
【GitHub项目推荐--MindSpore:新一代深度学习框架】
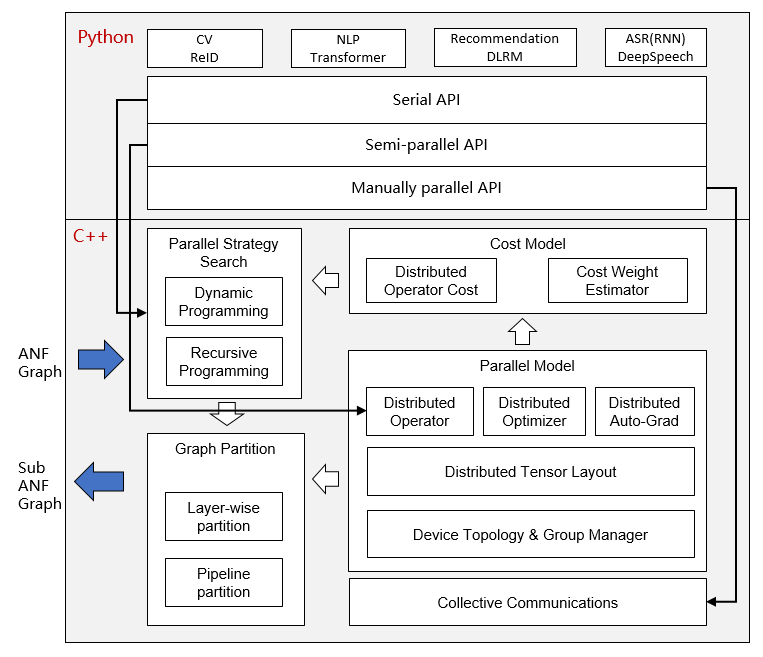
MindSpore 是一个开源的深度学习训练/推理框架,支持移动端、边缘端和云端场景。MindSpore旨在为数据科学家和算法工程师提供友好的开发体验和高效的执行性能,原生支持昇腾AI处理器,并实现软硬件协同优化。🔗 GitHub地址🧠 核心价值:深度学习框架 · 全场景支持 · 昇腾原生 · 自动微分 · 自动并行项目背景:AI框架需求:新一代AI框架需求全场景支持:移
简介
MindSpore 是一个开源的深度学习训练/推理框架,支持移动端、边缘端和云端场景。MindSpore旨在为数据科学家和算法工程师提供友好的开发体验和高效的执行性能,原生支持昇腾AI处理器,并实现软硬件协同优化。
🔗 GitHub地址:
https://github.com/mindspore-ai/mindspore
🧠 核心价值:
深度学习框架 · 全场景支持 · 昇腾原生 · 自动微分 · 自动并行
项目背景:
-
AI框架需求:新一代AI框架需求
-
全场景支持:移动边缘云全场景支持
-
硬件协同:软硬件协同优化需求
-
开发体验:开发者友好体验需求
-
开源生态:开源AI生态建设
项目特色:
-
🌐 全场景:移动边缘云全场景
-
⚡ 高性能:高性能计算优化
-
🤖 自动微分:源码转换自动微分
-
🔄 自动并行:自动分布式并行
-
🛡️ 安全可靠:企业级安全可靠
技术亮点:
-
源码转换:基于源码转换的自动微分
-
动静结合:动态图静态图统一
-
自动并行:智能自动并行策略
-
昇腾原生:昇腾处理器原生支持
-
端边云协同:端边云协同训练推理
主要功能
1. 核心功能体系
MindSpore提供了一套完整的深度学习解决方案,涵盖自动微分、自动并行、动静结合、模型训练、模型推理、模型部署、移动端支持、边缘计算、云端训练、可视化调试、性能分析、安全加密等多个方面。
自动微分功能:
微分能力:
- 源码转换: 基于源码转换的自动微分
- 动静统一: 动态图和静态图统一
- 控制流: 支持复杂控制流
- 高阶导数: 高阶导数计算
- 自定义导数: 自定义导数规则
微分特性:
- 精度高: 高精度梯度计算
- 性能好: 高性能微分计算
- 灵活性强: 高度灵活性支持
- 可调试: 易于调试和验证
- 可扩展: 易于扩展新算子
技术优势:
- 编译优化: 编译时优化梯度图
- 内存优化: 内存使用优化
- 速度优化: 计算速度优化
- 稳定性: 数值稳定性保证
- 兼容性: 良好兼容性支持自动并行功能:
并行能力:
- 数据并行: 数据并行训练
- 模型并行: 模型并行训练
- 流水并行: 流水线并行训练
- 混合并行: 混合并行策略
- 自动选择: 自动最优策略选择
并行特性:
- 自动化: 全自动并行策略
- 智能化: 智能策略选择
- 高效性: 高效并行执行
- 可配置: 灵活配置支持
- 可扩展: 扩展并行模式
优化技术:
- 算子拆分: 细粒度算子拆分
- 通信优化: 通信效率优化
- 内存优化: 内存使用优化
- 负载均衡: 负载均衡优化
- 容错处理: 容错机制支持动静结合功能:
运行模式:
- 动态图模式: 即时执行模式
- 静态图模式: 图编译模式
- 混合模式: 动静混合模式
- 灵活切换: 模式灵活切换
- 统一接口: 统一编程接口
模式优势:
- 开发调试: 动态图便于调试
- 生产性能: 静态图高性能
- 灵活选择: 根据需求选择
- 无缝转换: 无缝模式转换
- 最佳体验: 最佳开发体验
应用场景:
- 实验开发: 动态图快速实验
- 生产部署: 静态图高效部署
- 算法研究: 灵活算法实现
- 性能优化: 极致性能追求
- 多场景: 多种场景适配2. 高级功能
全场景支持功能:
场景支持:
- 移动端: 手机等移动设备
- 边缘端: 边缘计算设备
- 云端: 云服务器训练
- 物联网: IoT设备支持
- 嵌入式: 嵌入式设备
统一架构:
- 统一API: 统一编程接口
- 统一模型: 统一模型格式
- 统一工具: 统一开发工具
- 统一生态: 统一开发生态
- 统一体验: 一致开发体验
协同能力:
- 协同训练: 端边云协同训练
- 协同推理: 端边云协同推理
- 模型迁移: 模型无缝迁移
- 数据协同: 数据协同处理
- 资源协同: 计算资源协同昇腾优化功能:
硬件支持:
- 昇腾原生: 昇腾处理器原生支持
- 性能优化: 深度性能优化
- 功能特化: 专用功能特化
- 能效优化: 能效比优化
- 可靠性: 高可靠性保证
优化技术:
- 算子优化: 昇腾算子优化
- 内存优化: 内存访问优化
- 通信优化: 芯片间通信优化
- 调度优化: 任务调度优化
- 功耗优化: 功耗管理优化
开发支持:
- 工具链: 完整开发工具链
- 调试工具: 专用调试工具
- 性能分析: 性能分析工具
- 文档支持: 详细文档支持
- 社区支持: 活跃社区支持安全加密功能:
安全能力:
- 数据加密: 训练数据加密
- 模型加密: 模型参数加密
- 通信加密: 分布式通信加密
- 隐私保护: 用户隐私保护
- 安全审计: 安全审计日志
加密技术:
- 同态加密: 同态加密计算
- 差分隐私: 差分隐私保护
- 安全多方: 安全多方计算
- 可信执行: 可信执行环境
- 区块链: 区块链存证
企业级安全:
- 合规认证: 安全合规认证
- 访问控制: 细粒度访问控制
- 审计追踪: 操作审计追踪
- 漏洞管理: 安全漏洞管理
- 应急响应: 安全应急响应安装与配置
1. 环境准备
系统要求:
支持平台:
- Linux: Ubuntu, EulerOS, CentOS
- Windows: Windows 10+
- Android: 移动端支持
- 其他: 其他Linux发行版
硬件要求:
- CPU: x86/x86_64, ARM64
- GPU: NVIDIA GPU(CUDA)
- NPU: 昇腾处理器
- 其他: 其他AI加速器
软件要求:
- Python: Python 3.7+
- pip: pip包管理器
- 编译器: GCC等编译工具
- 依赖库: 相关依赖库
网络要求:
- 互联网: 包下载和更新
- 代理支持: 网络代理配置
- 镜像源: 镜像加速支持
- 离线安装: 离线安装支持
开发工具:
- IDE: VS Code, PyCharm等
- 调试器: 调试工具支持
- 性能工具: 性能分析工具
- 可视化: 可视化工具硬件支持:
处理器支持:
- 昇腾910: 昇腾910处理器
- 昇腾310: 昇腾310处理器
- NVIDIA GPU: 支持CUDA的GPU
- Intel CPU: x86/x86_64 CPU
- ARM CPU: ARM架构CPU
- 其他NPU: 其他神经网络处理器
加速器支持:
- 昇腾系列: 全系列昇腾处理器
- GPU系列: NVIDIA全系列GPU
- 云端加速: 云端AI加速器
- 边缘加速: 边缘AI加速器
- 移动加速: 移动AI加速器
网络支持:
- RDMA: 高速RDMA网络
- Ethernet: 千兆万兆以太网
- 无线网络: WiFi, 5G等
- 专有网络: 专有AI计算网络2. 安装步骤
pip安装:
# CPU版本安装
pip install mindspore
# GPU(CUDA)版本安装
pip install mindspore-gpu
# 昇腾版本安装
pip install mindspore-ascend
# 指定版本安装
pip install mindspore==2.0.0
# 升级版本
pip install --upgrade mindspore
# 验证安装
python -c "import mindspore; print(f'MindSpore {mindspore.__version__}')"源码编译安装:
# 克隆仓库
git clone https://github.com/mindspore-ai/mindspore.git
cd mindspore
# 安装依赖
pip install -r requirements.txt
# 编译安装
bash build.sh -e cpu -j 4 # CPU版本
bash build.sh -e gpu -j 4 # GPU版本
bash build.sh -e ascend -j 4 # 昇腾版本
# 安装whl包
pip install output/mindspore-*.whl
# 验证安装
python -c "import mindspore; print('安装成功')"Docker安装:
# CPU Docker镜像
docker pull mindspore/mindspore-cpu:latest
docker run -it mindspore/mindspore-cpu:latest
# GPU Docker镜像
docker pull mindspore/mindspore-gpu:latest
docker run -it --runtime=nvidia mindspore/mindspore-gpu:latest
# 昇腾Docker镜像
docker pull mindspore/mindspore-ascend:latest
docker run -it -v /usr/local/Ascend/driver:/usr/local/Ascend/driver mindspore/mindspore-ascend:latest
# 验证Docker安装
docker run --rm mindspore/mindspore-cpu:latest python -c "import mindspore; print('Docker安装成功')"验证安装:
# 基本功能验证
python -c "
import mindspore as ms
import numpy as np
from mindspore import Tensor
# 创建张量
x = Tensor(np.ones([2, 3]))
print('张量创建成功:', x.shape)
# 简单计算
y = x + x
print('计算成功:', y.shape)
print('MindSpore基本功能正常')
"
# 版本信息检查
python -c "import mindspore; print(f'版本: {mindspore.__version__}')"
# 设备支持检查
python -c "
import mindspore as ms
context = ms.context.get_context()
print('运行上下文:', context)
"3. 配置说明
基础配置:
# 运行配置示例
import mindspore as ms
from mindspore import context
# 设置运行模式
context.set_context(
mode=context.GRAPH_MODE, # 静态图模式
# mode=context.PYNATIVE_MODE, # 动态图模式
device_target="CPU", # 设备类型: CPU, GPU, Ascend
device_id=0 # 设备ID
)
# 内存优化配置
context.set_context(
memory_optimize_level="O1", # 内存优化级别
max_device_memory="3GB", # 最大设备内存
variable_memory_max_size="1GB" # 变量内存限制
)
# 性能配置
context.set_context(
enable_auto_mixed_precision=True, # 自动混合精度
enable_graph_kernel=True, # 图算融合
enable_reduce_precision=True # 精度降低优化
)分布式配置:
# 分布式训练配置
from mindspore import context
from mindspore.communication import init
# 初始化分布式
init()
context.set_auto_parallel_context(
parallel_mode="data_parallel", # 并行模式: data_parallel, semi_auto_parallel, auto_parallel
gradients_mean=True, # 梯度平均
device_num=8, # 设备数量
parameter_broadcast=True # 参数广播
)
# 自动并行配置
context.set_auto_parallel_context(
parallel_mode="auto_parallel",
search_mode="dynamic_programming", # 策略搜索模式
auto_parallel_search_level=2, # 搜索级别
enable_parallel_optimizer=True, # 优化器并行
all_reduce_fusion_config=[8, 16] # 通信融合配置
)高级配置:
# 混合精度配置
from mindspore import amp
# 自动混合精度
amp_level = "O3" # O0: 全精度, O1: 部分混合精度, O2: 大部分混合精度, O3: 全混合精度
model = amp.build_train_network(
network,
optimizer,
loss_fn,
level=amp_level,
loss_scale_manager=None
)
# 内存配置
from mindspore import context
context.set_context(
enable_mem_reuse=True, # 内存重用
mem_opt_type="mem_opt", # 内存优化类型
enable_mem_offload=True, # 内存卸载
enable_pinned_mem=True # 固定内存
)
# 调试配置
context.set_context(
save_graphs=True, # 保存计算图
save_graphs_path="./graphs", # 图保存路径
print_file_path="./logs", # 打印文件路径
enable_dump=True, # 启用dump
dump_path="./dump" # dump文件路径
)使用指南
1. 基本工作流
使用MindSpore的基本流程包括:环境准备 → 安装配置 → 项目创建 → 模型定义 → 数据准备 → 训练配置 → 训练执行 → 模型评估 → 模型导出 → 推理部署 → 性能优化 → 生产使用。
2. 基本使用
模型定义使用:
定义步骤:
1. 导入模块: 导入mindspore模块
2. 定义网络: 定义神经网络结构
3. 定义层: 定义网络层和算子
4. 定义前向: 定义前向传播逻辑
5. 创建实例: 创建网络实例
网络定义:
import mindspore.nn as nn
import mindspore.ops as ops
class MyNet(nn.Cell):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 64, 3)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2)
def construct(self, x):
x = self.conv(x)
x = self.relu(x)
x = self.pool(x)
return x
网络特性:
- Cell基类: 所有网络继承Cell
- construct方法: 定义前向传播
- 算子组合: 使用内置算子
- 参数管理: 自动参数管理
- 序列化: 支持序列化保存训练流程使用:
训练步骤:
1. 数据准备: 准备训练数据集
2. 模型定义: 定义模型结构
3. 损失函数: 定义损失函数
4. 优化器: 定义优化器
5. 训练循环: 编写训练循环
6. 模型保存: 保存训练模型
训练代码:
import mindspore as ms
from mindspore import dataset as ds
from mindspore.train import Model, LossMonitor
# 准备数据
dataset = create_dataset()
# 定义模型
model = MyNet()
# 定义损失函数
loss_fn = nn.SoftmaxCrossEntropyWithLogits()
# 定义优化器
optimizer = nn.Adam(model.trainable_params())
# 创建模型
model = Model(model, loss_fn, optimizer)
# 开始训练
model.train(epochs=10, train_dataset=dataset, callbacks=[LossMonitor()])推理部署使用:
推理步骤:
1. 加载模型: 加载训练好的模型
2. 准备数据: 准备推理数据
3. 执行推理: 执行模型推理
4. 处理结果: 处理推理结果
5. 部署优化: 优化部署性能
推理代码:
import mindspore as ms
from mindspore import Tensor
import numpy as np
# 加载模型
net = MyNet()
ms.load_checkpoint("model.ckpt", net)
# 准备数据
input_data = Tensor(np.random.randn(1, 3, 224, 224).astype(np.float32))
# 执行推理
output = net(input_data)
print("推理结果:", output.shape)
# 模型导出
ms.export(net, input_data, file_name="model", file_format="MINDIR")3. 高级用法
自动并行使用:
并行配置:
1. 设置并行模式: 设置自动并行
2. 配置策略: 配置并行策略
3. 初始化通信: 初始化分布式通信
4. 训练执行: 执行分布式训练
5. 监控调试: 监控训练过程
自动并行:
from mindspore import context
from mindspore.communication import init
# 初始化分布式
init()
context.set_auto_parallel_context(
parallel_mode="auto_parallel",
device_num=8,
gradients_mean=True
)
# 定义并行网络
class ParallelNet(nn.Cell):
def __init__(self):
super().__init__()
self.layer1 = nn.Dense(1024, 2048)
self.layer2 = nn.Dense(2048, 4096)
def construct(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
# 自动并行训练
model = Model(ParallelNet(), loss_fn, optimizer)
model.train(epochs=10, train_dataset=dataset)混合精度使用:
精度配置:
1. 选择精度级别: 选择混合精度级别
2. 配置网络: 配置混合精度网络
3. 训练执行: 执行混合精度训练
4. 精度监控: 监控训练精度
5. 性能优化: 优化训练性能
混合精度:
from mindspore import amp
# 定义网络和优化器
net = MyNet()
loss_fn = nn.SoftmaxCrossEntropyWithLogits()
optimizer = nn.Adam(net.trainable_params())
# 构建混合精度网络
net = amp.build_train_network(
net,
optimizer,
loss_fn,
level="O2",
loss_scale_manager=None
)
# 混合精度训练
model = Model(net)
model.train(epochs=10, train_dataset=dataset)端边云协同使用:
协同流程:
1. 云端训练: 在云端训练模型
2. 模型压缩: 模型压缩和优化
3. 边缘部署: 部署到边缘设备
4. 协同推理: 端边云协同推理
5. 联邦学习: 联邦学习训练
协同代码:
# 云端训练
cloud_net = train_on_cloud()
# 模型压缩
compressed_net = compress_model(cloud_net)
# 边缘部署
deploy_to_edge(compressed_net)
# 协同推理
edge_result = inference_on_edge(data)
cloud_result = inference_on_cloud(complex_data)
# 结果融合
final_result = fuse_results(edge_result, cloud_result)应用场景实例
案例1:图像分类任务
场景:大规模图像分类任务
解决方案:使用MindSpore进行高效图像分类。
实施方法:
-
数据准备:准备ImageNet等数据集
-
模型选择:选择ResNet等模型
-
训练配置:配置训练参数和策略
-
分布式训练:使用自动并行训练
-
模型评估:评估模型性能
-
部署应用:部署到生产环境
分类价值:
-
精度高:高分类精度
-
效率高:训练推理效率高
-
可扩展:支持大规模训练
-
易部署:易于部署应用
-
性能优:优异性能表现
案例2:自然语言处理
场景:自然语言处理任务
解决方案:使用MindSpore进行NLP任务。
实施方法:
-
文本处理:文本数据预处理
-
模型构建:构建Transformer等模型
-
预训练:大规模预训练
-
微调:任务特定微调
-
推理部署:部署NLP服务
-
性能优化:优化推理性能
NLP价值:
-
效果好:优异NLP效果
-
效率高:高效训练推理
-
支持广:支持多种NLP任务
-
生态好:丰富NLP生态
-
易用性好:良好易用性
案例3:推荐系统
场景:个性化推荐系统
解决方案:使用MindSpore构建推荐系统。
实施方法:
-
数据准备:用户行为数据准备
-
特征工程:特征提取和处理
-
模型设计:设计推荐模型
-
分布式训练:大规模分布式训练
-
实时推理:实时推荐推理
-
系统部署:推荐系统部署
推荐价值:
-
个性化:精准个性化推荐
-
实时性:实时推荐能力
-
可扩展:支持大规模用户
-
效果好:推荐效果优异
-
效率高:高效训练推理
案例4:科学计算
场景:科学计算和模拟
解决方案:使用MindSpore进行科学计算。
实施方法:
-
问题建模:科学问题建模
-
算法实现:实现计算算法
-
高性能计算:利用高性能计算
-
结果分析:计算结果分析
-
可视化:结果可视化展示
-
应用部署:部署计算应用
科学价值:
-
性能高:高性能计算能力
-
精度高:高计算精度
-
易用性好:良好易用性
-
支持广:支持多种科学计算
-
创新强:促进科学研究创新
案例5:移动端AI
场景:移动端AI应用
解决方案:使用MindSpore部署移动端AI。
实施方法:
-
模型训练:云端模型训练
-
模型压缩:模型压缩和优化
-
移动部署:部署到移动设备
-
推理优化:移动端推理优化
-
应用集成:集成到移动应用
-
性能监控:监控应用性能
移动价值:
-
离线能力:离线推理能力
-
实时性好:实时推理响应
-
功耗低:低功耗运行
-
体验好:良好用户体验
-
隐私保护:数据隐私保护
总结
MindSpore作为一个新一代的深度学习框架,通过其全场景支持、自动微分、自动并行和软硬件协同优化等特性,为深度学习开发提供了完整的解决方案。
核心优势:
-
🌐 全场景:移动边缘云全场景支持
-
⚡ 高性能:高性能计算优化
-
🤖 自动微分:源码转换自动微分
-
🔄 自动并行:智能自动并行
-
🛡️ 安全可靠:企业级安全可靠
适用场景:
-
图像分类和识别
-
自然语言处理
-
推荐系统
-
科学计算
-
移动端AI应用
立即开始使用:
# 安装MindSpore
pip install mindspore
# 验证安装
python -c "import mindspore; print('安装成功')"
# 运行示例
python -c "
import mindspore as ms
from mindspore import Tensor
import numpy as np
x = Tensor(np.ones([2, 3]))
print('张量创建成功:', x.shape)
"资源链接:
-
🌐 项目地址:GitHub仓库
-
📖 文档:官方文档
-
💡 示例:代码示例库
-
💬 社区:社区讨论
-
🐛 问题:问题反馈
通过MindSpore,您可以:
-
全场景开发:全场景AI开发
-
高效训练:高效模型训练
-
智能并行:智能自动并行
-
轻松部署:轻松部署应用
-
协同优化:软硬件协同优化
特别提示:
-
🐍 Python基础:需要Python基础
-
🧠 深度学习:需要深度学习知识
-
🖥️ 硬件环境:注意硬件兼容性
-
🔧 配置学习:需要学习配置使用
-
📊 性能调优:需要性能调优经验
通过MindSpore,提升您的AI开发能力!
未来发展:
-
🚀 更多功能:持续功能增强
-
🤖 更智能:更智能的优化
-
🌐 更广支持:更广泛硬件支持
-
🔧 更易用:更友好用户体验
-
📊 更强性能:更强性能表现
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 文档贡献: 贡献文档改进
- 示例分享: 分享使用示例
- 问题反馈: 反馈使用问题
- 功能建议: 提出功能建议
社区价值:
- 技术支持帮助
- 问题解答支持
- 经验分享交流
- 功能需求反馈
- 项目发展推动通过MindSpore,共同推动AI发展!
许可证:Apache-2.0许可证
致谢:感谢MindSpore团队和所有贡献者
免责声明:注意合理使用和资源管理
通过MindSpore,构建智能的未来!
成功案例:
用户群体:
- 研究人员: 学术研究项目
- 工程师: 工业界应用开发
- 学生: 学习研究和实验
- 企业: 企业级应用部署
- 开发者: 开源项目开发
使用效果:
- 效率提升: 开发效率显著提升
- 性能优异: 运行性能优异
- 易用性好: 框架易用性好
- 推荐度高: 用户推荐度高
- 影响广泛: 行业影响广泛最佳实践:
使用建议:
1. 从简单开始: 从简单功能开始
2. 逐步深入: 逐步学习高级功能
3. 官方文档: 参考官方文档
4. 社区支持: 利用社区支持
5. 性能监控: 监控训练性能
避免问题:
- 配置错误: 避免配置参数错误
- 资源不足: 确保足够计算资源
- 版本冲突: 注意版本兼容性
- 内存溢出: 监控内存使用情况
- 数据问题: 检查数据质量通过MindSpore,实现高效的AI开发!
资源扩展:
学习资源:
- 深度学习理论基础
- Python编程技能
- 分布式系统知识
- 硬件加速器原理
- 性能优化技术通过MindSpore,构建您的AI未来!
未来展望:
技术发展:
- 更好性能
- 更多功能
- 更强集成
- 更易使用
- 更智能化
应用发展:
- 更多场景
- 更好体验
- 更广应用
- 更深影响
- 更大价值
社区发展:
- 更多用户
- 更多贡献
- 更好文档
- 更多案例
- 更大影响通过MindSpore,迎接AI的未来!
结束语:
MindSpore作为一个创新的深度学习框架,正在改变人们开发和部署AI应用的方式。通过合理利用这一工具,用户可以享受全场景支持、自动微分、自动并行和软硬件协同优化带来的好处。
记住,工具是扩展能力的手段,结合扎实的AI知识与合理的技术选择,共同成就技术卓越。
Happy AI developing with MindSpore! 🚀🧠✨
附录
常见问题解答
Q: MindSpore与PyTorch/TensorFlow的主要区别是什么?
A: MindSpore采用源码转换自动微分技术,支持动静统一,提供更好的性能和可扩展性,同时原生支持昇腾处理器。
Q: 如何选择运行模式(动态图/静态图)?
A: 动态图适合开发和调试,静态图适合生产部署。可以根据需求灵活切换。
Q: MindSpore支持哪些硬件平台?
A: 支持CPU、GPU(NVIDIA)、昇腾处理器、以及移动端和边缘设备。
Q: 如何进行分布式训练?
A: 通过设置自动并行上下文,MindSpore可以自动选择最优的并行策略。
Q: 如何部署到生产环境?
A: 可以使用MindSpore的模型导出功能,支持多种格式导出,并提供丰富的部署工具。
性能优化建议
训练优化:
-
使用自动混合精度训练
-
配置合适的并行策略
-
启用内存优化选项
-
使用数据预处理优化
-
配置适当的批处理大小
推理优化:
-
使用图模式推理
-
启用算子融合优化
-
使用模型量化技术
-
配置合适的线程数
-
使用硬件特定优化
内存优化:
-
使用梯度累积
-
启用激活检查点
-
配置内存重用
-
使用内存卸载
-
优化数据格式
故障排除指南
常见问题:
-
安装失败:检查Python版本和依赖
-
内存不足:减少批处理大小或使用内存优化
-
性能下降:检查配置和硬件状态
-
训练不收敛:调整学习率和优化器参数
-
分布式错误:检查网络和节点配置
调试工具:
-
MindInsight可视化工具
-
日志分析工具
-
性能分析工具
-
分布式调试工具
-
内存分析工具
扩展资源
学习路径:
-
掌握Python和深度学习基础
-
学习MindSpore核心概念
-
实践示例项目
-
探索高级功能
-
参与实际项目
进阶主题:
-
自定义算子开发
-
分布式训练优化
-
模型压缩量化
-
移动端部署
-
性能调优技术
社区资源:
-
GitHub仓库和问题讨论
-
官方文档和教程
-
技术博客和案例分享
-
社区论坛和讨论组
-
技术会议和研讨会
通过深入学习和实践,您可以充分发挥MindSpore的潜力,构建高效、可扩展的AI解决方案。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)