
小智AI机器人 - 语音代码梳理1
本篇主要是梳理和记录与语音相关功能的整体代码框架是怎么样的,有哪些模块它们又分别起到什么作用,先对与语音相关的整体代码结构有个初步的了解,这部分内容也比较多所以会分开来记录。
文章目录
前言
本篇主要是梳理和记录与语音相关功能的整体代码框架是怎么样的,有哪些模块它们又分别起到什么作用,先对与语音相关的整体代码结构有个初步的了解,这部分内容也比较多所以会分开来记录。
我个人感觉在熟悉代码时,先对整体有个初步了解之后,再看某个功能点的实现时(如语音唤醒、识别、语音输出),就能够站在更全面的角度去思考,以及很快意识到功能点对应的实现和其调用者分别在哪里,提高我们阅读和理解代码的实现逻辑。
前面的文章:
小智AI机器人 - 代码框架梳理1
小智AI机器人 - 代码框架梳理2
小智AI机器人 - 语音相关方案了解1(ESP-SR + SenseVoice)
小智AI机器人 - 语音相关方案了解2( 3D Speaker + 大模型 TTS )
小智AI 地址:
github地址
gitcode地址(这个国内访问起来比较快)
1. 简介
前面的文章我记录了自己对小智AI背后所使用到的语音相关算法和模型以及整体工作机制的了解。但是对于代码层面上是如何实现的还有无所知,而语音作为小智AI的核心功能这块我觉得还是非常重要的,通过了解小智AI是如何实现这些功能强大的语音功能,我们不仅能对语音相关开发有一定的了解。且后续做产品时,也能用到。
本篇先从整体来进行了解,后续再对不同功能点是如何实现的进行详细的梳理。例如先了解
- 语音相关的代码放在了哪里
- 语音相关的模块有哪些,它们的代码结构是怎么样的
- 语音相关的模块的功能和他们之间的关系
2. 语音相关的代码放在了哪里
与语音相关的小智AI中的代码,主要分布在这几个目录下。但是也有一些在esp-idf的components目录下,例如一些编解码芯片的驱动代码和算法的实现,这里的话 我们先不进行过多描述,先了解下xiaozhiAi下的代码。
整体上语音相关的被分成了3部分
- audio_codecs: 负责音频的编解码处理
- audio_processing: 负责对收到的语音数据进行处理,例如对音频数据进行算法处理、识别是否有人在说话、是否是唤醒词等。
- application: 应用的主逻辑代码都在这里的,它负责统筹各个模块让其相互配合。例如收到语音数据后通过当前是在
唤醒模式还是在对话模式来决定将输入的音频数据交给哪个模块处理。
接下来我们对这3部分分别进行拆解梳理。

3. audio_codes(音频编解码)
先不看代码,只看文件命名给人的感觉是该目录下放置的是声音编解码相关的代码。事实上也确实如此。
audio_codes提供了
- 音频输入/输出接口
- 支持不同音频芯片的驱动
- 实现音量控制、采样率设置等音频参数配置
3.1 代码基础结构
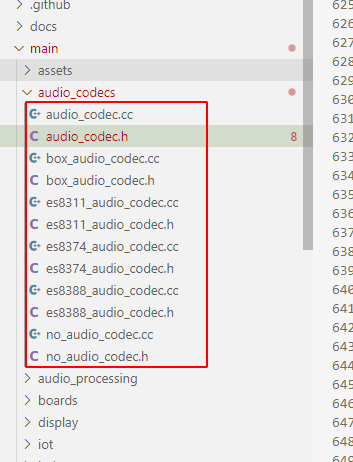
| 文件名 | 描述 |
|---|---|
audio_codec.h/cc |
定义音频编解码器的基类接口 |
box_audio_codec.h/cc |
Box设备(ESP32-Box)的音频编解码实现 |
es8311_audio_codec.h/cc |
ES8311芯片的驱动实现(低功耗、高性能的音频编解码器芯片) |
es8374_audio_codec.h/cc |
ES8374芯片的驱动实现 |
es8388_audio_codec.h/cc |
ES8388芯片的驱动实现 |
no_audio_codec.h/cc |
无音频编解码器的空实现 |
audio_code抽象类
audio_codec类是整个audio_code下所有音频编解码器的抽象类,我们不能直接实例化AudioCocec,需要有个派生类继承并实现audio_code类,然后我们再去实例化这个派生类。
简单来可以理解为audio_code抽象类定义了音频编解码所要提供的功能以及接口规范。为了更加容易适配不同的编解码器,就要求它们必须按照基类中定义的接口去实现和封装自己的接口。这样无论编解码器怎么变,应用层调用的接口都不会发生变化,从而做大将变化隔离到audio_codes内。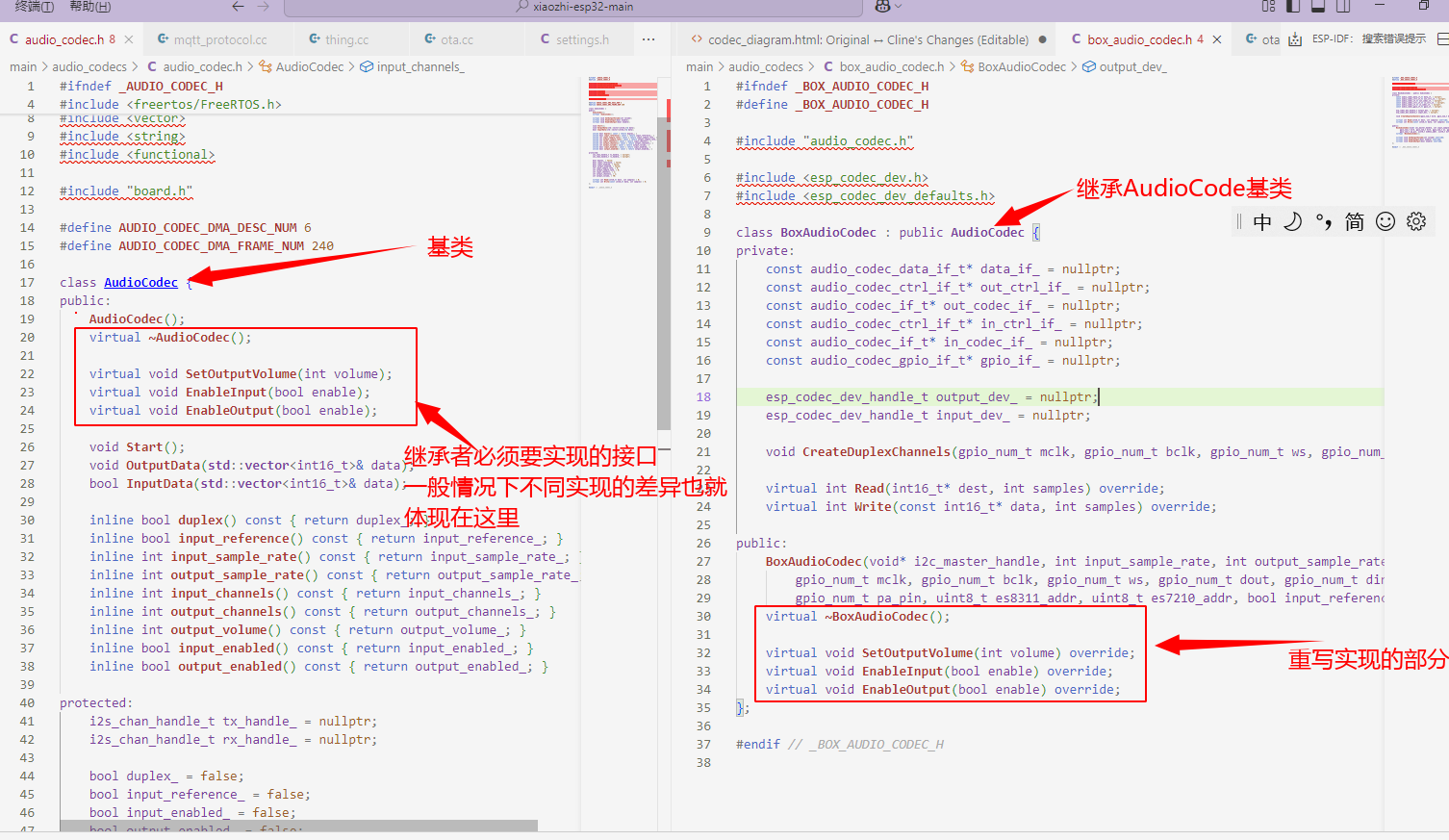
接口功能介绍
-
核心控制接口:
- SetOutputVolume(): 设置输出音量 - EnableInput(): 启用/禁用音频输入 - EnableOutput(): 启用/禁用音频输出 - Start(): 启动编解码器 - OutputData(): 输出音频数据 - InputData(): 获取输入音频数据 -
状态查询接口(内联函数):
- duplex(): 是否支持全双工模式 - input_reference(): 是否有输入参考信号 - input_sample_rate(): 获取输入采样率 - output_sample_rate(): 获取输出采样率 - input_channels(): 获取输入通道数 - output_channels(): 获取输出通道数 - output_volume(): 获取当前输出音量 - input_enabled(): 输入是否启用 - output_enabled(): 输出是否启用 -
纯虚函数(需子类实现):
- Read(): 从设备读取音频数据 - Write(): 向设备写入音频数据
这个抽象类为ESP32平台上的音频编解码器提供了统一接口,具体实现需要派生类完成(如box_audio_code.h等中的实现)。
关键特性:
- 基于FreeRTOS和ESP32 I2S驱动
- 支持DMA传输
- 默认配置为单声道
- 提供基本的音频通路控制
box_audio_code对象
我们以box_audio_code对象的实现为例子进行进一步的介绍。box_audio_code对应的是乐鑫自己开发的一款ESP32-S3开发板,好像叫做ESP32-BOX,而这里的box_audio_code.cc/h就是针对该款开发板实现的音频编解码。
这里针对BOX设备进行了一些特殊的实现优化:
- 集成回声消除算法
- 支持多麦克风阵列
- 提供硬件加速接口
box_audio_codec.h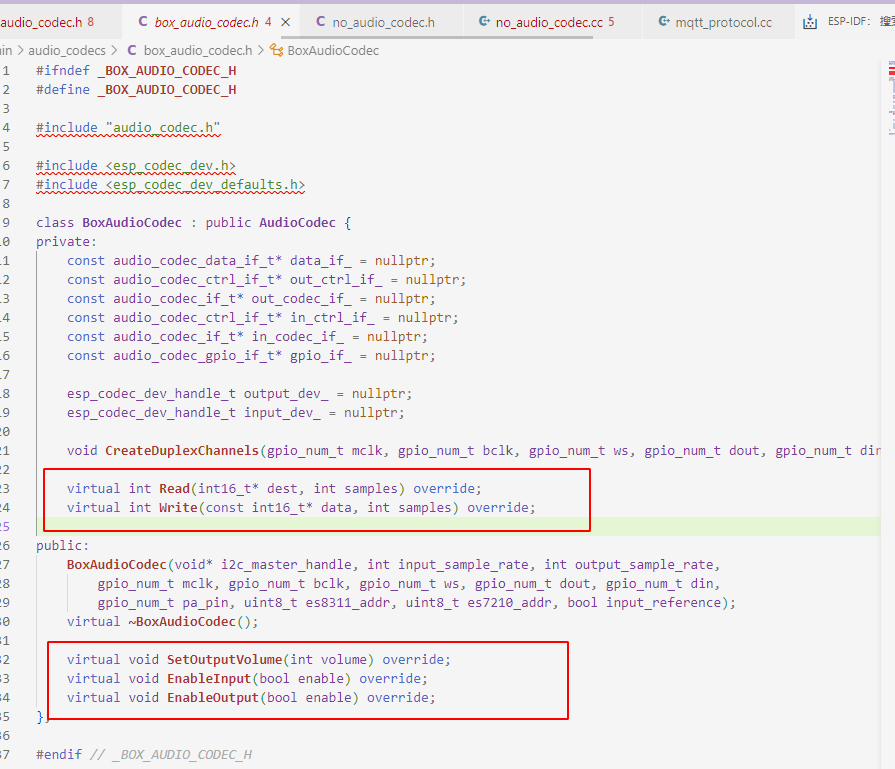
box继承了AudioCodec对象后,主要是重新实现了
- 音频数据的读写
- 输入输出的使能
- 音量的调节
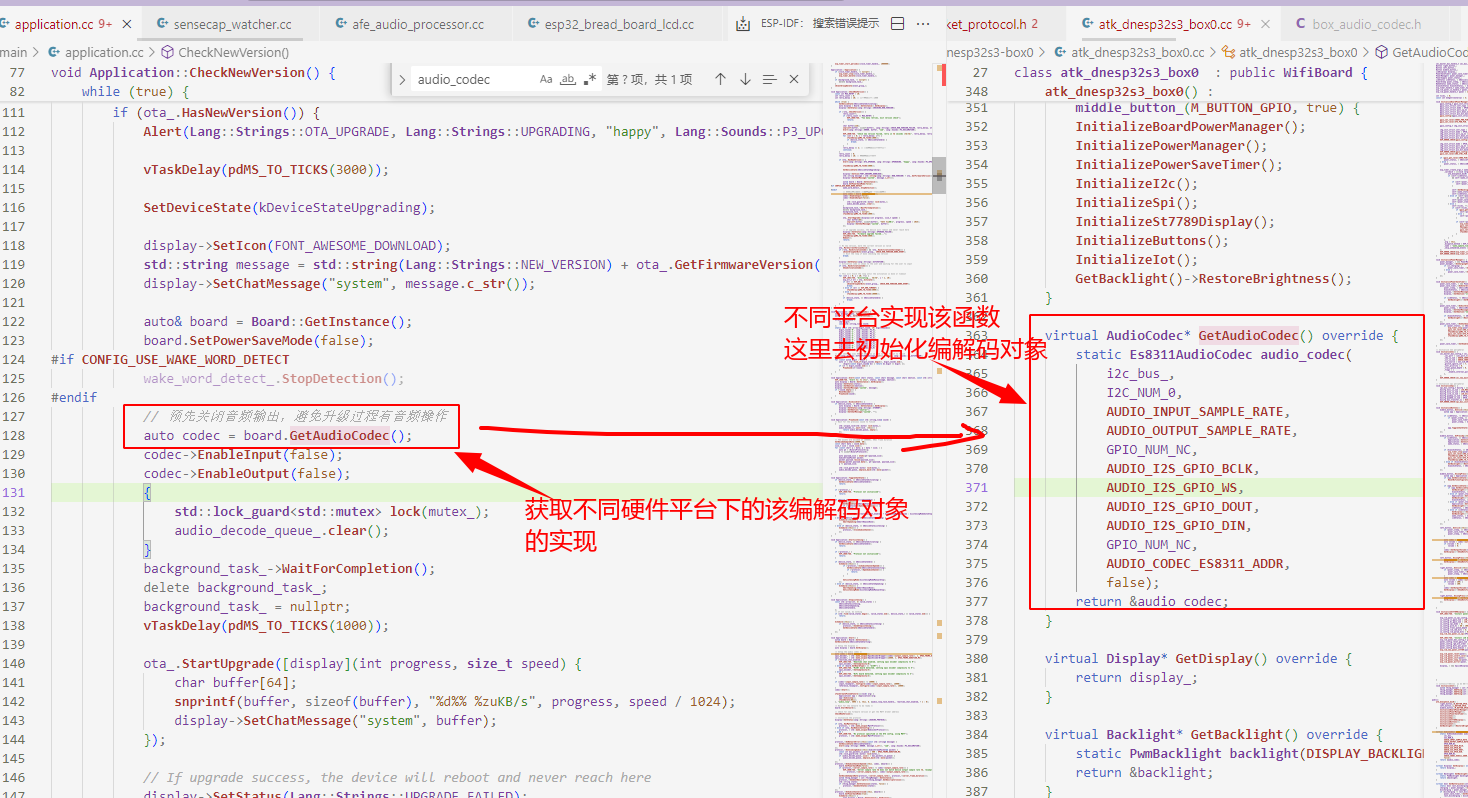
因为小智AI要适配不同的音频编解码芯片,而不同的芯片的读写和配置实现方式又不同,所以在设计时,开发者就把这些接口给抽象了出来,然后让不同的芯片进行适配时,去实现这些接口。而上层应用只需要知道audio_codec.h中所提供的接口即可,无需关心不同平台的差异化实现、
以音频数据的读写为例子
virtual int Read(int16_t* dest, int samples) override;
virtual int Write(const int16_t* data, int samples) override;
这两个函数是在private内的。
也就是说application调用接口读写编码信息时不会调用到这里,而是调用AudioCodec类的
void OutputData(std::vector<int16_t>& data);
bool InputData(std::vector<int16_t>& data);
而这两个函数内部的实现实际上是调用不同硬件平台所实现的读和写接口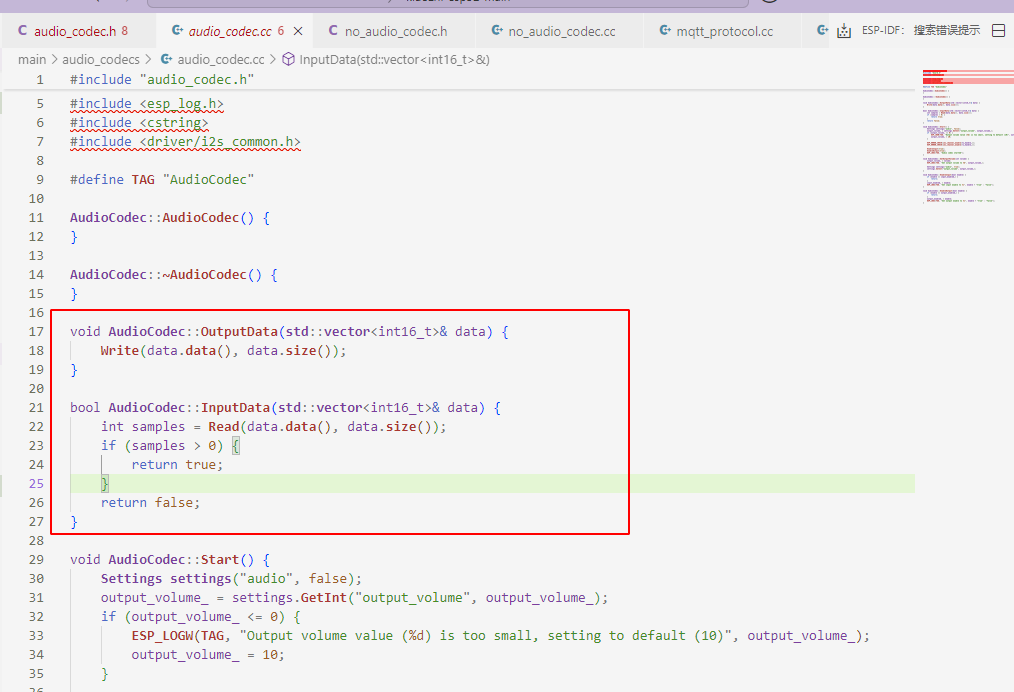
3.2 工作流程
初始化流程
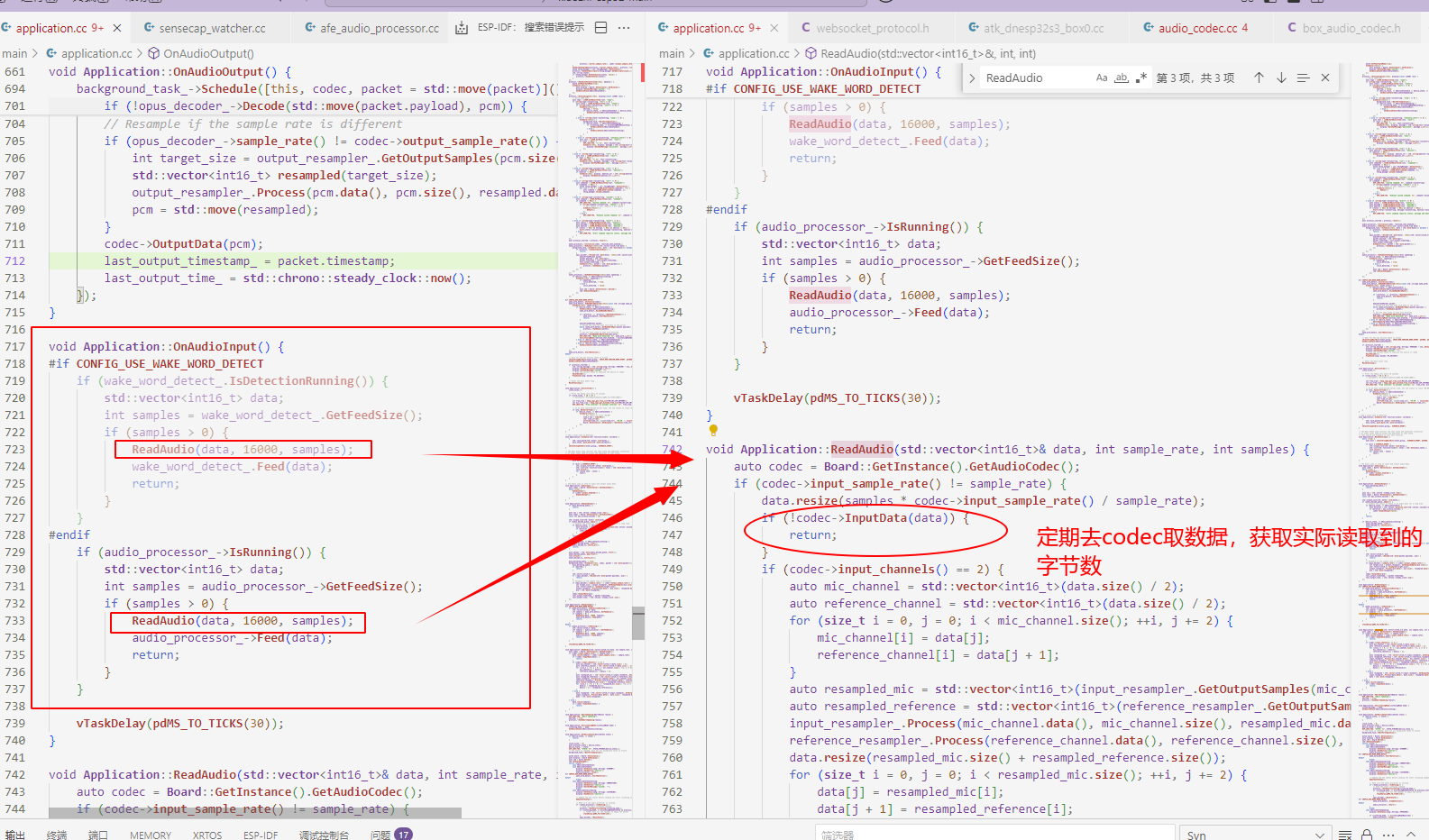
音频采集流程
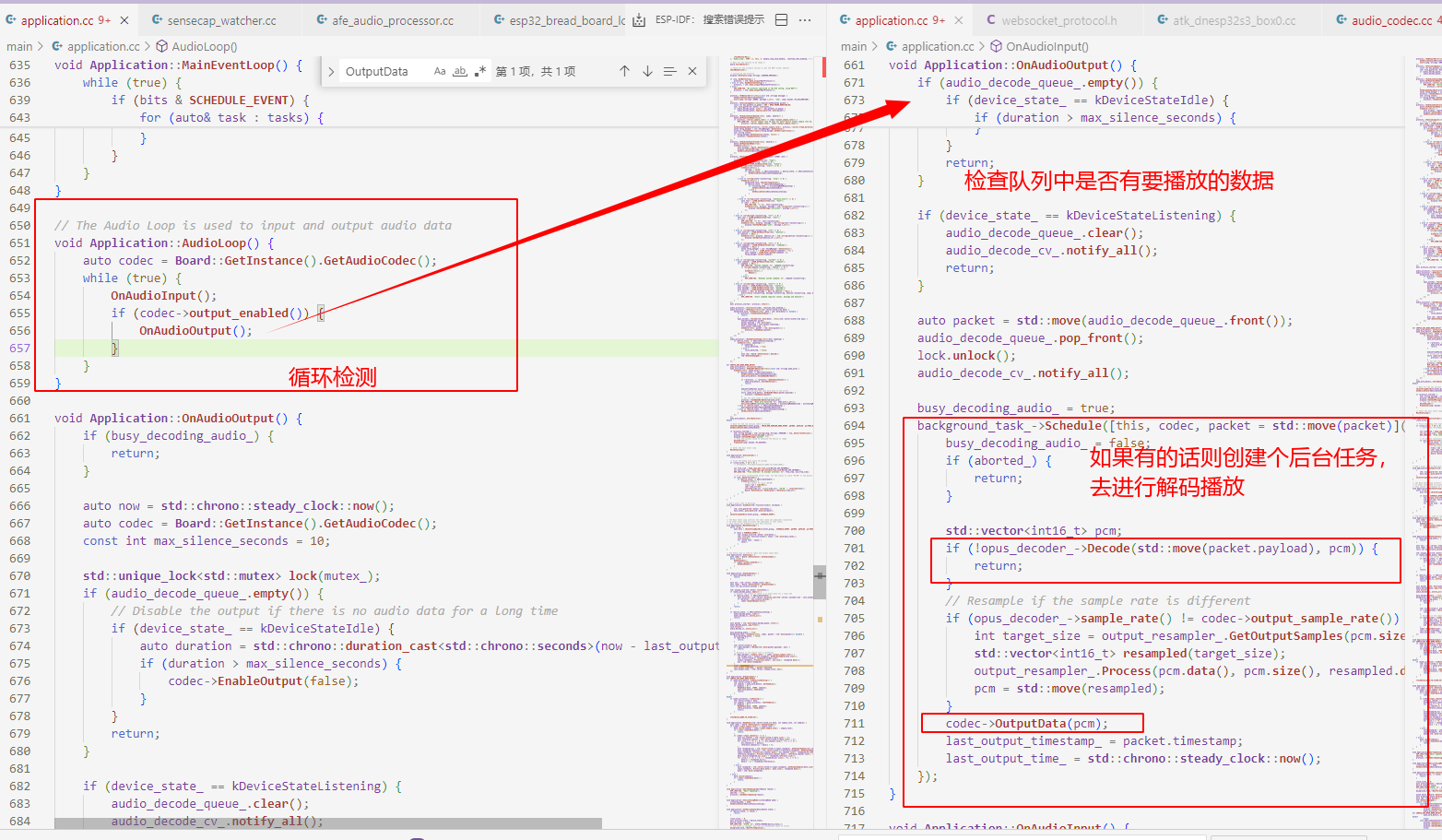
音频播放流程
4. audio_processing(音频处理)
通过音频编解码器收到音频数据后,还不能立即使用,需要通过一些算法对音频的原始数据进行处理(例如回声消除等),处理干净后再将其交给各个模型去进行使用。
audio_processing主要提供两大功能:
- 音频前端处理
- 唤醒词检测
4.1 代码基础结构
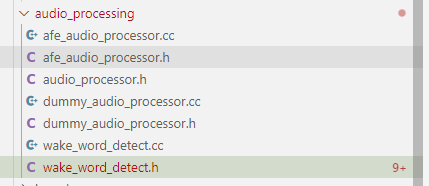
AudioProcessor抽象类
audio_processor.h中定义了音频处理器的抽象类AudioProcessor,这部分和前面的AudioCodec抽象类的作用一样,定义接口规范,让不同的处理方式去适配这套规范,可以有效的隔离变化所带来的影响。
抽象类核心接口文件
接口功能
-
核心控制接口:
- Initialize(): 初始化处理器,需要传入音频编解码器实例和实时聊天标志 - Feed(): 输入音频数据进行处理 - Start(): 启动处理器 - Stop(): 停止处理器 - IsRunning(): 检查处理器是否正在运行 -
回调设置接口:
- OnOutput(): 设置音频输出回调,处理后的数据通过此回调返回 - OnVadStateChange(): 设置语音活动检测(VAD)状态变化回调 -
辅助接口:
- GetFeedSize(): 获取每次处理所需的音频数据大小
主要实现文件
-
afe_audio_processor.h/cc: 音频前端处理器实现,实现了基于ESP AFE (Acoustic Front-End)的音频处理功能-
包含AEC/NS/AGC三大模块
-
支持多麦克风处理
-
提供硬件加速接口
-
-
dummy_audio_processor.h/cc: 空处理器实现
- 用于测试和基准比较
- 零处理延迟设计(就是透传啦)
唤醒词检测wake_word_detect.h/cc: 唤醒词检测实现,这个类主要实现了以下功能:
- 基于ESP AFE和NSN模型的唤醒词检测
- 唤醒词音频数据的采集和编码(OPUS格式)
- 检测状态管理
- 检测结果回调通知
关键特性
- 纯虚接口,需要子类实现具体处理逻辑
- 与AudioCodec配合工作
- 支持实时聊天模式
- 提供语音活动检测功能
- 采用回调机制处理输出结果
afe_audio_processor对象
class AfeAudioProcessor 继承并实现了抽象类AudioProcessor的所有接口。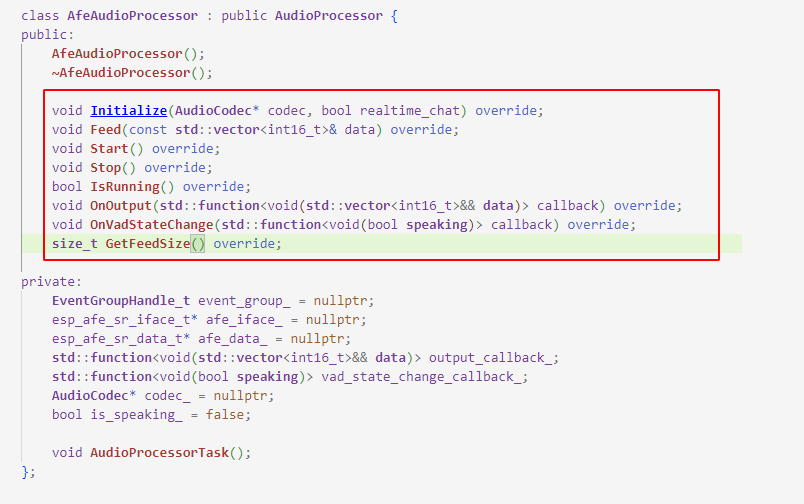
这部分和上面的audio的机制一样就不做过多的介绍了。
4.1 工作流程
音频数据处理流程
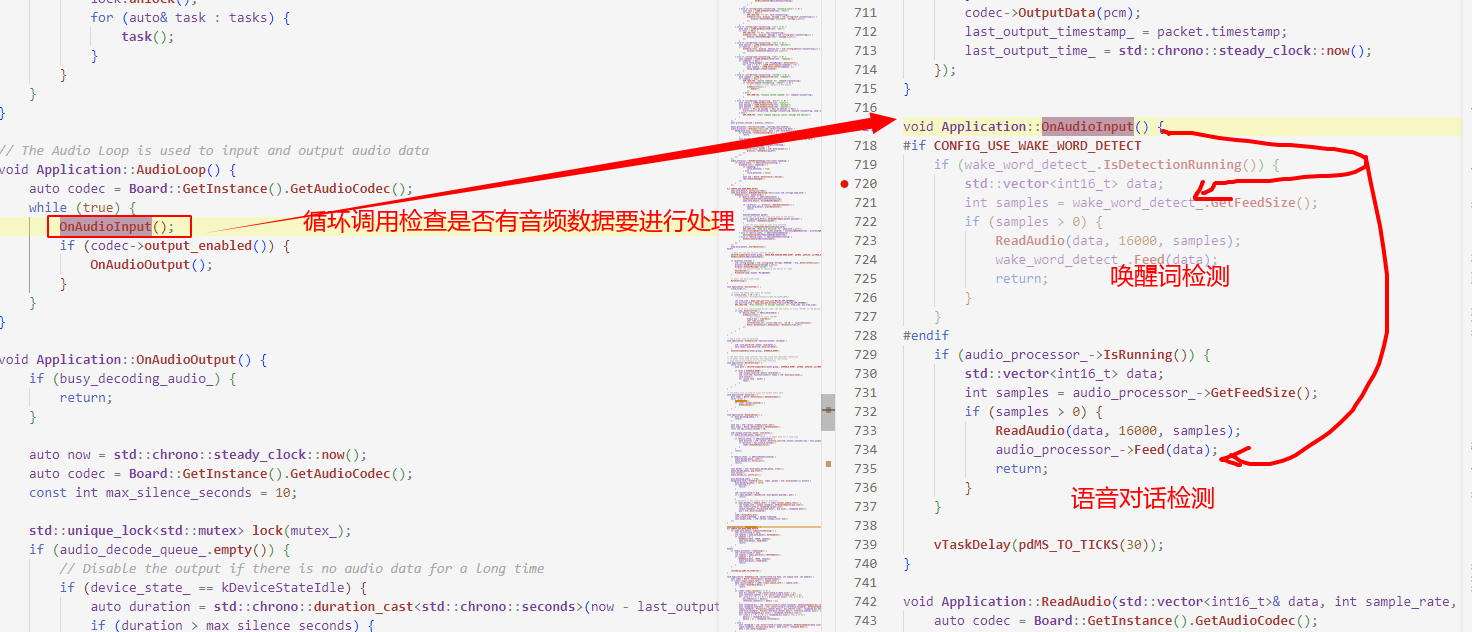
5. application(应用)
很明显application就是负责将audio_codecs 与 audio_processing 给整合起来的那个角色。
它们之间的工作流程如
│ 音频采集 │───> │ 音频处理 │───> │ 音频播放 │ │
(audio_codecs)│ │ (audio_processing)│ │ (audio_codecs)│
通常情况下aduio_codes负责硬件层音频采集或播放,采集的原始音频数据会通过audio_processor.h中的接口传递给audio_processing进行进一步的处理,等处理完成之后再交给audio_codes进行播放

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)