
仓颉协程的调度机制:从M\:N模型到运行时协同的深度探索
在现代应用开发中,并发和异步编程能够有效提高处理器利用率,并在交互式应用中确保程序的响应速度。仓颉语言作为华为面向鸿蒙生态的原生编程语言,其并发机制和Go类似,协程框架、运行时自动调度,IO场景同步编码、异步运行,开发和运行效率都很高。本文将从M:N线程模型的理论基础出发,深入剖析仓颉协程调度器的设计哲学、运行时架构以及性能优化策略,揭示其在高并发场景下的工程价值。仓颉的协程调度机制体现了对并发编
引言:重新定义轻量级并发
在现代应用开发中,并发和异步编程能够有效提高处理器利用率,并在交互式应用中确保程序的响应速度。仓颉语言作为华为面向鸿蒙生态的原生编程语言,其并发机制和Go类似,协程框架、运行时自动调度,IO场景同步编码、异步运行,开发和运行效率都很高。本文将从M:N线程模型的理论基础出发,深入剖析仓颉协程调度器的设计哲学、运行时架构以及性能优化策略,揭示其在高并发场景下的工程价值。
M:N线程模型:架构设计的基石
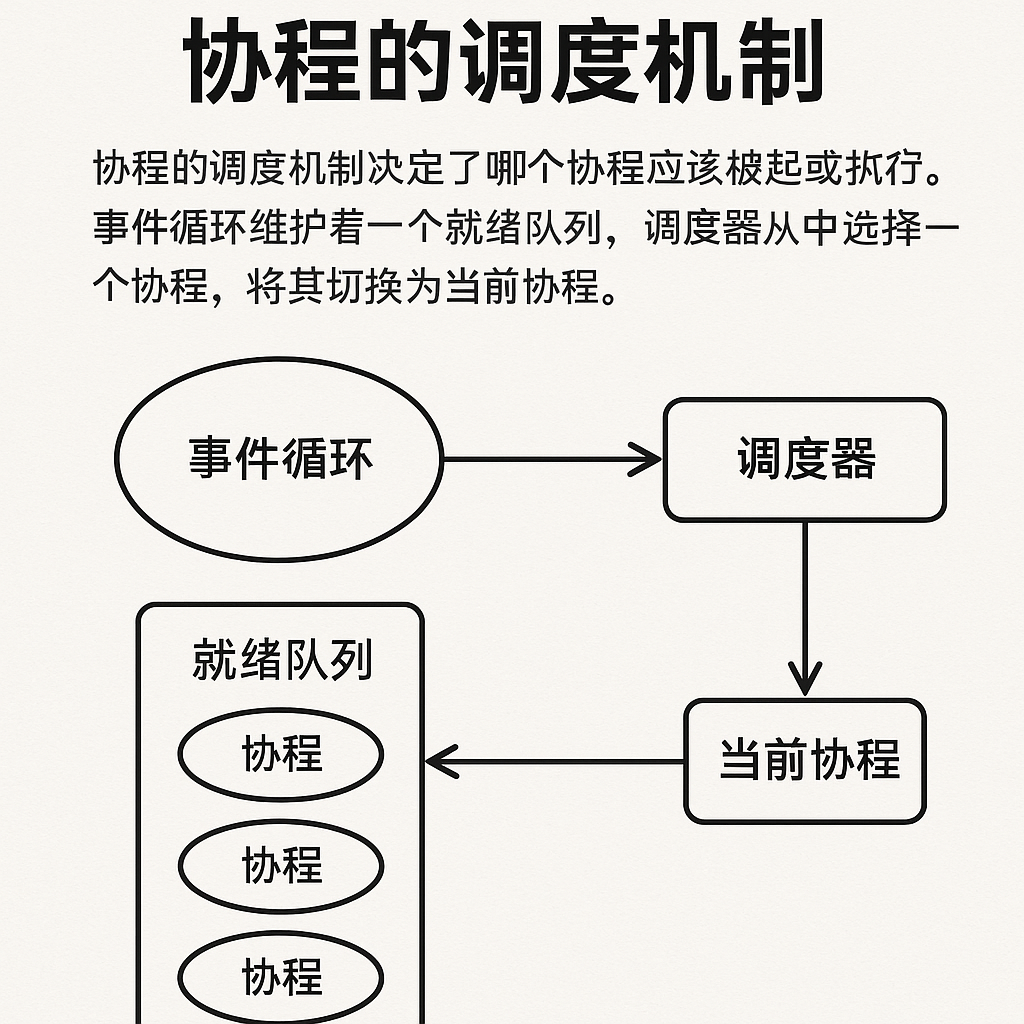
仓颉语言采用M:N线程模型,即M个仓颉线程在N个native线程上调度执行,其中M和N不一定相等。这种设计选择在理论与实践之间找到了精妙的平衡点。仓颉线程本质上是用户态的轻量级线程,每个仓颉线程都受到底层native线程的调度执行,并且多个仓颉线程可以由一个native线程执行。
让我们通过一个实际的示例来理解这种模型:
main() {
// 创建大量轻量级线程
let handles = Array<Thread>()
for i in 0..1000 {
let handle = spawn {
println("Thread ${i} starting on native thread")
// 模拟一些工作
var sum = 0
for j in 0..10000 {
sum += j
}
println("Thread ${i} completed with result: ${sum}")
}
handles.append(handle)
}
// 等待所有线程完成
for handle in handles {
handle.join()
}
println("All 1000 threads completed")
}
在这个示例中,我们创建了1000个仓颉线程,但实际上它们可能只在4-8个native线程上执行(取决于CPU核数)。运行时调度器负责在这些native线程之间动态分配仓颉线程的执行时机。
更复杂的场景涉及线程间的通信和协作:
import std.sync.*
// 生产者-消费者模式展示M:N调度
func producerConsumer() {
let queue = ConcurrentQueue<Int64>()
let producerCount = 10
let consumerCount = 5
let itemsPerProducer = 100
// 创建多个生产者
let producers = Array<Thread>()
for i in 0..producerCount {
let producer = spawn {
for j in 0..itemsPerProducer {
let item = i * itemsPerProducer + j
queue.enqueue(item)
println("Producer ${i} produced: ${item}")
}
}
producers.append(producer)
}
// 创建多个消费者
let consumers = Array<Thread>()
for i in 0..consumerCount {
let consumer = spawn {
var processed = 0
while (processed < (producerCount * itemsPerProducer / consumerCount)) {
if let item = queue.dequeue() {
println("Consumer ${i} consumed: ${item}")
processed += 1
}
}
}
consumers.append(consumer)
}
// 等待所有线程完成
for producer in producers { producer.join() }
for consumer in consumers { consumer.join() }
}
在这个生产者-消费者示例中,15个仓颉线程(10个生产者+5个消费者)会被调度器智能地分配到少量native线程上执行,当某个线程在等待队列时,调度器会将执行权交给其他就绪的线程。
运行时调度架构:多层协同的精密系统
仓颉线程的运行时包含了执行线程、监视器、处理器与调度器等几个部分。这种分层架构体现了对调度复杂度的系统性分解。让我们通过代码来理解这些组件如何协同工作:
import std.sync.*
import std.time.*
// 展示调度器如何处理不同类型的任务
func schedulerDemo() {
let mutex = ReentrantMutex()
let sharedCounter = AtomicInt(0)
// CPU密集型任务
let cpuIntensiveTask = spawn {
var result = 0
for i in 0..10000000 {
result += i * i
}
println("CPU intensive task result: ${result}")
}
// IO密集型任务(模拟网络请求)
let ioTasks = Array<Thread>()
for i in 0..20 {
let task = spawn {
println("IO task ${i} starting")
// 模拟IO等待
sleep(Duration.milliseconds(100))
println("IO task ${i} completed")
}
ioTasks.append(task)
}
// 需要锁的任务
let lockTasks = Array<Thread>()
for i in 0..10 {
let task = spawn {
// 尝试获取锁
mutex.lock()
try {
let current = sharedCounter.load()
// 模拟临界区操作
for j in 0..1000 {
let _ = current + j
}
sharedCounter.store(current + 1)
println("Lock task ${i} incremented counter to ${sharedCounter.load()}")
} finally {
mutex.unlock()
}
}
lockTasks.append(task)
}
// 等待所有任务完成
cpuIntensiveTask.join()
for task in ioTasks { task.join() }
for task in lockTasks { task.join() }
println("Final counter value: ${sharedCounter.load()}")
}
在这个示例中,调度器需要处理三种不同特征的任务:
- CPU密集型任务会占用较长的执行时间片
- IO密集型任务在sleep时会被挂起,执行线程继续调度其他任务
- 需要锁的任务在等待锁时会被挂起,避免无谓的CPU消耗
抢占式调度:协作与强制的平衡艺术
协程调度的一大难题是如何在保持轻量级的同时,避免协作式调度的饿死问题。仓颉通过引入抢占式调度机制,在协作与强制之间找到了平衡。让我们通过代码来展示这一机制:
import std.time.*
// 展示抢占式调度如何处理长时间运行的任务
func preemptionDemo() {
let startTime = DateTime.now()
// 任务1:长时间计算,但有安全点
let task1 = spawn {
var sum = 0
for i in 0..100000000 {
sum += i
// 每10000次迭代主动检查调度点
if (i % 10000 == 0) {
// 这里会插入安全点检查
let _ = 0 // 编译器会在此处插入调度检查
}
}
println("Task 1 completed: ${sum}")
}
// 任务2:需要及时响应的高优先级任务
let task2 = spawn {
sleep(Duration.milliseconds(100))
println("Task 2 executed at ${DateTime.now().subtract(startTime).totalMilliseconds()} ms")
}
// 任务3:另一个长时间计算
let task3 = spawn {
var product = 1
for i in 1..1000000 {
product = (product * i) % 1000000007
}
println("Task 3 completed: ${product}")
}
task1.join()
task2.join()
task3.join()
}
// 对比:没有合理安全点的恶性循环
func badPreemptionExample() {
let goodTask = spawn {
var count = 0
for i in 0..100000000 {
count += 1
// 定期让出CPU
if (i % 50000 == 0) {
// 主动协作点
}
}
println("Good task completed")
}
// 这种任务会长时间占用CPU,导致其他任务饿死
let poorTask = spawn {
var x = 1.0
// 纯计算循环,缺少安全点
while (x < 1000000000.0) {
x = x * 1.0000001
}
println("Poor task completed")
}
let urgentTask = spawn {
println("I need immediate response!")
}
goodTask.join()
poorTask.join()
urgentTask.join()
}
编译器会在适当位置插入安全点检查,但作为高级开发者,我们可以主动设计更好的协作点:
// 手动优化的长时间计算任务
func optimizedLongRunningTask(data: Array<Int64>): Int64 {
var result: Int64 = 0
let chunkSize = 10000
for chunkStart in 0..(data.size() / chunkSize) {
// 处理一个数据块
let chunkEnd = min((chunkStart + 1) * chunkSize, data.size())
for i in (chunkStart * chunkSize)..chunkEnd {
result += processDataPoint(data[i])
}
// 在数据块之间主动让出CPU
// 这为调度器提供了切换其他线程的机会
yield() // 显式协作点
}
return result
}
func processDataPoint(value: Int64): Int64 {
// 模拟复杂计算
var temp = value
for i in 0..100 {
temp = (temp * temp) % 1000000007
}
return temp
}
阻塞与异步:IO密集型场景的优化策略
协程调度的最大价值在于IO密集型应用。让我们通过实际的文件和网络IO示例来展示仓颉如何实现"同步编码、异步运行":
import std.io.*
import std.net.*
import std.time.*
// 传统阻塞式IO(会阻塞整个native线程)
func blockingIOExample() {
let startTime = DateTime.now()
// 顺序读取多个文件
let files = ["file1.txt", "file2.txt", "file3.txt"]
for filename in files {
let content = readFileBlocking(filename)
println("Read ${filename}: ${content.length} bytes")
}
let elapsed = DateTime.now().subtract(startTime)
println("Blocking IO took: ${elapsed.totalMilliseconds()} ms")
}
// 仓颉协程优化的并发IO
func concurrentIOExample() {
let startTime = DateTime.now()
let files = ["file1.txt", "file2.txt", "file3.txt"]
let readTasks = Array<Thread>()
// 并发读取所有文件
for filename in files {
let task = spawn {
// 看起来是同步代码,实际运行时异步执行
let content = readFileAsync(filename)
println("Read ${filename}: ${content.length} bytes")
}
readTasks.append(task)
}
// 等待所有读取完成
for task in readTasks {
task.join()
}
let elapsed = DateTime.now().subtract(startTime)
println("Concurrent IO took: ${elapsed.totalMilliseconds()} ms")
}
// 网络IO示例:并发HTTP请求
func concurrentHttpRequests() {
let urls = [
"https://api.example.com/data1",
"https://api.example.com/data2",
"https://api.example.com/data3",
"https://api.example.com/data4",
"https://api.example.com/data5"
]
let requests = Array<Thread>()
let results = ConcurrentHashMap<String, String>()
for url in urls {
let request = spawn {
try {
// 同步风格的代码,运行时自动异步化
let response = httpGet(url)
results.put(url, response.body)
println("Completed request to ${url}")
} catch (e: NetworkException) {
println("Failed to fetch ${url}: ${e.message}")
}
}
requests.append(request)
}
// 等待所有请求完成
for request in requests {
request.join()
}
println("Completed ${results.size()} requests")
}
// 混合IO和计算的复杂场景
func dataProcessingPipeline() {
let inputFiles = ["data1.csv", "data2.csv", "data3.csv"]
let processedResults = ConcurrentQueue<ProcessedData>()
// 阶段1:并发读取和解析文件
let parseTasks = Array<Thread>()
for filename in inputFiles {
let task = spawn {
// IO操作:异步读取
let rawData = readFileAsync(filename)
// CPU操作:解析数据
let parsed = parseCSV(rawData)
// IO操作:异步写入中间结果
writeToCache(filename, parsed)
println("Parsed ${filename}")
}
parseTasks.append(task)
}
for task in parseTasks { task.join() }
// 阶段2:并发处理数据
let processTasks = Array<Thread>()
for filename in inputFiles {
let task = spawn {
// IO操作:从缓存读取
let data = readFromCache(filename)
// CPU密集型:数据分析
let result = analyzeData(data)
processedResults.enqueue(result)
println("Processed ${filename}")
}
processTasks.append(task)
}
for task in processTasks { task.join() }
// 阶段3:汇总结果
let aggregateTask = spawn {
var totalRecords = 0
while let result = processedResults.dequeue() {
totalRecords += result.recordCount
}
println("Total records processed: ${totalRecords}")
}
aggregateTask.join()
}
在这些示例中,仓颉的调度器会智能地处理IO操作:当线程执行IO时,不会阻塞native线程,而是将该仓颉线程挂起,让native线程继续执行其他就绪的仓颉线程。
并发对象库:零成本抽象的调度协同
仓颉提供的并发数据结构与调度器深度集成,让我们通过实际代码来展示其用法:
import std.sync.*
import std.collection.*
// 展示各种并发原语的使用
func concurrencyPrimitivesDemo() {
// 1. 互斥锁示例
demonstrateMutex()
// 2. 并发哈希表示例
demonstrateConcurrentHashMap()
// 3. 并发队列示例
demonstrateConcurrentQueue()
// 4. 原子操作示例
demonstrateAtomics()
}
// 互斥锁:保护共享资源
func demonstrateMutex() {
let mutex = ReentrantMutex()
let sharedResource = SharedData(0)
let threads = Array<Thread>()
for i in 0..10 {
let thread = spawn {
for j in 0..1000 {
// 锁感知调度:获取失败时主动挂起
mutex.lock()
try {
sharedResource.value += 1
} finally {
mutex.unlock()
}
}
}
threads.append(thread)
}
for thread in threads { thread.join() }
println("Final value with mutex: ${sharedResource.value}") // 应该是10000
}
// 并发哈希表:细粒度锁实现
func demonstrateConcurrentHashMap() {
let concurrentMap = ConcurrentHashMap<String, Int64>()
let updateTasks = Array<Thread>()
// 多个线程并发更新不同的key
for i in 0..20 {
let task = spawn {
let key = "key_${i % 5}" // 5个不同的key
for j in 0..100 {
// 原子操作:读取-修改-写入
let current = concurrentMap.getOrElse(key, {0})
concurrentMap.put(key, current + 1)
}
}
updateTasks.append(task)
}
for task in updateTasks { task.join() }
// 并发读取
let readTasks = Array<Thread>()
for i in 0..5 {
let task = spawn {
let key = "key_${i}"
if let value = concurrentMap.get(key) {
println("${key}: ${value}")
}
}
readTasks.append(task)
}
for task in readTasks { task.join() }
}
// 并发队列:无锁实现
func demonstrateConcurrentQueue() {
let queue = ConcurrentQueue<WorkItem>()
// 生产者:快速入队,不会阻塞
let producers = Array<Thread>()
for i in 0..5 {
let producer = spawn {
for j in 0..100 {
let item = WorkItem(i, j)
queue.enqueue(item)
// 无锁操作,不会导致线程挂起
}
}
producers.append(producer)
}
// 消费者:并发出队
let consumers = Array<Thread>()
let processedCount = AtomicInt(0)
for i in 0..3 {
let consumer = spawn {
var localCount = 0
while (processedCount.load() < 500) {
if let item = queue.dequeue() {
processWorkItem(item)
localCount += 1
processedCount.fetchAdd(1)
}
}
println("Consumer ${i} processed ${localCount} items")
}
consumers.append(consumer)
}
for producer in producers { producer.join() }
for consumer in consumers { consumer.join() }
}
// 原子操作:最细粒度的并发控制
func demonstrateAtomics() {
let counter = AtomicInt(0)
let flag = AtomicBool(false)
let threads = Array<Thread>()
// 使用CAS(Compare-And-Swap)实现无锁计数
for i in 0..10 {
let thread = spawn {
for j in 0..1000 {
// 自旋直到CAS成功
var success = false
while (!success) {
let current = counter.load()
success = counter.compareAndSwap(current, current + 1)
// CAS失败时不会挂起线程,而是继续重试
}
}
}
threads.append(thread)
}
// 使用原子标志实现一次性操作
let initTask = spawn {
if (flag.compareAndSwap(false, true)) {
println("Initialization performed by this thread")
performExpensiveInit()
}
}
for thread in threads { thread.join() }
initTask.join()
println("Final atomic counter: ${counter.load()}")
}
// 高级示例:实现一个简单的任务池
class TaskPool {
let taskQueue: ConcurrentQueue<() -> Unit>
let workers: Array<Thread>
let running: AtomicBool
init(workerCount: Int) {
taskQueue = ConcurrentQueue<() -> Unit>()
workers = Array<Thread>()
running = AtomicBool(true)
// 创建工作线程
for i in 0..workerCount {
let worker = spawn {
workerLoop(i)
}
workers.append(worker)
}
}
func workerLoop(workerId: Int) {
while (running.load()) {
if let task = taskQueue.dequeue() {
try {
task()
} catch (e: Exception) {
println("Worker ${workerId} error: ${e.message}")
}
} else {
// 队列为空,主动让出CPU
sleep(Duration.milliseconds(1))
}
}
}
func submit(task: () -> Unit) {
taskQueue.enqueue(task)
}
func shutdown() {
running.store(false)
for worker in workers {
worker.join()
}
}
}
// 使用任务池
func taskPoolExample() {
let pool = TaskPool(workerCount: 4)
// 提交100个任务
for i in 0..100 {
pool.submit({
println("Executing task ${i}")
sleep(Duration.milliseconds(10))
println("Completed task ${i}")
})
}
// 等待一段时间让任务完成
sleep(Duration.seconds(5))
pool.shutdown()
}
线程取消:协作式终止的工程实践
仓颉的协作式线程取消机制需要线程主动检查取消状态。让我们通过代码来展示最佳实践:
import std.sync.*
import std.time.*
// 基本的线程取消示例
func basicCancellationExample() {
let cancellableTask = spawn {
var iteration = 0
while (!Thread.currentThread().isCancelled()) {
println("Working... iteration ${iteration}")
sleep(Duration.milliseconds(100))
iteration += 1
// 定期检查取消状态
if (iteration > 50) {
println("Task auto-completing after 50 iterations")
break
}
}
println("Task terminated gracefully")
}
// 主线程等待一段时间后取消任务
sleep(Duration.seconds(1))
cancellableTask.cancel()
cancellableTask.join()
}
// 优雅处理清理工作的取消
func cancellationWithCleanup() {
let file = openFile("temp_data.txt")
let mutex = ReentrantMutex()
let task = spawn {
try {
while (!Thread.currentThread().isCancelled()) {
mutex.lock()
try {
// 执行一些工作
file.write("Processing data...\n")
} finally {
mutex.unlock()
}
sleep(Duration.milliseconds(50))
}
} finally {
// 清理资源
println("Cleaning up resources")
mutex.lock()
try {
file.flush()
file.close()
} finally {
mutex.unlock()
}
}
}
sleep(Duration.milliseconds(500))
task.cancel()
task.join()
println("Task cancelled and cleaned up")
}
// 复杂的取消传播示例
func cancellationPropagation() {
let parentTask = spawn {
let childTasks = Array<Thread>()
try {
// 创建多个子任务
for i in 0..5 {
let child = spawn {
while (!Thread.currentThread().isCancelled()) {
println("Child ${i} working")
sleep(Duration.milliseconds(100))
}
println("Child ${i} cancelled")
}
childTasks.append(child)
}
// 父任务监控取消状态
while (!Thread.currentThread().isCancelled()) {
println("Parent monitoring")
sleep(Duration.milliseconds(200))
}
} finally {
// 父任务被取消时,取消所有子任务
println("Parent cancelled, cancelling children")
for child in childTasks {
child.cancel()
}
// 等待所有子任务完成清理
for child in childTasks {
child.join()
}
println("All children cleaned up")
}
}
sleep(Duration.seconds(1))
parentTask.cancel()
parentTask.join()
}
// 超时机制的实现
func timeoutExample() {
func runWithTimeout<T>(timeout: Duration, task: () -> T): Option<T> {
let result = AtomicOption<T>()
let completed = AtomicBool(false)
let worker = spawn {
let value = task()
result.store(Some(value))
completed.store(true)
}
let timer = spawn {
sleep(timeout)
if (!completed.load()) {
println("Task timed out, cancelling")
worker.cancel()
}
}
worker.join()
timer.cancel()
timer.join()
return result.load()
}
// 使用超时运行任务
let result = runWithTimeout(Duration.seconds(2), {
// 模拟长时间运行的任务
var sum = 0
for i in 0..1000000 {
sum += i
if (Thread.currentThread().isCancelled()) {
println("Long task cancelled")
return -1
}
}
return sum
})
match (result) {
case Some(value) => println("Task completed with result: ${value}")
case None => println("Task was cancelled or timed out")
}
}
性能基准测试:量化调度开销
让我们通过实际的基准测试代码来量化协程调度的性能特征:
import std.time.*
import std.sync.*
// 基准测试框架
struct BenchmarkResult {
let name: String
let iterations: Int64
let totalTime: Duration
let avgTimePerOp: Duration
let throughput: Float64 // operations per second
}
func benchmark(name: String, iterations: Int64, operation: () -> Unit): BenchmarkResult {
let startTime = DateTime.now()
for i in 0..iterations {
operation()
}
let totalTime = DateTime.now().subtract(startTime)
let avgTime = Duration.microseconds(totalTime.totalMicroseconds() / iterations)
let throughput = iterations.toFloat64() / totalTime.totalSeconds()
return BenchmarkResult(name, iterations, totalTime, avgTime, throughput)
}
// 测试1:线程创建和销毁开销
func benchmarkThreadCreation() {
println("=== Thread Creation Benchmark ===")
let result = benchmark("Thread Creation", 10000, {
let thread = spawn {
let _ = 1 + 1 // 最小化工作量
}
thread.join()
})
println("Iterations: ${result.iterations}")
println("Total time: ${result.totalTime.totalMilliseconds()} ms")
println("Avg time per operation: ${result.avgTimePerOp.totalMicroseconds()} µs")
println("Throughput: ${result.throughput} ops/sec")
}
// 测试2:上下文切换开销
func benchmarkContextSwitch() {
println("\n=== Context Switch Benchmark ===")
let barrier = CyclicBarrier(2)
let iterations: Int64 = 100000
let startTime = DateTime.now()
let thread1 = spawn {
for i in 0..iterations {
barrier.await() // 强制上下文切换
}
}
let thread2 = spawn {
for i in 0..iterations {
barrier.await() // 强制上下文切换
}
}
thread1.join()
thread2.join()
let totalTime = DateTime.now().subtract(startTime)
let avgSwitchTime = totalTime.totalMicroseconds() / (iterations * 2)
println("Context switches: ${iterations * 2}")
println("Total time: ${totalTime.totalMilliseconds()} ms")
println("Avg switch time: ${avgSwitchTime} µs")
}
// 测试3:并发队列性能
func benchmarkConcurrentQueue() {
println("\n=== Concurrent Queue Benchmark ===")
let queue = ConcurrentQueue<Int64>()
let iterations: Int64 = 1000000
let producerCount = 4
let consumerCount = 4
let startTime = DateTime.now()
// 生产者线程
let producers = Array<Thread>()
for i in 0..producerCount {
let producer = spawn {
let itemsPerProducer = iterations / producerCount
for j in 0..itemsPerProducer {
queue.enqueue(i * itemsPerProducer + j)
}
}
producers.append(producer)
}
// 消费者线程
let consumers = Array<Thread>()
let consumedCount = AtomicInt(0)
for i in 0..consumerCount {
let consumer = spawn {
while (consumedCount.load() < iterations) {
if let _ = queue.dequeue() {
consumedCount.fetchAdd(1)
}
}
}
consumers.append(consumer)
}
for producer in producers { producer.join() }
for consumer in consumers { consumer.join() }
let totalTime = DateTime.now().subtract(startTime)
let throughput = iterations.toFloat64() / totalTime.totalSeconds()
println("Total operations: ${iterations}")
println("Total time: ${totalTime.totalMilliseconds()} ms")
println("Throughput: ${throughput} ops/sec")
}
// 测试4:CPU密集 vs IO密集对比
func benchmarkCpuVsIo() {
println("\n=== CPU vs IO Intensive Benchmark ===")
let threadCount = 100
// CPU密集型测试
let cpuStartTime = DateTime.now()
let cpuTasks = Array<Thread>()
for i in 0..threadCount {
let task = spawn {
var sum = 0
for j in 0..100000 {
sum += j * j
}
}
cpuTasks.append(task)
}
for task in cpuTasks { task.join() }
let cpuTime = DateTime.now().subtract(cpuStartTime)
// IO密集型测试
let ioStartTime = DateTime.now()
let ioTasks = Array<Thread>()
for i in 0..threadCount {
let task = spawn {
sleep(Duration.milliseconds(10)) // 模拟IO等待
}
ioTasks.append(task)
}
for task in ioTasks { task.join() }
let ioTime = DateTime.now().subtract(ioStartTime)
println("CPU intensive (${threadCount} threads):")
println(" Total time: ${cpuTime.totalMilliseconds()} ms")
println(" Time per thread: ${cpuTime.totalMilliseconds() / threadCount} ms")
println("IO intensive (${threadCount} threads):")
println(" Total time: ${ioTime.totalMilliseconds()} ms")
println(" Time per thread: ${ioTime.totalMilliseconds() / threadCount} ms")
println(" Speedup from concurrency: ${(threadCount * 10.0) / ioTime.totalMilliseconds()}x")
}
// 运行所有基准测试
func runAllBenchmarks() {
benchmarkThreadCreation()
benchmarkContextSwitch()
benchmarkConcurrentQueue()
benchmarkCpuVsIo()
}
最佳实践示例集锦
最后,让我们通过一个综合示例来展示协程调度的最佳实践:
import std.sync.*
import std.collection.*
import std.time.*
// 实战案例:高性能Web服务器请求处理
class RequestHandler {
let connectionPool: ConnectionPool
let cache: ConcurrentHashMap<String, CachedResponse>
let requestQueue: ConcurrentQueue<Request>
let workerPool: Array<Thread>
let metrics: AtomicMetrics
init(workerCount: Int) {
connectionPool = ConnectionPool(maxSize: 100)
cache = ConcurrentHashMap<String, CachedResponse>()
requestQueue = ConcurrentQueue<Request>()
workerPool = Array<Thread>()
metrics = AtomicMetrics()
// 创建工作线程池
for i in 0..workerCount {
let worker = spawn {
workerLoop(i)
}
workerPool.append(worker)
}
}
func workerLoop(workerId: Int) {
while (true) {
if let request = requestQueue.dequeue() {
handleRequest(workerId, request)
} else {
// 队列为空,短暂休眠避免busy-wait
sleep(Duration.milliseconds(1))
}
// 定期检查取消状态
if (Thread.currentThread().isCancelled()) {
println("Worker ${workerId} shutting down")
break
}
}
}
func handleRequest(workerId: Int, request: Request) {
let startTime = DateTime.now()
try {
// 1. 检查缓存(无锁读取)
if let cached = cache.get(request.url) {
if (!cached.isExpired()) {
metrics.cacheHit()
sendResponse(request, cached.data)
return
}
}
metrics.cacheMiss()
// 2. 从连接池获取连接(可能阻塞)
let connection = connectionPool.acquire()
try {
// 3. 执行IO操作(自动异步化)
let response = connection.fetchData(request.url)
// 4. 更新缓存
cache.put(request.url, CachedResponse(response, Duration.minutes(5)))
// 5. 发送响应
sendResponse(request, response)
} finally {
// 6. 归还连接
connectionPool.release(connection)
}
} catch (e: Exception) {
println("Worker ${workerId} error: ${e.message}")
sendError(request, e)
} finally {
let elapsed = DateTime.now().subtract(startTime)
metrics.recordLatency(elapsed)
}
}
func submitRequest(request: Request) {
requestQueue.enqueue(request)
}
func shutdown() {
println("Shutting down request handler")
// 取消所有工作线程
for worker in workerPool {
worker.cancel()
}
// 等待所有线程完成
for worker in workerPool {
worker.join()
}
connectionPool.closeAll()
metrics.printSummary()
}
}
// 指标收集器
class AtomicMetrics {
let totalRequests: AtomicInt
let cacheHits: AtomicInt
let cacheMisses: AtomicInt
let totalLatency: AtomicInt64 // microseconds
init() {
totalRequests = AtomicInt(0)
cacheHits = AtomicInt(0)
cacheMisses = AtomicInt(0)
totalLatency = AtomicInt64(0)
}
func cacheHit() {
totalRequests.fetchAdd(1)
cacheHits.fetchAdd(1)
}
func cacheMiss() {
totalRequests.fetchAdd(1)
cacheMisses.fetchAdd(1)
}
func recordLatency(duration: Duration) {
totalLatency.fetchAdd(duration.totalMicroseconds())
}
func printSummary() {
let total = totalRequests.load()
let hits = cacheHits.load()
let avgLatency = totalLatency.load() / total
println("=== Performance Metrics ===")
println("Total requests: ${total}")
println("Cache hit rate: ${(hits * 100 / total)}%")
println("Average latency: ${avgLatency} µs")
}
}
// 使用示例
func webServerExample() {
let handler = RequestHandler(workerCount: 8)
// 模拟大量并发请求
let requestSenders = Array<Thread>()
for i in 0..20 {
let sender = spawn {
for j in 0..50 {
let url = "https://api.example.com/data${j % 10}"
handler.submitRequest(Request(url))
sleep(Duration.milliseconds(10))
}
}
requestSenders.append(sender)
}
// 等待所有请求发送完成
for sender in requestSenders {
sender.join()
}
// 等待处理完成
sleep(Duration.seconds(5))
handler.shutdown()
}
结语
仓颉的协程调度机制体现了对并发编程本质的深刻理解。通过M:N线程模型、抢占式调度、异步IO集成、调度感知的并发数据结构,仓颉在保持轻量级的同时,实现了接近操作系统线程的功能完备性。本文通过大量实战代码示例,从线程创建、上下文切换、IO处理、并发控制到性能基准测试,全面展示了如何在实际项目中驾驭这一强大的调度系统。深入理解这些机制和代码模式,能够帮助高级开发者写出更高效、更健壮的并发应用,为鸿蒙生态的高性能开发奠定坚实基础。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)