了一杯“计算拿铁”。该API会将这个计算任务提交给CANN的运行时,然后立即返回,主机CPU可以马上去执行下一行代码(比如提交下一个核函数启动任务),而无需等待N-PU上的计算完成。
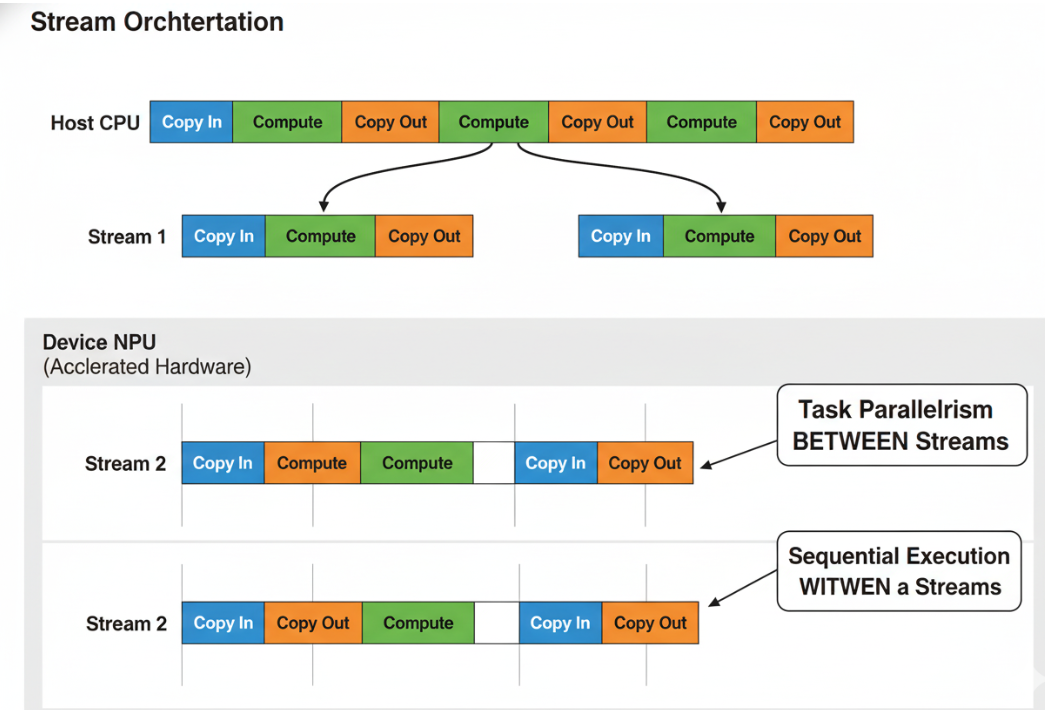
2.2 Stream(流):任务的有序队列
既然任务是异步提交的,CANN如何保证它们的执行顺序?答案是Stream。
一个Stream可以被理解为一个设备端任务的FIFO(先进先出)队列。主机向同一个Stream提交的所有任务(如数据拷贝、核函数启动),CANN会保证它们在设备上严格按照提交的顺序被执行。
Stream的真正威力在于:不同Stream之间的任务,在硬件资源允许的情况下,可以并行执行!
这为我们提供了强大的并行化武器。我们可以创建多个Stream,将一个复杂的任务分解成多个独立的子任务,分配到不同的Stream中,从而实现任务级的并行。
第三章:性能的“绊脚石” —— 同步开销
异步执行虽然强大,但我们终究需要知道计算何时完成,或者需要将结果从设备传回主机。这时,**同步(Synchronization)**就不可避免了。同步是性能优化的“必要之恶”,因为它会强制“急性子”的主机停下来,等待“慢悠悠”的设备。
3.1 常见的同步操作
- 隐式同步(Implicit Synchronization): 最常见也最容易被忽视的,就是从设备到主机的内存拷贝,即
aclrtMemcpy(..., ACL_MEMCPY_DEVICE_TO_HOST)。当主机发起这个调用时,它必须等待设备上所有之前提交到该Stream的任务全部完成,并且数据拷贝也完成后,才能继续执行。这是一个非常强烈的阻塞点。 - 显式同步(Explicit Synchronization):
aclrtSynchronizeStream(stream): 阻塞主机,直到指定stream中的所有任务都执行完毕。aclrtSynchronizeDevice(): 一个“核武器”级别的同步。它会阻塞主机,直到设备上所有Stream中的所有任务全部执行完毕。
3.2 同步开销的危害
每一次同步,都意味着主机CPU的空闲等待,以及整个计算流水线的“断流”。在Profiler的Timeline视图中,频繁的同步会表现为主机端出现大量的“白色空洞”,CPU无事可做,只能等待NPU。
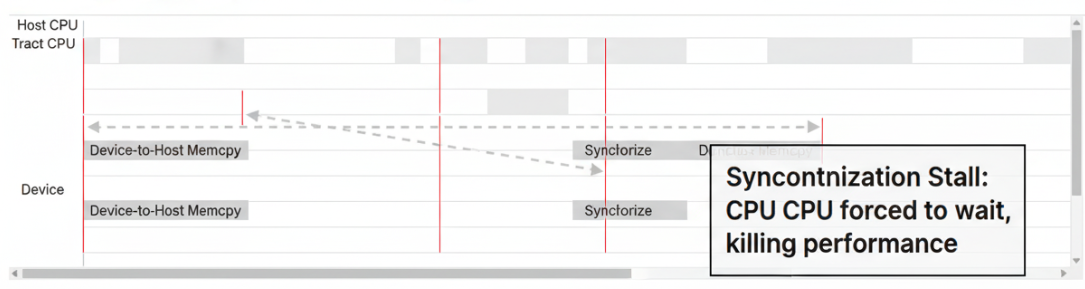
优化的核心原则之一:将同步点推迟到万不得已的时刻,并尽可能减少同步的次数。
第四章:实践出真知:端到端优化技术
理解了上述理论后,我们就可以在实践中应用一系列技巧,来构建高效的主机-设备交互流水线。
4.1 技巧一:利用Stream实现计算与数据传输的重叠(Overlap)
这是最经典、最重要的优化。对于需要处理一批数据的任务,我们可以将其切分成多个数据块(Chunks),并使用至少三个Stream来构建流水线:一个用于将数据从主机拷贝到设备(H2D),一个用于计算,一个用于将结果从设备拷回主机(D2H)。
伪代码示例:
// 1. 创建三个Stream
aclrtCreateStream(&streamH2D);
aclrtCreateStream(&streamCompute);
aclrtCreateStream(&streamD2H);
// 2. 将数据切分成N个Chunks
for (int i = 0; i < N; ++i) {
// 3. 在H2D Stream中,异步地将第i块数据拷贝到设备
aclrtMemcpyAsync(device_input[i], host_input[i], ..., streamH2D);
// 4. 在Compute Stream中,异步地启动对第i块数据的计算核函数
// (需要设置Stream间的依赖事件,确保数据拷贝完成后才开始计算)
aclrtLaunchKernel(..., streamCompute);
// 5. 在D2H Stream中,异步地将第i块结果拷贝回主机
// (需要设置Stream间的依赖事件,确保计算完成后才开始拷贝)
aclrtMemcpyAsync(host_output[i], device_output[i], ..., streamD2H);
}
// 6. 最后,在所有任务都提交后,进行一次总的同步
aclrtSynchronizeDevice();
通过这种方式,第i块数据的“计算”,可以与第i+1块数据的“H2D拷贝”和第i-1块数据的“D2H拷贝”同时进行,实现了整个流程的深度流水线化。
4.2 技巧二:批量提交与减少API调用开销
每一次调用CANN Runtime API(如aclrtLaunchKernel)本身都有一定的CPU开销。如果你有成千上万个微小的计算任务,频繁地为每一个任务调用API,主机端的开销将变得不可忽视。
优化策略:
- 算子融合: 在图层面,这是最好的方法。
- 任务合并: 在算子层面,如果可能,将多个小的计算任务,合并成一个大的计算任务,通过一次核函数启动来完成。例如,处理1000个1x1的加法,不如将其合并成一个处理1000x1向量的加法。
4.3 技巧三:使用固定内存(Pinned Memory)
默认情况下,主机端的内存是可分页的(Pageable)。当从这种内存向设备拷贝数据时,CANN Runtime必须先将其拷贝到一个临时的、不可分页的**固定内存(Pinned Memory)**缓冲区,然后再由DMA引擎传送到设备。这个过程增加了一次额外的内存拷贝。
通过使用aclrtMallocHost()来分配主机内存,我们可以直接获得一块“固定内存”。从这块内存发起的H2D/D2H拷贝,可以免去中间的临时拷贝,直接由DMA进行传输,从而获得更高的带宽。
结论:成为流水线的总指挥
核函数优化决定了计算的“峰值速度”,而主机-设备交互的优化,则决定了系统能多大程度上维持在这个峰值速度。一个优秀的AI系统性能工程师,不仅是一位精通硬件的“工匠”,更是一位洞察全局、善于调度的“指挥家”。
通过深刻理解异步执行模型,善用Stream构建并行流水线,并审慎地管理每一次同步,你将能够打破单点优化的局限,将目光投向整个端到端流程,最终实现系统性能的质变。
从“工匠”到“指挥家”的进阶之路:
这些高级的系统级优化思想和实践,正是2025年昇腾CANN训练营第二季中【开发者案例】和【码力全开特辑】所要传递的核心价值。
- 系统化课程: 从核函数到系统流水线,构建你的全栈性能视野。
- 官方技术支持与社区: 与顶尖工程师交流,探讨真实世界中的性能瓶颈。
- 权威技能认证: Ascend C中级认证,证明你具备端到端性能调优能力。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你已准备好超越核函数,成为一名真正的AI系统性能指挥家,那么,这里就是你的起点。
报名链接: https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)